作者:后来丶_a24d
链接:https://www.jianshu.com/p/2932410aa1ec
使用示例
public staticvoid main(String[] args) {
Properties props = new Properties();
String topic = "test";
// auto-offset-commit
String group = "test0";
props.put("bootstrap.servers", "XXX:9092,XXX:9092");
props.put("group.id", group);
props.put("auto.offset.reset", "earliest");
// 自动commit
props.put("enable.auto.commit", "true");
// 自动commit的间隔
props.put("auto.commit.interval.ms", "1000");
props.put("session.timeout.ms", "30000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 可消费多个topic,组成一个list
consumer.subscribe(Arrays.asList(topic));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s \n", record.offset(), record.key(), record.value());
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
前置知识之传递性语义保证
定义
At most once:消息可能会丢,但是不会重复传递
At least once:消息不会丢,但是有可能重复传递
Exactly once:每条消息只被传递一次
Exactly once实现
生产者端: 可以为每个消息定义个全局唯一id,消费者端进行过滤,不重复消费
消费者端可能发生的事情:
先处理消息,后提交offset(提交的话有自动提交和手动提交两种):这种有可能导致At most once,如果消息处理之后服务器宕机或者再均衡,这时候已消费的消息并没有被提交到(_consumer_offset主题),就会导致重复消费。
先提交offset, 再处理。这种有可能导致At least once, 如果消息处理之后服务器宕机或者再均衡,这时候已提交offset,但是并未消费
消费者端解决方案
首先关闭自动提交,也不手动提交到(_consumer_offset主题)。而是将offset提交和消息处理放到一个事务(数据可以存储到数据库,redis之类), 事务执行成功则认为消费成功,否则事务回滚。当出现服务器宕机或者再均衡,可以从关系型数据库或者redis找到对应offset并利用KafkaConsumer.seek手动设置消费位置,从此offset开始消费。
如果是服务器再均衡,则可以利用再均衡监听器,其中提供两个方法,一个是再均衡完成之后,拉去数据前执行,这时候可以用seek设置offset。还有一个是停止拉去数据后,再均衡前,这时候可以手动提交,避免再均衡重复消费。
前置知识之消费端再均衡
触发条件
组成员个数发生变化。例如有新的 consumer 实例加入该消费组或者离开组。
订阅的 Topic 个数发生变化。
订阅 Topic 的分区数发生变化
此图是参考Kafka Rebalance机制分析

方案
最开始实现策略是利用zookeeper,zookeeper底下有报错group_ids的路劲,每个consumer都在zookeeper上有相应路劲并注册了Watch。通过Watch每个消费者就可以监控Consumer Group和Kafka了。但是这种策略有两个不过的地方:其一, 容易引起羊群效应,当某个服务器新加入Consumer Group时,所有关注的Watch都会接收到通知。其二, 脑裂, 有可能一台服务器连接两个不同的zookeeper,而其中一台zookeeper有可能不是最新数据。
每个Consumer Group子集对应一个服务端的GroupCoordinator进行管理。此时消费者不再依赖zookeeper,而是依赖GroupCoordinator,GroupCoordinator依赖zookeeper并在zookeeper上注册Watch。当消费者加入或退出消费者群组时会修改zookeeper上面的元数据,这时候会触发相应GroupCoordinator的Watch, 通知GroupCoordinator进行Rebalance。简书上述步骤,步骤1: 如果是新加入Consumer Group的服务器,会向Kafka服务端发送ConsumerMataDataRequest,kafka服务端会告知具体的GroupCoordinator。步骤2: 消费端在知道GroupCoordinator后,会向其发送HeartbeatRequest。如果长时间没发送,GroupCoordinator就会认为对应服务器下线了,会触发Rebalance。步骤3: 如果HeartbeatResponse中包含了IllegalGeneration,说明GroupCoordinator在执行Rebalance, 此时消费者会向GroupCoordinator发现JoinGroupRequest,GroupCoordinator根据JoinGroupRequest和zookeeper元数据完成对Group的分区分配。步骤4: GroupCoordinator完成分区分配时会保存数据到zookeeper,并JoinGroupResponse给对应的request。
第二种方案有个不好的地方就是,每次修改分区策略都得改服务端代码并重启。方案三将分区分配交给消费者端处理,这样实现了解耦。相对方案二改变为: 消费者向GroupCoordinator发送JoinGroupRequest后,服务端的GroupCoordinator会等待一伙直到所有Consumer Group的服务器都发送之后,选取一个Group leader。Group leader会受到所有的消费者信息,并且会根据分区策略进行分区分配。下一个阶段是Synchronizing Group state阶段,在这个阶段,每个消费者会发送SyncGroupRequest给GroupCoordinator,但是Group leader包含了分区分配结果,GroupCoordinator会将分区分配结果作为SyncGroupResponse返回给各个消费者服务器。
前置知识之分区分配策略:
RoundRobinAssignor: 列出所有 topic-partition 和列出所有的 consumer member,然后开始分配,一轮之后继续下一轮

RangeAssignor: 对于剩下的那些 partition 分配到前 consumersWithExtraPartition 个 consumer 上。假设有一个 topic 有 7 个 partition,group 有5个 consumer,这个5个 consumer 都订阅这个 topic,那么 range 的分配方式如下,如果有consumer不参加则不算对应的减少consumer的size
注:
// 表示平均每个 consumer 会分配到几个 partition
numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size():
