1 引言
2 LiteFlow简介
2.1 引入jar包
2.2 定义组件
2.3 执行流程
2.4 官网
3 可视化编排(形态进阶)
3.1 为什么要可视化
3.2 方案设计
3.3 推拉结合刷新流程
3.4 源码
4 效果收益&未来规划
4.1 效果收益
4.2 未来规划
1 引言
LiteFlow解决哪些场景的问题呢?通过下面的例子感受一下。
假设有三个组件(或方法)stepOne、stepTwo、stepThree,并且你想要按照顺序打印"one"、"two"、"three",通常我们编写代码的方式可能是这样的:
@Component
public classPrintService{
/**
* 执行业务代码
*/
privatevoiddoExecute(){
stepOne();
stepTwo();
stepThree();
}
privatevoidstepOne(){
// 业务代码
System.out.println("one");
}
privatevoidstepTwo(){
// 业务代码
System.out.println("two");
}
privatevoidstepThree(){
// 业务代码
System.out.println("three");
}
}
这样写最简单粗暴,但是如果之后有调整打印顺序的话,例如你想打印two、one、three,或者直接跳过two直接打印one、three,你一定需要修改代码并且重新上线。
// 打印two、one、three
publicvoiddoExecute(){
stepTwo();
stepOne();
stepThree();
}
// 打印one、three
publicvoiddoExecute(){
stepOne();
stepThree();
}
对于需要动态调整执行流程的业务场景,显然不适合将流程硬编码在代码中。
2 LiteFlow简介
LiteFlow是一款编排式的规则引擎框架,可以通过表达式的方式来编排组件或方法的执行流程,并且支持一些高级的流程编排。
上述案例如何通过更高级的方式来实现零代码修改、无需重新上线即可编排流程了呢?我们基于LiteFlow做一些改造。
2.1 引入jar包
可以去官网根据需要选择合适的版本,这里用的是最新版本
<dependency>
<groupId>com.yomahub</groupId>
<artifactId>liteflow-spring-boot-starter</artifactId>
<version>2.12.0</version>
</dependency>
2.2 定义组件
将打印功能分别定义成一个个组件,继承NodeComponent 这个抽象父类并实现其中的方法:
@Component
public classPrintOneextendsNodeComponent{
@Override
publicvoidprocess()throws Exception {
// 业务代码
System.out.println("one");
}
}
@Component
public classPrintTwoextendsNodeComponent{
@Override
publicvoidprocess()throws Exception {
// 业务代码
System.out.println("two");
}
}
@Component
public classPrintThreeextendsNodeComponent{
@Override
publicvoidprocess()throws Exception {
// 业务代码
System.out.println("three");
}
}
2.3 执行流程
定义好组件之后,我们就开始编写组件执行的流程表达式了,官方名称叫EL表达式;上述案例可以这样编写表达式:
THEN(node("printOne"),node("printTwo"),node("pirntThree"));
并给这个流程起个名字(流程唯一标识):print_flow
根据流程名称执行流程:
@Component
public classPrintService{
@Autowired
private FlowExecutor flowExecutor;
/**
* 执行业务代码
*/
publicvoiddoExecute(){
// 开始执行流程
LiteflowResponse response = flowExecutor.execute2Resp("print_flow");
// 根据执行结果进行后续操作
// ......
}
}
一般我们会将流程放到数据库中,如果想改变打印顺序,只需要修改表达式即可,例如:打印two、one、three。
THEN(node("printTwo"),node("printOne"),node("pirntThree"));
打印two、three。
THEN(node("printTwo"),node("printThree"));
然后LiteFlow真正强大的地方远不止如此,它不仅仅支持简单的串行编排,还支持更加复杂的逻辑例如(并行编排) WHEN 、(条件编排) IF 、(选择编排) SWITCH 、(循环编排) FOR 等。
2.4 官网
上述的简单示例旨在为不熟悉LiteFlow框架的伙伴们提供一个初步的认知。要想真正基于LiteFlow将业务流程落地并运用到实际业务场景中,还需要通过官方文档深入了解该框架的运作原理和核心机制。
https://liteflow.cc/
3 可视化编排(形态进阶)
3.1 为什么要可视化
官网提供修改表达式的方式只有一个,那就是手写!官网并没有提供配套的可视化工具,手写可能存在诸多问题和不便,例如:
容易出错:表达式少一个字母甚至一个逗号都不行!
