PART 1
点击上方 蓝字 关注我们
本文继续探讨超长上下文LLM时代的RAG应用。(上篇: )
01
超长上下文LLM下的RAG
SPRING HAS ARRIVED
当具备超长上下文的LLM横空出时候,我们当然有理由期望能够把所有的东西塞给LLM来一次生成,而忘掉诸如Split、Chunk_size、向量、索引等一系列RAG的概念,这就像扔一本百科全书给一名记忆力足够好的优秀学生:
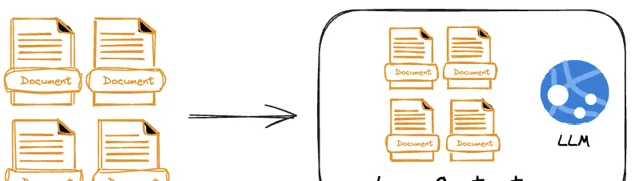
但这里的问题是,在一个超长的「百科全书」中精确的定位知识条目是需要代价的。我们在 上篇中看到了超长上下文LLM的「大海捞针」能力的系列测试,其很大程度上需要依赖于知识的位置、数量以及上下文长度,具有一定的不确定性,如果再考虑到工程上的一次性知识摄入、响应性能、tokens成本等问题,把所有的知识一股脑塞给LLM显然并不现实。
另一方面,RAG应用发展到现在,尽管更加灵活与可控,但由于其具备的工程复杂性、涉及更多的调优参数、不同的索引类型、生成模式等,都需要根据实际应用与数据特点做灵活调整,否则很容易掉进「看上去很简单,做起来很困难」的陷阱。
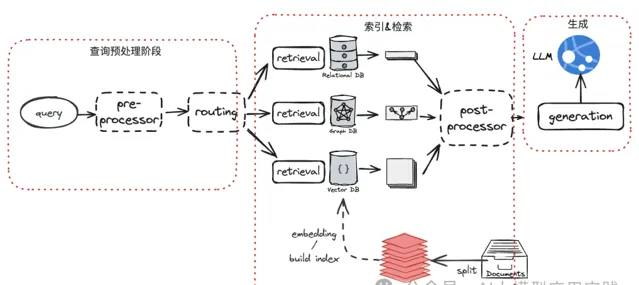
越来越复杂的RAG架构
所以更现实的问题或许是,
如何在RAG与长上下文的LLM之间取得平衡?
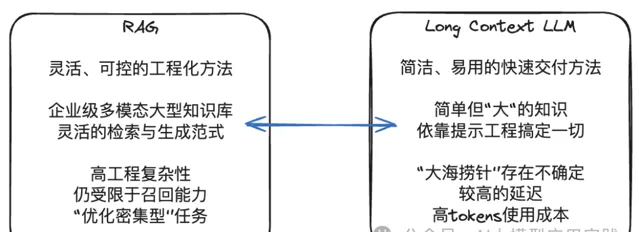
LangChain公司的Lance在最近的分享中提出了这样一种可能:
既然LLM带来了足够大的上下文窗口,那么未来的RAG或许可以 使用文档(Document)而不是文本块(Chunk)作为检索召回的最小单位,因此也不再需要分割(split)这个环节。这在超长上下文的LLM环境中或许更合理,因为大部分的文档将完全可以容纳在未来的LLM上下文窗口之中。
这样的RAG将绕过在Chunk层的拆分、索引以及精准召回的需要(这也是目前RAG中优化最复杂的部分),而是提升到在Document层。
在文档层面实现索引与召回,或许还可以解决的一个棘手问题是:目前在多模态非结构化文档内容的拆分、解析与嵌入的复杂性。
02
基于文档的索引与召回
SPRING HAS ARRIVED
如果期望在Document这个单位上去实现召回,以利用超长上下文窗口的LLM简化RAG工程,在整个流程中影响最大的显然是
索引与检索环节
。
【直接文档嵌入】
当前RAG普遍使用嵌入模型生成向量后的相似性来实现语义搜索;所以如果把这种方法直接应用到文档级别也是成立的: 将整个文档嵌入然后通过相似算法获取top_K相关文档。
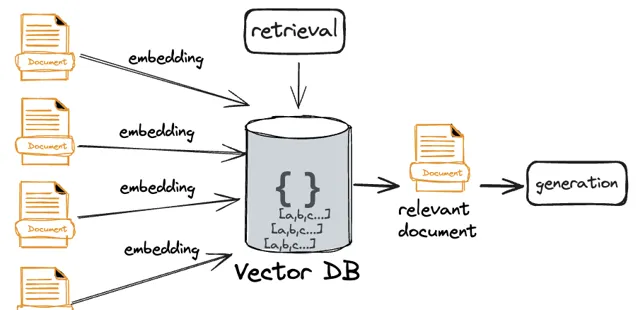
但这里的潜在问题是: 尽管试图通过向量相似来召回相关的文档,但会进一步放大召回精准性的问题。 其根源来自于一个事实: 文本向量的语义精确性与丰富性是一对矛盾体。不再经过拆分的文档尽管具有更加丰富的上下文信息,但嵌入的向量却缺乏足够的语义精准度,这在实际的检索环节可能会体现出几种可能:
你的top_K较小,可能导致你需要的文档没有被检索出来