// 表示平均分配后还剩下多少个 partition 未分配
consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size():
例子:
consumer 0:start: 0, length: 2, topic-partition: p0,p1;
consumer 1:start: 2, length: 2, topic-partition: p2,p3;
consumer 2:start: 4, length: 1, topic-partition: p4;
consumer 3:start: 5, length: 1, topic-partition: p5;
consumer 4:start: 6, length: 1, topic-partition: p6
KafkaConsumer分析
线程安全性
KafkaConsumer非线程安全,这种设计将线程安全转移到了调用方。
解决方案: 可以使用两个线程池,生产-消费模式,解耦消息消费和消息处理,其中一个线程池每个线程持有一个KafkaConsumer对象,(可以根据关注的主题数量来决定线程数量),拉取数据之后放入队列,另一个线程池处理队列里面的数据。qmq的处理方式是一个线程池拉取到数据之后直接交给另一个线程处理,并没有直接通过队列。
高度抽象代码方法总结 这里总结了所接触项目中各种抽象代码的方式,可作为参考
Kafka消息端源码把多种请发送,处理响应,处理完响应成功或者失败传播出去的各个实现都进行了高度统一抽象,很值得学习。
现在看下Heartbeat的响应处理流程,其他请求响应处理流程类似,只不过Handler不同。请求发送完成之后,服务端有响应此时会回调请求持有的。RequestCompletionHandler.onComplete方法,消息端RequestCompletionHandler的实现类是RequestFutureCompletionHandler。RequestFuture,RequestFutureListtener都是为了辅助实现统一格式的响应处理以及响应处理后的事件传播出去。

publicstatic classRequestFutureCompletionHandler
// RequestFuture是真正的处理逻辑
extendsRequestFuture<ClientResponse>
// RequestCompletionHandler 是发送请求时,持有的需要回调的函数接口
implementsRequestCompletionHandler{
@Override
publicvoidonComplete(ClientResponse response){
if (response.wasDisconnected()) {
// 省略
} else {
complete(response);
}
}
}
publicvoidcomplete(T value){
//省略其他
fireSuccess();
}
// 所以这里的关键是listener的添加,添加也交给各个请求的Handler实现
privatevoidfireSuccess(){
for (RequestFutureListener<T> listener : listeners)
listener.onSuccess(value);
}
消费者端有多种请求,比如JoinGroupRequest,SyncGroupRequest,HeartbeatRequest。举个Heartbeat发送请求的逻辑,其他请求发送的格式都大同小异。
private classHeartbeatTaskimplementsDelayedTask{
@Override
publicvoidrun(finallong now){
//省略一部分代码
//这里发送HeartbeatRequest,其他请求发送也是走这两步,但是实现不同
RequestFuture<Void> future = sendHeartbeatRequest();
//HeartbeatResonse成功或失败的事件传播下来继续处理,传播事件的RequestFuture与响应解析的RequestFuture已经不同了
future.addListener(new RequestFutureListener<Void>() {
@Override
publicvoidonSuccess(Void value){
requestInFlight = false;
long now = time.milliseconds();
heartbeat.receiveHeartbeat(now);
long nextHeartbeatTime = now + heartbeat.timeToNextHeartbeat(now);
client.schedule(HeartbeatTask.this, nextHeartbeatTime);
}
@Override
publicvoidonFailure(RuntimeException e){
requestInFlight = false;
client.schedule(HeartbeatTask.this, time.milliseconds() + retryBackoffMs);
}
});
}
}
public RequestFuture<Void> sendHeartbeatRequest(){
HeartbeatRequest req = new HeartbeatRequest(this.groupId, this.generation, this.memberId);
// send返回RequestFuture,响应该请求时调用回调的引用与此RequestFuture相同
return client.send(coordinator, ApiKeys.HEARTBEAT, req)
// 这里主要是为RequestFuture添加listener
.compose(new HeartbeatCompletionHandler());
}
// 此函数高度统一JoinGroupRequest,SyncGroupRequest发送也是调用它
public RequestFuture<ClientResponse> send(Node node,
ApiKeys api,
AbstractRequest request){
// future模式,send函数返回future引用,可以对future进行处理,future继承了RequestFuture
RequestFutureCompletionHandler future = new RequestFutureCompletionHandler();
RequestHeader header = client.nextRequestHeader(api);
// 发送的请求持有future,等该请求接收到响应时就可以调用此future的回调函数
RequestSend send = new RequestSend(node.idString(), header, request.toStruct());
put(node, new ClientRequest(now, true, send, future));
return future;
}
public <S> RequestFuture<S> compose(final RequestFutureAdapter<T, S> adapter){
