项目简介
Champ是由阿里巴巴、复旦大学和南京大学共同开发开发,旨在通过3D参数指导,实现对人体图像动画的控制与一致性。该技术通过深度学习与图像处理的结合,允许用户以前所未有的方式编辑和动画化静态人物图像,打开了人工智能在图像动画领域的新视界。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

Demo
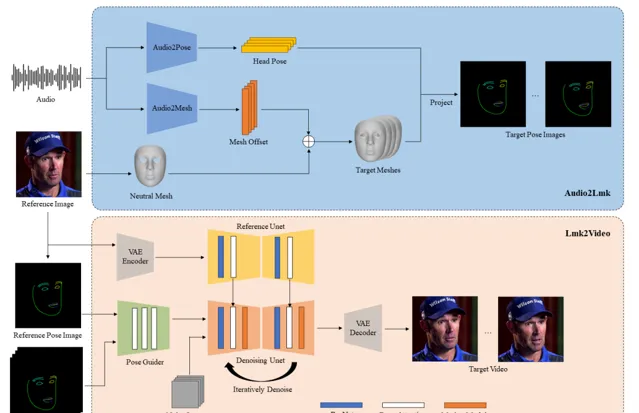
框架
安装
系统要求:Ubuntu20.04/Windows 11、Cuda 12.1
测试的 GPU:A100、RTX3090
创建conda环境:
conda create -n champ python=3.10 conda activate champ
安装软件包pip
pip install -r requirements.txt
安装带有poetry的软件包
如果想在 Windows 设备上运行此项目,我们强烈建议使用poetry.
poetry install --no-root
下载预训练模型
·下载基础模型的预训练权重:
1.StableDiffusion V1.5
https://huggingface.co/runwayml/stable-diffusion-v1-5
2.sd-vae-ft-mse
https://huggingface.co/stabilityai/sd-vae-ft-mse
3.图像编码器
https://huggingface.co/lambdalabs/sd-image-variations-diffusers/tree/main/image_encoder
·下载Checkpoint:
检查点包括去噪UNet、引导编码器、参考UNet和运动模块。
最后,这些预训练模型应该按如下方式组织:
./pretrained_models/|-- champ| |-- denoising_unet.pth| |-- guidance_encoder_depth.pth| |-- guidance_encoder_dwpose.pth| |-- guidance_encoder_normal.pth| |-- guidance_encoder_semantic_map.pth| |-- reference_unet.pth| `-- motion_module.pth|-- image_encoder| |-- config.json| `-- pytorch_model.bin|-- sd-vae-ft-mse| |-- config.json| |-- diffusion_pytorch_model.bin| `-- diffusion_pytorch_model.safetensors`-- stable-diffusion-v1-5 |-- feature_extractor | `-- preprocessor_config.json |-- model_index.json |-- unet | |-- config.json | `-- diffusion_pytorch_model.bin `-- v1-inference.yaml
推理
提供了几组示例数据以供推理使用。请首先下载并将它们放置在 example_data 文件夹中。
以下是推理的命令:
python inference.py --config configs/inference.yaml
如果使用 poetry,命令是:
poetry run python inference.py --config configs/inference.yaml
动画结果将保存在 results 文件夹中。您可以通过修改 inference.yaml 来更改参考图像或引导动作。
您还可以从任何视频中提取驱动动作,然后使用 Blender 渲染。我们稍后将提供此操作的说明和脚本。
注意: inference.yaml 中的默认动作 motion-01 包含超过 500 帧,大约需要 36GB 的显存。如果遇到显存问题,考虑切换到帧数较少的其他示例数据。
ComfyUI
ComfyUI教程链接:
https://www.youtube.com/watch?app=desktop&v=cbElsTBv2-A
项目链接
https://github.com/fudan-generative-vision/champ
关注「 开源AI项目落地 」公众号