你的top_K较大,可能也就丧失了文档检索的意义
还有一种复杂的情况是,如果输入问题需要结合多个文档中的内容回答,很难保障召回的相关文档中包含所必需的更完整的上下文
这里介绍两种可能的优化解决方案,以在一定程度上缓解这个问题:既无需分块以充分利用超长的LLM上下文能力;也能提供更精准的文档级索引与召回能力。
【摘要索引方案】
在这种方案中,通过对文档生成另外一种更适合检索的语义表示来实现。
在构建索引时 :借助LLM生成文档的摘要内容(也可以自己编写与补充针对文档的摘要提示),并对摘要内容进行嵌入,同时建立其与原始文档的链接关系
在输入检索时 :根据问题与摘要的相似性做检索,再通过链接关系获取到全部的完整原始文档
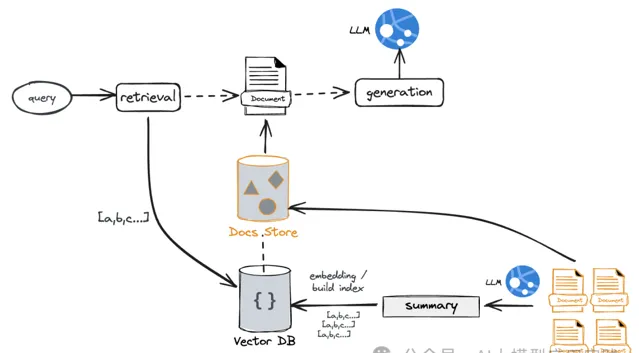
这种方案的好处是:
通过摘要生成语义更集中、更紧凑的文档表示,并基于此进行检索,具备更高的检索精准性
对于一些很长,但是内容很松散的文档,可以大大的减少其中无关信息对检索的干扰
通过关联关系,你仍然可以获取到完整的文档信息,将其组装到足够的上下文窗口进行生成
这种方案的主要挑战来自于摘要的有效性。因为摘要是嵌入与检索的对象,因此其质量决定了后续召回的质量,在实际应用中需要充分评估摘要生成使用的LLM以及Prompt,适当的人工摘要补充也是必要的。
【文档树方案(RAPTOR)】
这种方案的思想来自于一篇关于RAG检索的实验性方法的论文( RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL)。
RAPTOR本意是针对目前基于分块的向量检索限制了对上下文的整体信息获取与理解,从而采用了一种构造「从上至下不同级别的摘要树「的优化方法(试想下,很多问题是需要对整个甚至多个文档知识进行理解后才能回答,仅有top_K的分块是不够的)。
这里尝试把RAPTOR的思想应用到基于文档的检索方案中:
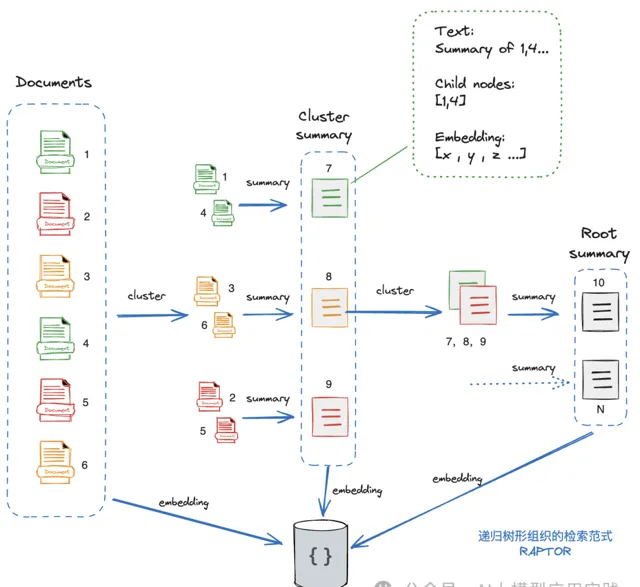
基本的思想是:从基础节点开始(Leaf Nodes,在这里就是原始文档,比如这里有6个),对这些文档做嵌入并生成向量表示;然后对这些文档进行聚类(通过聚类算法,这里分成了3组),可以简单的理解成把「相关」的文档进行智能分组;然后对每个分组文档生成摘要Summary,然后可以把生成的摘要看成一组具备更高抽象与语义的文档(即3个新的摘要文档);然后递归执行前面的操作(embedding->cluster->summary),直到没有新的聚类产生。
最后,就完成了一棵完整的文档树。在这个图中可以看到,这里的文档树由从1到10共10个文档组成,其中1-6是原始文档,7-9是中间层文档,10是根级文档(不一定只有一个根文档),可以把
高层的文档理解成是低层若干个文档的精简版
。同时,
所有这些文档的embedding向量信息会被存储到向量库。
RAPTOR方案在检索时有两种方式:
一种是树遍历检索:
从根级节点开始,基于向量相似性与父子关系,进行逐层向下检索,最后检索出全部相关的节点文档,作为最终输出的相关文档。
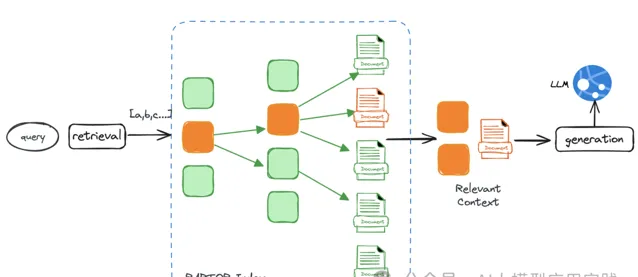