流程不可视:我们只能完全依赖大脑去构想这些流程,运营或产品团队想要了解或讨论流程,也只能依赖于其他画图工具来手动绘制和表达。
节点不可配置:我们的运营会根据不同的场景对节点进行动态配置,没有可视化界面,运营改动配置的需求则无从下手。
所以可视化对于编排流程来说意义重大,对于研发能更准确地理解和设计流程,还能让运营能更便捷地监控和管理流程。
3.2 方案设计
网上有一些网友开源的项目,但基本都是个人维护,对于复杂流程的处理不是很好,质量也参差不齐,所以自己进行了调研和设计;支持普通节点、判断节点、选择节点、并行节点;循环节点目前业务不需要,有需要的可以自己拓展,掌握方案之后拓展节点类型非常简单。完成可视化编排需要解决两个问题:
一款与用户交互的前端画布(推荐logicFlow,有自己熟悉的也行)
将画布数据转化成EL表达式(手写算法,基于DFS的递归)
这里重点讲画布数据转化为EL的过程。
3.2.1 整体流程
创建流程
流程的核心在第5步,下面会重点讲解。
回显流程
解析EL成本很高,所以我选择不解析表达式,直接将前端传入的画布json数据返回给前端进行回显。
3.2.2 后端抽象语法树设计
节点类型枚举
publicenum NodeEnum {
// 普通节点,对应普通组件
COMMON,
// 并行节点,对应并行组件
WHEN,
// 判断节点,对应判断组件
IF,
// 选择节点,对应选择组件
SWITCH,
// 汇总节点(自定义)
SUMMARY,
// 开始节点(自定义)
START,
// 结束节点(自定义)
END;
}
COMMON
普通节点,入度和出度都为1。
IF
判断节点,包含一个true分支,一个false分支,入度为1,出度为2。
SWITCH
根据SWITCH返回的tag,来决定执行后续哪个流程。入度为1,出度大于1。

WHEN
官网没有WHEN节点的概念,我这里自定义WHEN节点会避免很多问题。
为什么要定义WHEN节点?
WHEN作为一个出度大于1的节点,和IF、SWITCH不同的是WHEN并没有一个前置节点去驱动一个流程。
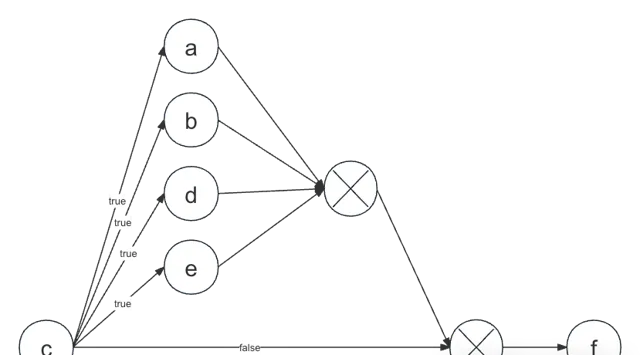
假设这样一个流程,如果没有WHEN节点的支持,展示到画布上的效果很差。
THEN(
IF(node("c"),
WHEN(
node("a"),
node("b"),
node("d"),
node("e")
).ignoreError(true)
),
node("f")
)
SUMMARY
官网没有这种节点,自定义节点,用于汇总所有分支节点,也就是WHEN、IF、SWITCH节点。入度大于1,出度为1。

为什么要定义SUMMARY节点?
