项目简介
Snowflake Arctic 是一款专为企业级智能设计的语言模型,通过极高的训练效率和开放性推动成本效益的新标准。它采用了独特的密集型和MoE混合变换架构,让企业用户可以以较低成本创建高质量定制模型。此外,Arctic 项目不仅开源了模型权重和代码,还提供了完整的数据配方和研究洞见,真正实现了开放协作,推动了社区的集体学习和进步。
想要得到更多技术支持和交流
扫码添加以下微信进入技术交流群
更多技术大咖在这等你

特点
这是一个面向企业的顶级大型语言模型(LLM),推动了成本效益训练和开放性的前沿。Arctic 在智能效率和真正的开放性上都表现出色。
智能效率 :Arctic 在企业任务上表现出色,如 SQL 生成、编程和指令跟随基准测试,即便与使用显著更高计算预算的开源模型相比也是如此。事实上,它为成本效益训练设定了新的基准,使 Snowflake 的客户能够以低成本为他们的企业需求创建高质量的定制模型。
真正的开放 :Apache 2.0 许可证提供了对权重和代码的无门槛访问。此外,还将开放所有的数据集和研究洞见。
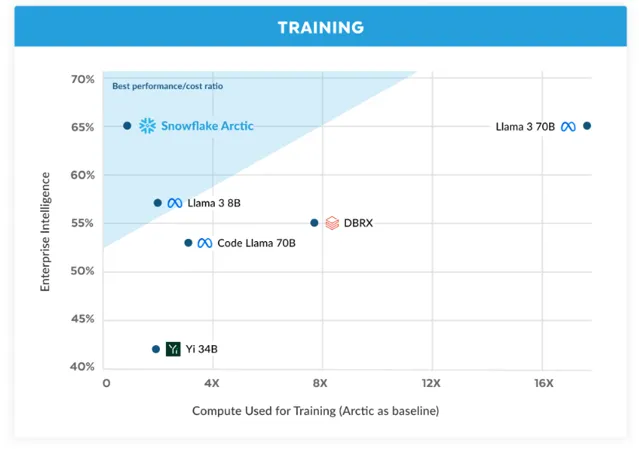
以极低的训练成本提供顶级企业智能
在 Snowflake,从企业客户那里看到了一种一致的 AI 需求和使用案例模式。企业希望利用大型语言模型(LLMs)来构建对话式 SQL 数据副驾驶、代码副驾驶和 RAG 聊天机器人。从指标角度看,这意味着在 SQL、编程、复杂指令跟随以及产生有根据的答案方面表现出色的 LLMs。通过取编程(HumanEval+ 和 MBPP+)、SQL 生成(Spider)和指令跟随(IFEval)的平均值,将这些能力汇总成一个我们称之为企业智能的单一指标。
Arctic 在开源大型语言模型中提供顶级企业智能,并且使用的训练计算预算大约在200万美元以下。这意味着 Arctic 比使用类似计算预算的其他开源模型更有能力。更重要的是,它在企业智能方面表现出色,即使与那些使用显著更高计算预算训练的模型相比也是如此。Arctic 的高训练效率还意味着 Snowflake 客户和广大 AI 社区可以以更加经济的方式训练定制模型。
如图1所示,Arctic 在企业指标上与 LLAMA 3 8B 和 LLAMA 2 70B 不相上下,甚至更好,同时使用的训练计算预算不到一半。同样,尽管使用的计算预算比 Llama3 70B 少17倍,Arctic 在企业指标如编程(HumanEval+ 和 MBPP+)、SQL(Spider)和指令跟随(IFEval)上表现不相上下。它在整体性能上仍保持竞争力。例如,尽管使用的计算比 DBRX 少7倍,但在语言理解和推理(11个指标的集合)上仍具有竞争力,同时在数学(GSM8K)方面表现更好。

