ByConity 是字节跳动开源的云原生数据仓库,在满足数仓用户对资源弹性扩缩容,读写分离,资源隔离,数据强一致性等多种需求的同时,提供优异的查询,写入性能。
文章来源| ByConity 开源社区
GitHub |https://github.com/ByConity/ByConity
作者|程伟,MetaAPP 大数据研发工程师
MetaApp 是国内领先的游戏开发与运营商,专注移动端信息高效分发,致力于构建面向全年龄段的虚拟世界。截至 2023 年,MetaApp 注册用户已超 2 亿,联运合作 20 万款游戏,累计分发量过 10 亿。
MetaApp 在 ByConity 开源早期便保持关注,是最早进行测试并在生产环境上线的用户之一。抱着了解开源数仓项目能力的想法,MetaApp 大数据研发团队对 ByConity 进行了初步测试。其存算分离的架构、优秀的性能,尤其在日志分析场景中,对于大规模数据复杂查询的支持,吸引 MetaApp 对 ByConity 进行了深入测试,最终在生产环境全量替换 ClickHouse, 使资源成本降低超 50%。
本文将主要介绍 MetaApp 数据分析平台的功能,业务场景中遇到的问题及解决方案以及引入 ByConity 对其业务的帮助。
0 1
MetaApp OLAP 数据分析平台架构及功能
随着业务的增长,精细化运营的提出,产品对数据部门提出了更高的要求,包括需要对实时数据进行查询分析,快速调整运营策略;对小部分人群做 AB 实验,验证新功能的有效性;减少数据查询时间,降低数据查询难度,让非专业人员可以自主分析、探查数据等。为满足业务需求,MateApp 实现了集事件分析、转化分析、自定义留存、用户分群、行为流分析等功能于一体的 OLAP 数据分析平台。
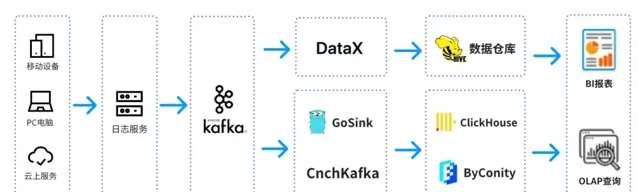
这是一个典型的 OLAP 的架构,分成两部分,一部分是离线,一部分是实时。
在 离线场景 中,我们使用 DataX 把 Kafka 的数据集成到 Hive 数仓,再生成 BI 报表。BI 报表使用了 Superset 组件来进行结果展示;
在 实时场景 中,一条线使用 GoSink 进行数据集成,把 GoSink 的数据 集成到 ClickHouse,另外一条线使用 CnchKafka 把数据集成到 ByConity。最后通过 OLAP 查询平台获取数据进行查询。
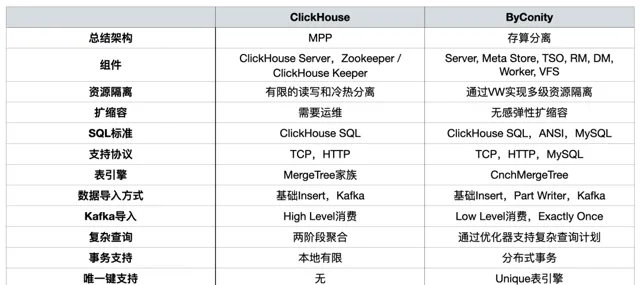
ByConity 和 ClickHouse 功能对比