// 返回新的RequestFuture,此处RequestFuture于响应要回调的RequestFuture不同,这里的目前是给调用send请求的对象添加listener的机会,将成功或失败的响应传播出去
final RequestFuture<S> adapted = new RequestFuture<S>();
// 添加listener
addListener(new RequestFutureListener<T>() {
@Override
publicvoidonSuccess(T value){
// 将成功的响应传播出去
adapter.onSuccess(value, adapted);
}
@Override
publicvoidonFailure(RuntimeException e){
// 将失败的响应传播出去
adapter.onFailure(e, adapted);
}
});
return adapted;
}
RequestFutureAdapter适配器模式,将各种请求的处理都糅合到一起了。
AutoCommitTask, HeartbeatTask。定时任务高度抽象,具体实现交给对应类
加入定时任务,其中DelayedTask 有自动提交任务AutoCommitTask和心跳检测任务两种实现
publicvoidschedule(DelayedTask task, long at) {
delayedTasks.add(task, at);
}
publicinterfaceDelayedTask {
voidrun(long now);
}
执行定时任务,每次poll拉取信息的时候看需要执行下所有加入的定时任务
publicvoidpoll(long now){
// 类似for循环一个个执行, Entry 有时间字段,实现定时任务
while (!tasks.isEmpty() && tasks.peek().timeout <= now) {
Entry entry = tasks.poll();
entry.task.run(now);
}
}
整体流程
整体架构
SubscriptionState管理订阅的Topic集合和消费Partition情况;
Fetch是抓取数据;
ConsumerCoordinator是与服务端GroupCoordinator协作的;
ConsumerNetworkClient是对NetworkClient进行更高一层封装,当然其作用是发网络请求的。
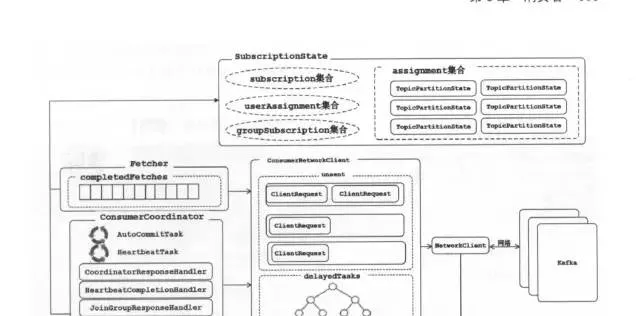
看下KafkaConsumer核心poll方法
public ConsumerRecords<K, V> poll(long timeout){
// 防止多线程并发操作,如果是一个topic对应一个KafkaConsumer,
// 并且将拉取数据放到对应队列,多线程执行数据处理情况下, 可以理解为每个topic都是单线程的
acquire();
try {
// 省略部分代码
do {
// 1\. 核心方法
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining);
//2\. 从订阅的 partition 中拉取数据,pollOnce() 才是对 Consumer 客户端拉取数据的核心实现
if (!records.isEmpty()) {
// 3\. 在返回数据之前,发送下次的 fetch 请求,避免用户在下次获取数据时线程 block
// 因为fetch结果会被缓存,所以这里等于可以并行的执行发送下次请求和处理这次请求
if (fetcher.sendFetches() > 0 || client.pendingRequestCount() > 0)
client.pollNoWakeup();
if (this.interceptors == null)
returnnew ConsumerRecords<>(records);
else
returnthis.interceptors.onConsume(new ConsumerRecords<>(records));
}
} while (remaining > 0);
return ConsumerRecords.empty();
} finally {
release();
}
}
// NO_CURRENT_THREAD -1
// 多线程检测机制
privatefinal AtomicLong currentThread = new AtomicLong(NO_CURRENT_THREAD);
privatefinal AtomicInteger refcount = new AtomicInteger(0);
privatevoidacquire(){
ensureNotClosed();
long threadId = Thread.currentThread().getId();
// 第一次进入会赋值第一个进入的线程,后续有其他线程进入就会报错
if (threadId != currentThread.get() && !currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
thrownew ConcurrentModificationException("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}
pollOnce方法会先通过ConsumerCoordinator与GroupCoordinator完成Rebalance操作,之后从GroupCoordinator获取最新的offset,最后才是fetch消息
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
// 1\. 查找GroupCoordinator,如果需要发送GroupCoordinatorRequest,则激活定时HeartbeatRequet任务
coordinator.ensureCoordinatorReady();
// 2\. 完成rebalance,如果需要rebalance,需要发送JoinGroupRequest, SyncGroupRequest(这里会有分区分配结果)
if (subscriptions.partitionsAutoAssigned())
coordinator.ensurePartitionAssignment();
// 3\. 更新fetch位置
if (!subscriptions.hasAllFetchPositions())
updateFetchPositions(this.subscriptions.missingFetchPositions());
long now = time.milliseconds();
// 4\. 执行定时任务,心跳请求,自动提交请求
client.executeDelayedTasks(now);
// 5\. 从缓存中获取信息
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty())
return records;
// 6\. 缓存没有则发送请求,这里只是标记channel可写
fetcher.sendFetches();
// 7\. 真正发送
client.poll(timeout, now);
return fetcher.fetchedRecords();
}