训练效率
为了达到这种训练效率,Arctic 使用了一种独特的 Dense-MoE Hybrid transformer 架构。它结合了一个10B 的密集型变换器模型和一个剩余的128×3.66B MoE MLP,总计480B 参数,通过 top-2 门控选择了17B 活跃参数。它的设计和训练基于以下三个关键见解和创新:
1.多但精简的专家与更多的专家选择 :在2021年末,DeepSpeed 团队展示了 MoE 可以应用于自回归大型语言模型,显著提升模型质量而不增加计算成本。
在设计 Arctic 的过程中,基于上述发现,模型质量的提升主要取决于 MoE 模型中的专家数量、专家总参数量以及这些专家组合的方式。
基于这一见解,Arctic 被设计为拥有480B 参数,这些参数分布在128个精细的专家之间,并使用 top-2 门控来选择17B 活跃参数。相比之下,最近的 MoE 模型构建时使用的专家数量显著少,如表2所示。直观地说,Arctic 利用大量的总参数和众多的专家来扩大模型容量,实现顶级智能,同时它精心选择多但精简的专家,并运用适度数量的活跃参数,以实现资源高效的训练和推理。
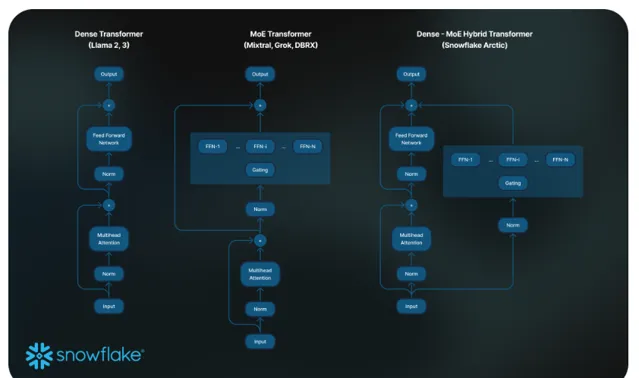
2.架构与系统共同设计 :即使在最强大的人工智能训练硬件上,使用大量专家的普通 MoE 架构的训练效率也非常低,原因是专家之间的全通信开销很高。然而,如果通信可以与计算重叠,就有可能隐藏这种开销。
我们的第二个见解是,将密集型变换器与残差 MoE 组件(见图 2)结合在 Arctic 架构中,使我们的训练系统通过通信计算重叠实现良好的训练效率,隐藏了大部分通信开销。
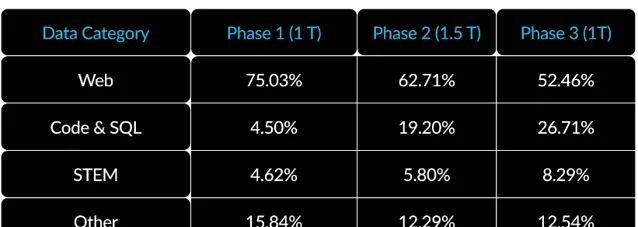
3.面向企业的数据课程 :在代码生成和 SQL 等企业指标上表现出色,需要与训练通用指标的模型完全不同的数据课程。通过数百次小规模的消融实验,了解到像常识推理这样的通用技能可以在训练初期学习,而像编程、数学和 SQL 这样的更复杂的指标可以在训练的后期有效学习。这可以类比人的生活和教育,从简单到复杂逐步获得能力。因此,Arctic 的训练采用了三阶段课程,每个阶段使用不同的数据组合,第一阶段(1T Tokens)关注通用技能,后两阶段(1.5T 和 1T tokens)关注企业核心技能。这里展示了动态课程的高层次概述。
推理效率

训练效率只代表了 Arctic 高效智能的一个方面。推理效率对于以低成本实际部署模型同样至关重要。Arctic 在 MoE 模型规模上代表了一次飞跃,使用的专家数量和总参数量超过了任何其他开源的自回归 MoE 模型。因此,为了在 Arctic 上高效运行推理,需要多个系统见解和创新:
a) 在小批量交互式推理中,例如批量大小为1时,MoE 模型的推理延迟受限于读取所有活跃参数所需的时间,此时推理受内存带宽限制。在这个批量大小下,Arctic(17B 活跃参数)的内存读取量可比 Code-Llama 70B 少4倍,比 Mixtral 8x22B(44B 活跃参数)少2.5倍,从而提高了推理性能。
已与 NVIDIA 合作,并与 NVIDIA(TensorRT-LLM)以及 vLLM 团队合作,为交互式推理提供了 Arctic 的初步实现。通过 FP8 量化,我们可以将 Arctic 配置在单个 GPU 节点内。虽然还远未完全优化,但在批量大小为1时,Arctic 的吞吐量可达到每秒70+个token,有效支持交互式服务。
b) 当批量大小显著增加,例如每次前向传递成千上万个token时,Arctic 从内存带宽受限转变为计算受限,此时推理受每个令牌的活跃参数限制。在这一点上,Arctic 的计算量比 CodeLlama 70B 和 Llama 3 70B 少4倍。
为了实现计算受限的推理和与 Arctic 中活跃参数数量较少相对应的高相对吞吐量(如图3所示),需要较大的批量大小。实现这一点需要有足够的 KV 缓存内存来支持大批量大小,同时还需要足够的内存来存储近500B 的模型参数。尽管具有挑战性,但可以通过使用 FP8 权重、分裂-融合和连续批处理、节点内的张量并行性和节点间的管道并行性等系统优化,采用双节点推理来实现。
项目链接
https://huggingface.co/Snowflake/snowflake-arctic-instruct
关注「 开源AI项目落地 」公众号