构建EL算法是基于递归实现的,参考的是深度优先遍历算法(DFS),这种嵌套方式如果没有一个结束标志会一直执行下去。
举个例子:
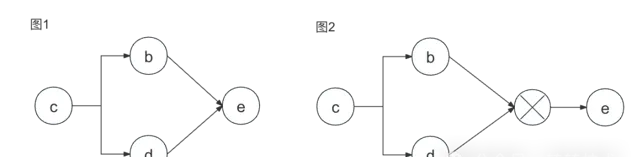
基于图1生成EL表达式
THEN(
node("c"),
WHEN(
THEN(node("b"),node("e")),
THEN(node("d"),node("e"))
)
)
基于图2生成EL表达式
THEN(
node("c"),
WHEN(node("b"),node("d")),
node("e")
)
可以看出来图2的EL表达式才是我们想要的。
市面上有名的工作流引擎在画布上处理汇总问题也是这样设计的,比如在activiti中使用并行网关开启会签,也必须用并行网关在会签结束时进行汇总,否则就会出现重复审批的问题。
START
开始节点,一个流程必须有一个开始节点,入度为0,出度为1。
END
结束节点,一个流程必须有一个结束节点,入度为1,出度为0。
上述节点类型的类定义
// 抽象父类
@Getter
publicabstract classNode{
// node的唯一id
privatefinal String id;
// node名称,对应LiteFlow的Bean名称
privatefinal String name;
// 入度
privatefinal List<Node> pre = Lists.newArrayList();
// 节点类型
privatefinal NodeEnum nodeEnum;
// 出度
privatefinal List<Node> next = Lists.newArrayList();
protectedNode(String id, String name, NodeEnum nodeEnum){
this.id = id;
this.name = name;
this.nodeEnum = nodeEnum;
}
publicvoidaddNextNode(Node node){
next.add(node);
}
publicvoidaddPreNode(Node preNode){
pre.add(preNode);
}
}
// 普通节点
public classCommonNodeextendsNode{
publicCommonNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.COMMON);
}
}
// 并行节点
public classWhenNodeextendsNode{
publicWhenNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.WHEN);
}
}
// 判断节点
@Getter
public classIfNodeextendsNode{
private Node trueNode;
private Node falseNode;
publicIfNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.IF);
}
publicvoidsetTrueNode(Node trueNode){
this.trueNode = trueNode;
super.addNextNode(trueNode);
}
publicvoidsetFalseNode(Node falseNode){
this.falseNode = falseNode;
super.addNextNode(falseNode);
}
}
// 选择节点
@Getter
public classSwitchNodeextendsNode{
privatefinal Map<Node, String> nodeTagMap = Maps.newHashMap();
publicSwitchNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.SWITCH);
}
publicvoidputNodeTag(Node node, String tag){
nodeTagMap.put(node, tag);
super.addNextNode(node);
}
}
// 开始节点
public classStartNodeextendsNode{
publicStartNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.START);
}
}
// 结束节点
public classEndNodeextendsNode{
publicEndNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.END);
}
}
// 汇总节点
public classSummaryNodeextendsNode{