ByConity 是基于 ClickHouse 内核研发的开源云原生数据仓库,采用存算分离的架构。两者都具有以下特点:
写入速度非常快,适用于大量数据的写入,写入数据量可达 50MB - 200MB/s
查询速度非常快,在海量数据下,查询速度可达2-30GB/s
数据压缩比高,存储成本低,压缩比 可达 0.2~0.3
ByConity 拥有 ClickHouse 的优点,与 ClickHouse 保持了较好的兼容性,在 读写分离、弹性 扩缩容 、数据强一致 方面进行了增强。两者对于以下 OLAP 场景均适用:
数据集可能很大 - 数十亿或数万亿行
数据表中包含许多列
仅查询特定几列
结果必须以毫秒或秒为单位返回
在之前的分享中, ,概括总结如下:
> 详见:
在 OLAP 平台构建过程中,我们主要关注 资源隔离、在 扩缩容 、复杂查询, 以及 对 分布式事务 的支持 。
使用 ClickHouse 遇到的问题
问题一:读写一体容易抢占资源,无法保证读/写稳定
业务高峰期时,数据写入将大量挤占 IO 和 CPU 资源,导致查询受到影响(查询时间变长)。数据查询也是如此。
问题二: 扩/缩容 麻烦,周期长
扩/缩容时间长:由于机器在 IDC,属于私有云,其中一个问题在于,节点增加周期特别长。从增加节点需求发出到真正增加好节点需要一周到两周的时间,影响业务;
无法快速进行扩缩容:扩缩容以后要重新进行数据分布,否则节点压力非常大。
问题三:运维繁琐,业务高峰期无法保证 SLA
常常因为业务的节点故障导致数据查询缓慢,数据写入延迟(从延迟几小时到几天的程度);
业务高峰期时资源出现严重不足,短期内无法扩容资源,只能通过删减部分业务的数据,为优先级高的业务提供服务;
业务低峰期时,资源大量空闲,成本虚高。虽然我们在 IDC,但是 IDC 的机器购买也受成本控制,且不能无限制的节点扩容,另外在正常使用时也有一定的成本消耗;
无法和云上资源进行交互使用。
引入 ByConity 后的改善效果
首先,ByConity 读写分离计算资源隔离可以保证读写任务比较稳定。如果读的任务不够,可以扩展相应资源,哪里不够补哪里,包括使用云上资源进行扩容。
其次,扩缩容比较简单,可以在分钟级别进行扩缩容。由于使用 HDFS/S3 分布式存储,计算存储分离,所以扩容以后不需要进行数据重分布,扩容后可以直接使用。
另外,云原生部署,运维相对简单。
HDFS/S3 的组件相对成熟稳定,扩缩容,灾备方案成熟,出现问题可快速解决;
业务高峰期时,可以通过快速扩容资源保障 SLA;
业务低峰期时,可以通过缩减存储/计算资源达到降低成本的目的。
02