另外一种是直接全量检索: 将树展开单层,然后直接对所有文档节点进行向量相似性检索,检索出所有的相关节点文档。这种方式更快速且不会遗漏。

RAPTOR方案的好处是:
在不同层次的多个级别上构建了语义表示并实施嵌入,提高了检索的召回能力
可以有效且高效的回答不同层次的问题,有的问题在低阶节点解决,有的则由高阶节点来完成
适合需要多个文档的理解才能回答的输入问题,因此对于综合性的问题有更好的支持
RAPOR还是一种实验性的方案,感兴趣的可以研究其公开的论文与代码。
03
生成阶段:进一步完善
SPRING HAS ARRIVED
相对于索引与召回阶段,我们相信响应生成环节在更长的上下文空间下并不会有太多的本质变化。超长上下文的LLM对生成阶段带来的积极意义有:
由于窗口的增加,可以携带更丰富的内容与语义交给LLM,幻觉的概率可以进一步降低
更长的上下文有利于回答更多类型的问题以及更细节的输出,比如回答基于全文与高层语义理解的问题
简化了开发与调优过程。在上下文空间受限条件下需要精确的对窗口内的tokens进行控制的需求会降低
事情总有两面性,就像RAG中的chunk_size大小一样。超长上下文带来的消极一面是
干扰与噪音也更多了
,在检索环节如果召回的文档缺乏足够的精度,或者受到关联知识在上下文中的位置影响,以及LLM对超长上下文理解的一些偏差现象,仍然可能导致生成质量的下降。
当然,RAG发展到现在,生成环节也 已经不再是丢给LLM一个巨大的上下文然后要求它回答问题。 在这个环节已经有很多成熟的模式, 甚至一些复杂的工作流范式。比如通过多个召回知识进行迭代Refine的模式、自我纠正并借助外部搜索的C-RAG模式、自省式的Self-RAG等。
以之前介绍过的Self-RAG为基础,在超长上下文与以文档为单位做召回的背景下,我们设计一个改进的的RAG范式如下图:
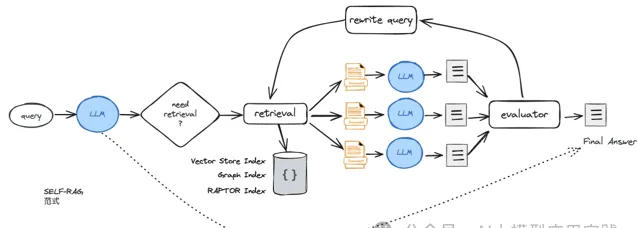
在这个范式里,召回多个document以后,会进行多次生成,然后对生成结果的质量进行反思、评估并「择优录用」;如果无法获得满意的评估结果,则在Rewrite后重新召回新的文档进行生成,直到满足评估要求或者达到迭代次数的限制。
Self-RAG的范式在框架LlamaIndex与Langchain中都有一个实现,但两者有较大的区别。LlamaIndex的实现更贴近原论文的实现,但依赖于微调模型;LangChain则基于自身的LangGraph做改进与构建,无需依赖于微调模型。
04
结束语
SPRING HAS ARRIVED
以上就是我们对超长上下文的LLM背景下,RAG应用的共存以及变化的一些粗浅思考与分析,这里结合了一些来自诸如LangChain、LlamaIndex开发框架的观点以及一些实验性的项目,后续还将对其中的一些方案做实际论证与测试。
无论怎样,一个能够容纳更多上下文的LLM窗口会让应用有着更加游刃有余的空间,但指望LLM解决所有的问题无疑也是不现实的,如何在LLM与RAG方案两者之间取长补短,并达到1+1>2的效果才是在后续工程中最应该去探讨与实现的问题。
END
点击下方关注我,不迷路
交流请识别以下名片并说明来源