publicSummaryNode(@NonNull String id, @NonNull String name){
super(id, name, NodeEnum.SUMMARY);
}
}
3.2.3 画布JSON数据设计
画布数据最终体现在JSON语法树,数据结构如下:
{
"nodeEntities": [
{
"id": "节点的唯一id,由前端生成。必填",
"name": "节点名称,对应LiteFlow的节点名称,spring的beanName。必填",
"label": "前端节点展示名称,到时候给前端。必填",
"nodeType": "节点的类型,有COMMON、IF、SWITCH、WHEN、START、END和SUMMARY。必填",
"x": "x坐标。必填",
"y": "y坐标。必填"
}
],
"nodeEdges": [
{
"source": "源节点。必填",
"target": "目标节点。必填",
"ifNodeFlag": "if类型节点的true和false,只有ifNode时必填,其他node随意",
"tag": "switch类型的下层节点的tag,主机有switchNode时必填,其他node随意"
}
]
}
用户拖动画布节点和节点之间连线的过程,其实就是维护节点数组和边数组的过程。
3.2.4 画布JSON数据合法校验
下面是针对画布json数据的一些简单合法性校验,可以自己根据需要拓展,实现很简单,最后有具体实现代码,需要的可以下载。
流程必须有一个开始节点和一个结束节点
校验节点类型,只能是IF、WHEN、COMMON、SWITCH、START、END和SUMMARY
IF、WHEN、SWITCH节点的数量总和与SUMMARY类型节点数量总和校验
校验节点和边的source和target是否能对应上
校验SWITCH的出度边是否有tag,且tag不能为空
校验IF节点有没有ifNodeFlag的标识,并且总有一条true分支,总有一条false分支
3.2.5 画布JSON数据转化为抽象语法树
举个简单的例子:
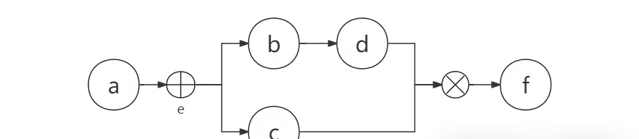
{
"nodeEntities": [
{
"id": "a",
"label": "a",
"nodeType": "COMMON"
},
{
"id": "e",
"label": "e",
"nodeType": "WHEN"
},
{
"id": "b",
"label": "b",
"nodeType": "COMMON"
},
......
],
"nodeEdges": [
{
"source": "a",
"target": "e",
},
{
"source": "e",
"target": "b",
},
{
"source": "e",
"target": "c",
},
......
]
}
JSON转化为抽象语法树,实际就是创建节点对象,并维护节点的属性,下面是伪代码。
// 创建节点对象
List<Node> nodes = Lists.newArrayList();
for (NodeEntity nodeEntity : nodeEntities) {
Node node = null;
switch (nodeEntity.getNodeType()) {
case NodeEnum.COMMON;
node = new CommonNode("节点的id", "节点的label");
break;
case NodeEnum.WHEN;
node = new WhenNode("节点的id", "节点的label");
break;
case NodeEnum.SUMMARY;
node = new SummaryNode("节点的id", "节点的label");
break;
default:
thrownew RuntimeException("未知的节点类型!");
}
nodes.add(node);
}
// 构建nodeId和node的map
Map<String, Node> nodeIdAndNodeMap = nodes.stream()
.collect(Collectors.toMap(Node::getId, Function.identity()));
// 维护节点间关系
for (NodeEdge nodeEdge : nodeEdges) {
Node sourceNode = nodeIdAndNodeMap.get(nodeEdge.getSource());
Node targetNode = nodeIdAndNodeMap.get(nodeEdge.getTarget());
sourceNode.addNextNode(targetNode);
targetNode.addPreNode(sourceNode);
......
}
疑问:为什么要设计JSON和AST(抽象语法树)两种数据结构?