ByConity 的使用与运维
ByConity 集群使用情况
目前,我们平台已经在业务场景稳定使用 ByConity。通过陆续迁移,ByConity 已经完全接管了 ClickHouse 集群的数据,并已经开始稳定提供服务。我们使用云上 S3 加 K8s 的模式搭建了 ByConity 集群;同时使用了定时扩缩容方案,可以在工作日早上 10 点进行扩容,晚上 8 点进行缩容,一天只需要使用十多个小时的资源。通过计算,此方式比直接使用包年包月降低资源 40%- 50% 左右。另外,我们也正在推进 私有云 + 公有云 相结合的方式,以达到降低成本与提升服务稳定性的目的。
下图为我们目前的使用情况,通过 OLAP 服务器对线下 IDC 机房的 ClickHouse 集群和 ByConity 进行联合查询。短期内 ClickHouse 集群将依然使用,作为部分依赖 ClickHouse 业务的过渡。
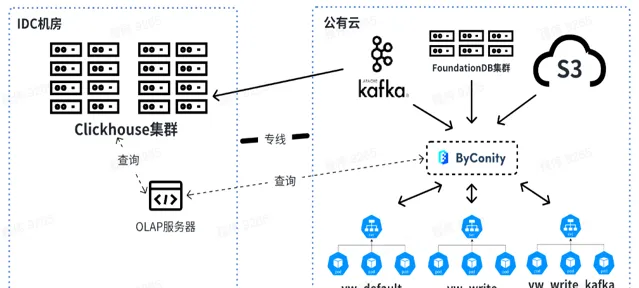
未来我们会在线下进行查询和合并数据,而 Kafka 消耗的资源放到线上使用。在资源扩容时,可以将 vw_default 和 vw_write 的资源扩到线上,合理使用公有云的资源应对资源不足的问题。同时在业务低峰时进行缩容,降低公有云消耗。

ByConity 和 ClickHouse 在业务数据中的查询对比
> 测试数据集及资源配置
数据条数:按日期做分区,单日 40 亿条,10 日共计 400 亿
表列数据:2800 列
ClickHouse | ByConity (0.2.2) | |
集群配置 | 10 分片双副本 单节点 40 核心 256G内存 8T SSD + 16T HDD | vm_read: 15核 110G 500G SSD,8/16 个 worker |
SSD 磁盘读写 | 均为 300~500MB/s | |
HDD 磁盘读写 | 均为 150~200MB/s | |
由上表可以看出:
ClickHouse 集群查询使用的资源为:400核 2560G内存
ByConity 8 worker 集群查询使用的资源为:120核 880G内存
ByConity 16 worker 集群查询使用的资源为:240核 1760G内存
> 业务 SQL 查询结果汇总
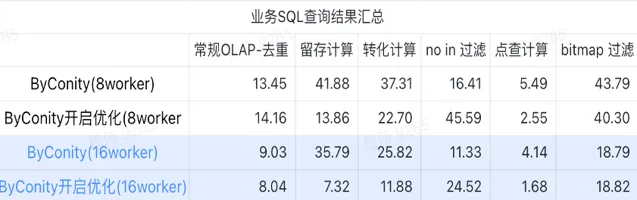
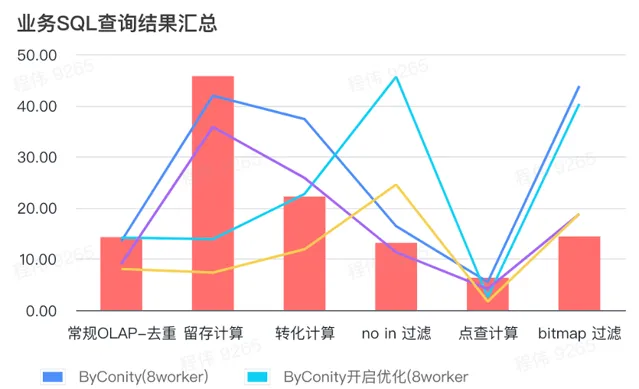
这里的汇总都采用的是平均值,可以看到:
常规 OLAP - 去重、留存、转化、点查都可以通过比较小的资源代价(120C, 880G)达到与 ClickHouse 集群(400C, 2560G)一致的查询效果,并且可以通过扩展一倍资源(240C, 1760G)达到查询速度提升翻倍的效果。如果需要更高的查询速度,可以扩展更多的资源;
not in 过滤可能需要适中的资源代价(240C, 1760G)可以达到和 ClickHouse 集群(400C, 2560G)相似的效果;
bitmap 可能需要更大的资源代价可以达到和 ClickHouse 集群相似的效果。
> 常规查询/事件分析查询
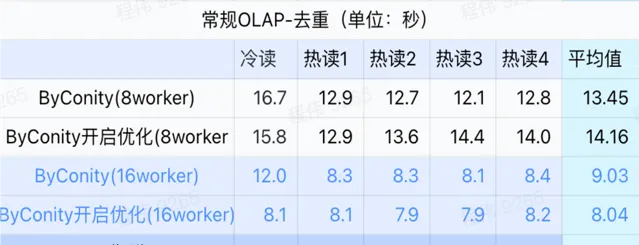
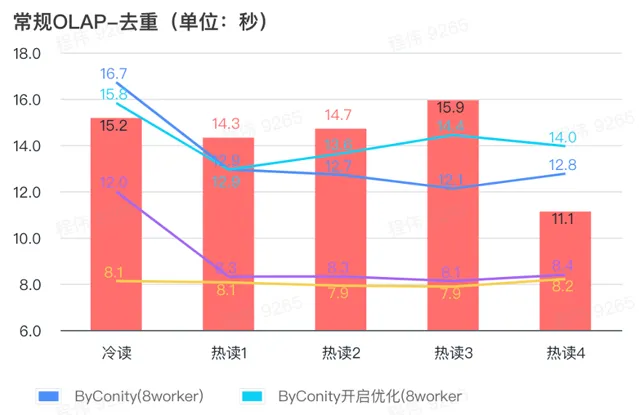
由上图可知:
去重查询场景上 ByConity 开启优化与不开启优化区别不大;
8 worker (120C 880G) 基本上达到与 ClickHouse 接近的查询时间;
去重场景上,可以通过扩展计算资源来加快查询速度。
> 留存计算
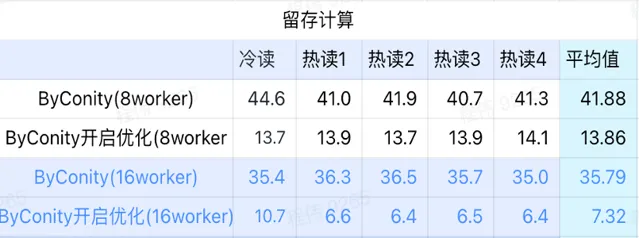
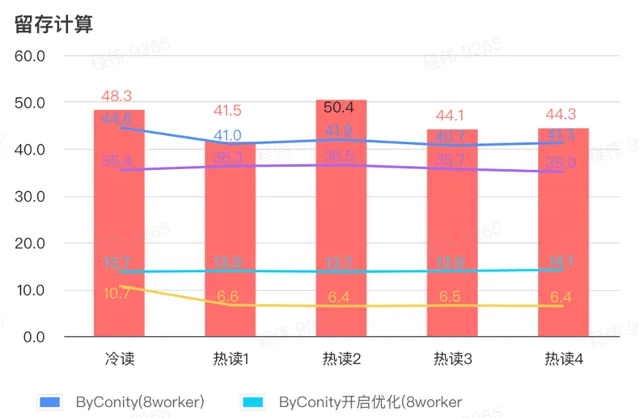
由上图可知:
留存计算场景上 ByConity 开启优化后查询时间是不开启优化查询时间的33%;
8 worker (120C 880G) 开启优化的查询时间是 查询时间的30%;
留存计算场景,可以通过扩展计算资源+优化的方式来将查询速度加速至 CK查询时间的16%。
> 转化计算
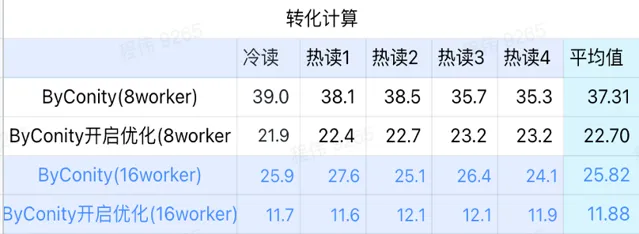
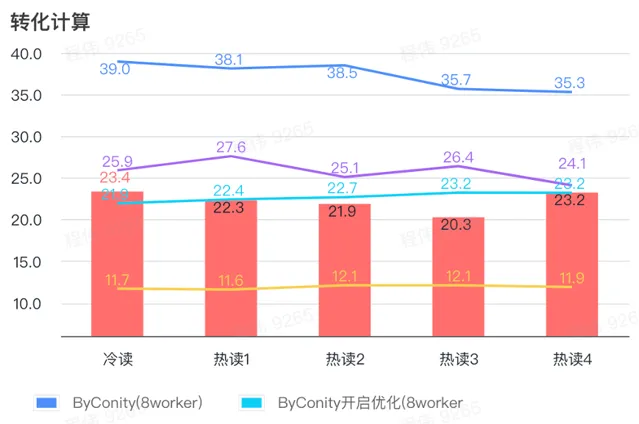
由上图可知:
转化计算场景上ByConity开启优化后查询时间是不开启优化查询时间的 60%;
8 worker (120C 880G) 开启优化的查询时间与 ClickHouse 查询时间接近;
转化计算场景,可以通过扩展计算资源+优化的方式将查询速度加速至 ClickHouse 查询时间的 53%。
> not in 过滤
not in 过滤主要应用于用户分群场景,以及用户打标签场景。
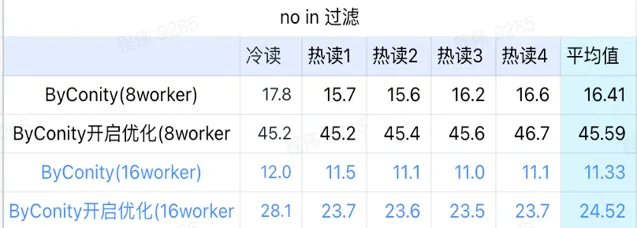
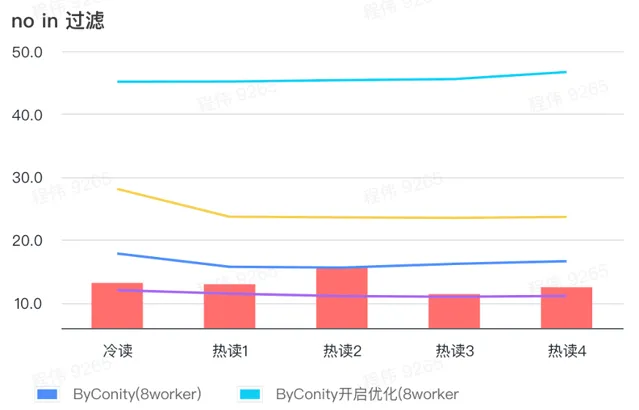
由上图可知:
no in 过滤场景上 ByConity 开启优化后比 ByConity 不开启优化差,所以此场景下我们直接使用不开启优化的方式;
