项目简介
到目前为止,没有其他视频生成模型能够与 Sora 的性能或其支持广泛视频生成任务的能力相匹敌。此外,目前公开发布的视频生成模型寥寥无几,大多数都是闭源的。为了填补这一空白,本文提出了一个新的多代理框架 Mora,它结合了几个先进的视觉 AI 代理,以复制 Sora 所展示的通用视频生成能力。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

Mora 能够利用多个视觉Agent,并成功模仿 Sora 在各种任务中的视频生成能力,例如 (1) 文本到视频的生成,(2) 基于文本条件的图像到视频生成,(3) 扩展生成的视频,(4) 视频到视频的编辑,(5) 连接视频以及 (6) 模拟数字世界。我们广泛的实验结果表明,Mora 在各种任务中达到了与 Sora 接近的性能。然而,在全面评估时,我们的工作与 Sora 之间存在明显的性能差距。总之,我们希望这个项目能够引导视频生成的未来发展方向,通过协作的 AI Agent来实现。

与Sora效果对比
通过对比发现,mora跟sora生成的视频是几乎一样的
·Sora
·Mora
基于Agent的视频生成
Agent的定义与专业化。Agent的定义使得将复杂工作分解成更小、更具体的任务变得更加灵活。解决不同的视频生成任务通常需要具有不同能力的Agent的合作,每个Agent都贡献出专门的输出。在这个框架中,有 5 个基本角色:提示选择与生成Agent,文本到图像生成Agent,图像到图像生成Agent,图像到视频生成Agent以及视频到视频Agent。
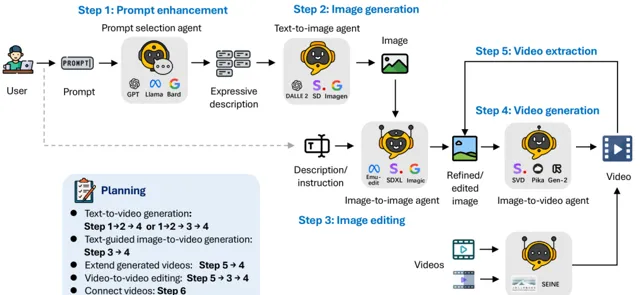
·提示选择与生成Agent :在初始图像生成开始之前,文本提示会经过严格的处理和优化阶段。这个关键Agent可以使用大型语言模型,如 GPT-4、Llama 。它旨在细致地分析文本,提取其中关键的信息和动作,从而显著增强最终图像的相关性和质量。这一步确保文本描述被充分准备,以便高效、有效地转换成视觉表现。
·文本到图像生成Agent :文本到图像模型位于将这些丰富的文本描述转换成高质量初始图像的前沿。其核心功能围绕着对复杂文本输入的深入理解和可视化,使其能够精确地创建出与提供的文本描述相匹配的详细和准确的视觉对应物。
·图像到图像生成Agent :这个Agent工作是根据特定的文本指示修改给定的源图像。它的核心功能在于能够高精度地解释详细的文本提示,并据此调整源图像。这涉及到详细识别文本的意图,将这些指令转换为从细微变更到变革性变化的视觉修改。该Agent利用预训练的模型,桥接文本描述和视觉表现之间的差距,实现新元素的无缝整合、视觉风格的调整或图像构成方面的变更。
·图像到视频生成Agent :在初始图像创建之后,视频生成模型负责将静态帧过渡到充满活力的视频序列。这一组件深入分析初始图像的内容和风格,为生成后续帧提供基础。这些帧被精心制作,以确保流畅的叙事流动,结果是一个在整个过程中保持时间稳定性和视觉一致性的连贯视频。这一过程突出了模型不仅能理解和复制初始图像,还能预测和执行场景中的逻辑进展的能力。
·视频连接Agent :利用视频到视频代理,我们基于用户提供的两个输入视频创建无缝过渡视频。这个高级Agent从每个输入视频中选择性地利用关键帧,以确保它们之间的平滑且视觉上一致的过渡。它被设计具有准确识别两个视频中共同元素和风格的能力,从而确保产出的连贯性和视觉吸引力。这种方法不仅改善了不同视频段之间的无缝流动,而且还保留了每个段落的独特风格。
每个Agent负责特定的输入和输出。这些结果可以用于不同的设计任务。
论文链接
https://arxiv.org/abs/2403.13248
关注「 开源AI项目落地 」公众号