根据上述JSON数据可以发现,用户编辑画布时,前端只需要维护节点和边两个数组即可;而生成EL表达式的操作在后端,生成方法是利用 递归 实现的 深度优先遍历算法(DFS ) ,显然JSON是不满足递归需求的,所以JSON转换为AST。
总之设计JSON和AST就是为了方便前后端去各自维护数据。
3.2.6 抽象语法树生成EL表达式
整个流程的核心就在这里,AST生成EL表达式
同样用上面的例子来模拟生成EL表达式过程,该流程只涉及THEN和WHEN,我们约定把THEN和WHEN当成数组来处理,例如
THEN(node("a"),node("b"))
对应数组
[node("a"),node("b")]
,同理WHEN。
流程必须以一个数组开始。
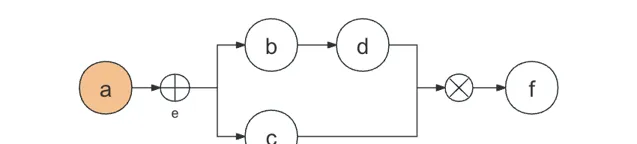
[
node("a")
]
遇见WHEN分支节点e,创建一个新数组,并加入上一层数组。
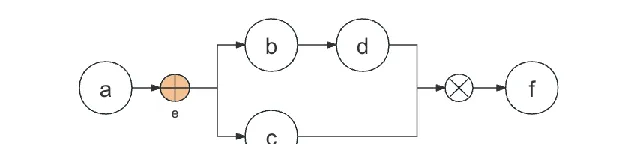
[
node("a"),
[
]
]
分支节点之后的每一个分支都要创建一个数组,并且加入到分支节点的数组中。

[
node("a"),
[
[
node("b")
]
]
]
正常的串行,节点直接加入最内层数组。
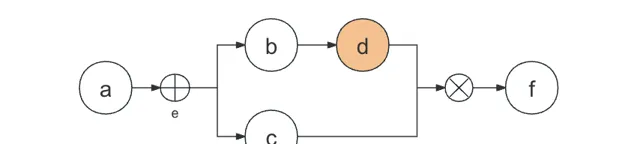
[
node("a"),
[
[
node("b"),
node("d")
]
]
]
遇见汇总节点,什么也不处理。
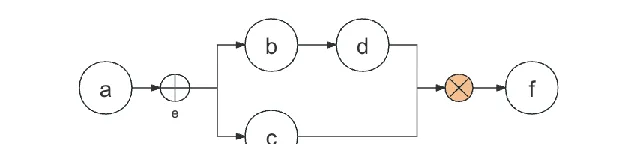
[
node("a"),
[
[
node("b"),
node("d")
]
]
]
继续向下,将f节点加入WHEN节点所在的数组,到达递归的出口。

[
node("a"),
[
[
node("b"),
node("d")
]
],
node("f")
]
这可能有疑问,程序是如何定位到WHEN所在的数组在哪呢?
利用栈,遇到WHEN节点的时候会将WHEN节点所在的数组压栈,等遇到汇总节点时将数组出栈,那么可以确定f节点应该加入出栈时的数组了。
因为是从e节点开始有分支流程的,以b节点开头的分支已经执行完,回溯到另一条分支;同样c节点属于e的一条分支,分支节点之后的每一个分支都要创建一个数组,并且加入到分支节点的数组中。
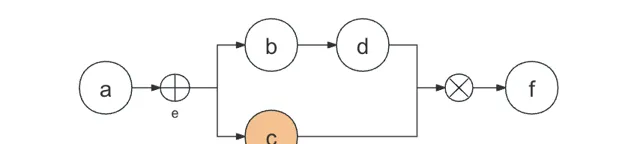
[
node("a"),
[
[
node("b"),
node("d")
],
[
node("c")
]
],
node("f")
]
到了汇总节点,因为遍历以b节点开头的分支时已经访问了该汇总节点,这次不处理,到达递归的出口。
[
node("a"),
[
[
node("b"),
node("d")
],
[
node("c")
]
],
node("f")
]
如何判断汇总节点是否访问过?
用Set,访问过的汇总节点加入Set中,下次再访问先判断Set中有没有该汇总节点,有就不往下执行,到达递归出口。
结束!