8 worker (120C 880G) 不开启优化的查询时间比 ClickHouse 查询时间慢一些,但并不多;
no in 过滤场景,可以通过扩展计算资源方式来将查询速度加速至 ClickHouse 查询时间的86%。
> 点查计算
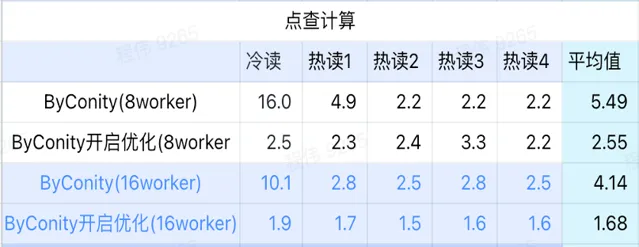
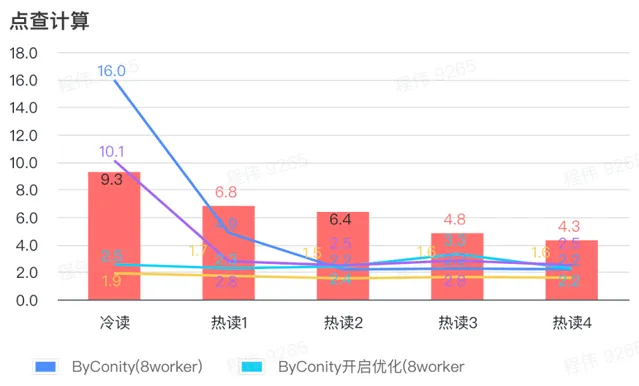
由上图可知:
点查场景上 ByConity 开启优化后比 ByConity 不开启优化好;
8 worker (120C 880G) 不开启优化的查询时间与 ClickHouse 查询时间接近;
点查场景,可以通过扩展计算资源+开启优化的方式来将查询速度加速至 ClickHouse 查询时间的 26%。
> bitmap 查询
bitmap 查询是在 AB 测试中使用更多的一种场景。
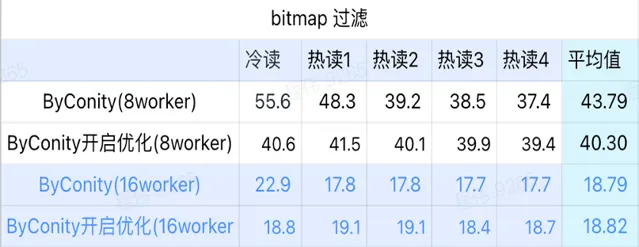
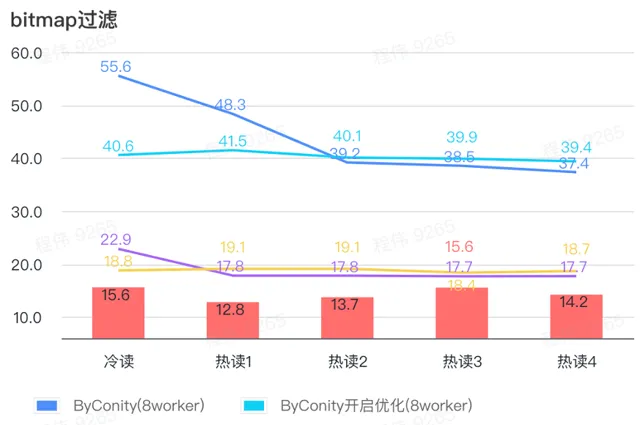
由上图可知:
bitmap 过滤场景上 ByConity 开启优化后比 ByConity 不开启优化好一点;
8 worker (120C 880G) 不开启优化的查询时间比 ClickHouse 查询时间慢很多;
bitmap 过滤场景,扩展资源至 16 worker(240C 1769G) 比 ClickHouse 查询慢。
ByConity 全量迁移后的收获
> 资源降低
以下未统计 CPU 的差异性,数据仅供参考
使用 ByConity 进行全量迁移之后
查询合并资源消耗对比,CPU 消耗比之前减少了 75% 左右;
数据写入资源对比,CPU 消耗比之前减少了进 35% 左右;
只需要购买一半的固定资源,剩下一半靠工作日(早10晚8)定时弹性,成本相比全量购买资源降低了 25% 左右;
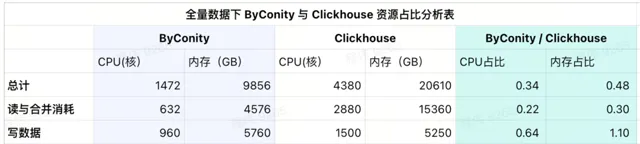
从当前使用的结果表中可以看到,ByConity 的 CPU 和 内存占比分别为 ClickHouse 的 34%和 48%。
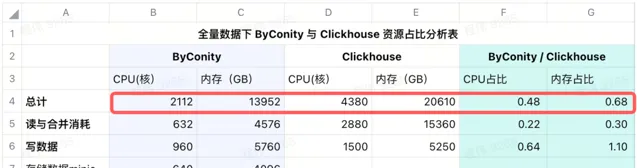
我们在 IDC 使用 minio 来进行数据存储,使用 640 核的 CPU,4096G 内存,16个节点,单节点 40 核,256G,磁盘为 36T,把这些成本加在 ByConity 上之后,ByConity 的 CPU 和 内存占比依然低于 ClickHouse,分别为 ClickHouse 的 48% 和 68%。 可以说,在资源的使用上,如按包年包月购买资源计算,ByConity 比原来至少 降低 50% 左右;如按需启停,相比全量购买资源,成本将再降低 25% 左右 。
> 运维成本降低
更简单的配置数据写入方式。之前我们专门配置的写入服务,常常出现 Too many parts 等问题。
高峰查询扩容更加简单,添加 pod 数量就可以很快扩容,再也没有人来问「数据查了半小时为啥没出来」。
03
ByConity 替换 ClickHouse 的建议
在业务中测试你的 SQL 是否可以在 ByConity 平台上正常运行,如果能够兼容,则基本都可运行。如个别情况下出现一些小问题,可以在社区中提出,获取快速反馈;
控制测试集群的资源,测试数据集大小,对比 ByConity 集群与 ClickHouse 集群的查询结果,看是否符合预期。如果符合预期,可以进行替换计划。对于更侧重计算的任务,可能在 ByConity 中表现更好;
根据测试数据集的大小,消耗的 S3 和 HDF 空间、带宽、QPS 计算资源的使用量,来评估全量数据时存储与计算需要使用的资源;
将数据同时打入 ByConity 或者 ClickHouse 集群,开始一段时间的双跑,解决双跑期间出现的问题。例如我们公司在资源不足的情况下,使用是按业务进行,我们可以先在云上建一个 ByConity 集群,迁入某一部分的业务,之后逐步按业务来替换,腾出 IDC 资源以后,再把这一部分的数据迁移到线下;
双跑没有问题后就可以退订 ClickHouse 集群。
在此过程中有一些注意事项:
S3 和 HDFS 远程存储的读取带宽与 QPS 可能会要求高一些,需要做一定的准备。例如,我们峰值每秒读写带宽为:写 2.5GB/读 6GB,峰值每秒 QPS 为:2~6k;
Worker 节点的带宽用满,也会造成查询瓶颈;
Default 节点(也就是读取计算节点)的缓存盘可以配置的适当大一些,可以降低查询时S3的带宽压力,加快查询速度。
如果遇到未缓存的数据,可能会有冷启动问题。对此 ByConity 也有一些操作建议,具体还需要更多结合自己的业务进行,比如我们使用在早上进行预查的方式来将这一部分的冷启动问题进行缓解。
04
未来规划
未来我们将推动 ByConity 数据湖方案的测试与落地。
另外,我们会将数据指标管理与数仓理论相结合,将 80%的查询落到数仓上。欢迎大家一起加入体验。
GitHub |https://github.com/ByConity/ByConity
添加小助手加入交流群