根据上面简单示例,下面是用 递归 实现 DFS 的伪代码;文末有全量源码,感兴趣的可以下载参考一下。
publicstatic String ast2El(Node head){
if (head == null) {
returnnull;
}
// 用于存放when节点List
Deque<List> stack = new ArrayDeque<>();
// 用于标记是否处理过summary节点了
Set<String> doneSummary = Sets.newHashSet();
List list = tree2El(head, new ArrayList(), stack, doneSummary);
// 将list生成EL,你可以认为框架有对应的方法
return toEL(list);
}
privatestatic List tree2El(Node currentNode,
List currentThenList,
Deque<List> stack,
Set<String> doneSummary){
switch (currentNode.getNodeEnum()) {
case COMMON:
currentThenList.add(currentNode.getId());
for (Node nextNode : currentNode.getNext()) {
tree2El(nextNode, currentThenList, stack, doneSummary);
}
case WHEN:
stack.push(currentThenList);
List whenELList = new ArrayList<>();
currentThenList.add(whenELList);
for (Node nextNode : currentNode.getNext()) {
List thenELList = new ArrayList<>();
whenELList.add(thenELList);
tree2El(nextNode, thenELList, stack, doneSummary);
}
case SUMMARY:
if (!doneSummary.contains(currentNode.getId())) {
doneSummary.add(currentNode.getId());
// 这种节点只有0个或者1个nextNode
for (Node nextNode : currentNode.getNext()) {
tree2El(nextNode, stack.pop(), stack, doneSummary);
}
}
default:
thrownew RuntimeException("未知的节点类型!");
}
return currentThenList;
}
3.2.7 校验EL表达式的合法性
这是生成EL表达式的最后一步;框架有本身有支持校验EL合法性的方法,在生成EL之后进行校验。
// 校验是否符合EL语法
Boolean isValid = LiteFlowChainELBuilder.validate(el);
进行完最后一步,EL表达式就可以入库了。
3.3 推拉结合刷新流程
流程入库之后并不是立即生效,进行以下操作后生效。
3.3.1 拉
框架会定期从数据库(或通过配置指定的任何数据源)中同步最新流程,并将这些流程缓存在内存中;新流程同步和缓存的过程是平滑进行的,不会干扰或打断现有流程的执行;该框架还允许用户根据实际需求配置数据刷新的时间间隔(默认1分钟),具体配置方法可参照官方文档进行详细了解。
3.3.2 推
如果我们希望改动的EL表达式立即生效而不是等待框架被动刷新,我们可以通过官方提供的api进行主动刷新:
flowExecutor.reloadRule();
需要注意的的是,官方提供的方法只是刷新单个实例节点的流程;如果是集群环境,我们需要借助消息队列以达到通知整个集群的效果。
3.4 源码
目前这套设计方案已在实际业务场景落地并使用;自己进行过很多复杂流程的验证,基于这种规则能百分百保证生成EL表达式的正确性。

自己的写的demo,可以借鉴一下思路;里面有一个构造好的复杂流程案例,通过调接口的方式自己感受。
https://dl.zhuanstatic.com/fecommon/liteFlow-el.zip
4 效果收益&未来规划
通过引入流程的可视化编排,结合LiteFlow框架的支持,显著提升了流程设计的直观性和开发效率,为项目带来了更为顺畅和高效的开发体验。
4.1 效果收益:
开发人员只需要专注于核心的业务流程设计,而无需在语法规则上耗费过多精力。
通过直观的可视化流程界面,产品和研发团队之间的沟通变得更为高效,复杂的业务逻辑能够清晰展现,避免了不必要的沟通。
运营能够实时编辑流程节点,并快速了解节点的属性配置;例如「黑名单校验」节点中配置了哪些用户,从而更加灵活地管理业务流程。
4.2 未来规划
痛点 :
流程编排只是针对现有节点,对于新的业务节点,依然需要开发。
对外提供服务可能需要调用方提供较为详尽的参数信息。
规划 :
希望未来借助动态脚本,实现全新业务流程的快速搭建,无需进行任何开发工作。
引入数据字典的概念,将常用的参数整合为数据字典,例如只需要一个订单号,便能根据数据字典获取该流程想要的参数,从而降低调用方的开发成本。
关于作者
蒋韬,转转回收技术部的后端工程师
IT交流群
组建了程序员,架构师,IT从业者交流群,以
交流技术
、
职位内推
、
行业探讨
为主

加小编 好友 ,备注"加群"











