转载 | https://zhuanlan.zhihu.com/p/46216008
程序开发常见的ASCII、GB2312、GBK、GB18030、UTF8、ANSI、Latin1中文编码到底有何不同?如果你在业务中也曾经被乱码搞晕过,不妨一起探究一下。
字符编码要做什么事情?
在计算机眼里读到的所有文字都是由0和1组成的字符串,为了能让汉字正常显示在屏幕上,我们需要做以下两件事情:
给所有的汉字一个独一无二的数字编号,做一个数字编号到汉字的mapping关系(即字符集)
把这个数字编号能用0和1表示出来
这里需要说明的是,第2件事情并不是直接把数字编号用二进制表示出来那么简单,还要处理多个字连在一起的时候如何做分隔的问题。
例如如果我把」腾」编为1号(二进制00000001,占1byte),把「讯」编为5号(二进制00000101,占1byte),汉字这么多,一定还有一个汉字被编为了133号(二进制00000001 00000101,占2bytes)。
那么现在问题来了,当计算机读到00000001 00000101这一串的时候,它应该显示「腾讯」两个字还是显示那一个133号的文字?因此如何做分隔也是字符编码需要考虑的事情。
第2件事情通常解决方案要么就是规定好每个字长度(例如所有文字都是2bytes,不够的前面用0补齐),要么就是在用0和1表示的时候,不仅需要表示出数字编码,还要暗示给计算机接下来多少个连续byte构成一个字,这个后面UTF8编码中会提到。
我们通常所说的Unicode,其实只做了第1件事情,并且是给全世界所有语言的所有文字或字母一个独一无二的数字编码,这样只要设计一种机制做第2件事情来表示Unicode,就可以显示全球范围内任何文字了。Unicode具体对所有语言的每个字母、文字的数字编号可以从其官方网站Unicode编码表 查询。该官网一大亮点是,中文编码表的体量远远超过其他任何语言……
几种常见中文编码的关系如何?
几种常见中文编码之间存在兼容性,一图胜千言
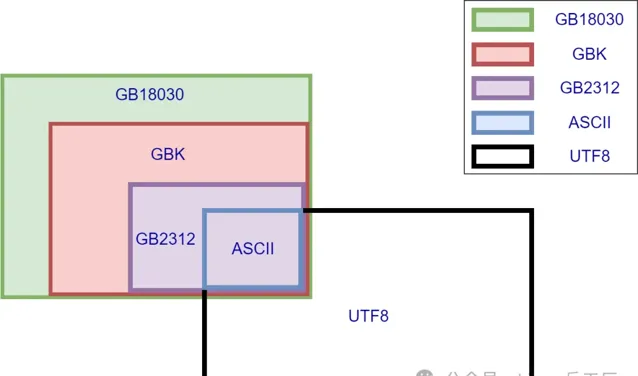
所谓兼容性可以简单理解为子集,同时存在也不冲突,不会出现上文所说的不知道是「腾讯」还是133号文字的情况。
图中我们可以看出,ASCII被所有编码兼容,而最常见的UTF8与GBK之间除了ASCII部分之外没有交集,这也是平时业务中最常见的导致乱码场景,使用UTF8去读取GBK编码的文字,可能会看到各种乱码。而GB系列的几种编码,GB18030兼容GBK,GBK又兼容GB2312,下文细讲。
ASCII编码
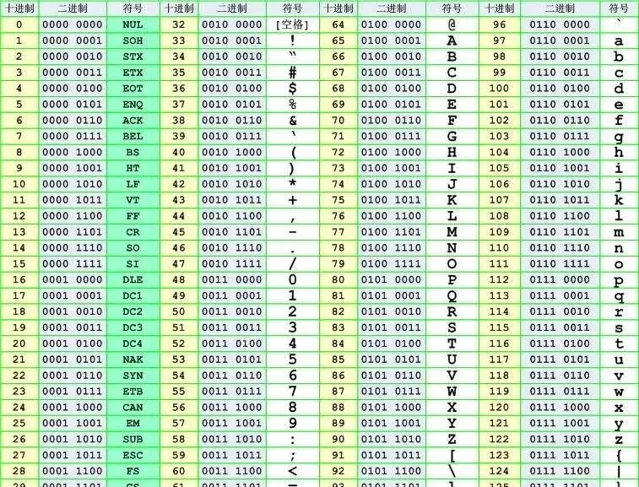
ASCII编码每个字母或符号占1byte(8bits),并且8bits的最高位是0,因此ASCII能编码的字母和符号只有128个。有一些编码把8bits最高位为1的后128个值也编码上,使得1byte可以表示256个值,但是这属于扩展的ASCII,并非标准ASCII。通常所说的标准ASCII只有前128个值!
ASCII编码几乎被世界上所有编码所兼容(UTF16和UTF32是个例外),因此如果一个文本文档里面的内容全都由ASCII里面的字母或符号构成,那么不管你如何展示该文档的内容,都不可能出现乱码的情况。
GB2312、GBK、GB18030编码
GB全称GuoBiao国标,GBK全称GuoBiaoKuozhan国标扩展。GB18030编码兼容GBK,GBK兼容GB2312,其实这三种编码有着非常深厚的渊源,我们放在一起进行比较。
【GB2312】
最早一版的中文编码,每个字占据2bytes。由于要和ASCII兼容,那这2bytes最高位不可以为0了(否则和ASCII会有冲突)。在GB2312中收录了6763个汉字以及682个特殊符号,已经囊括了生活中最常用的所有汉字。(GB2312编码全表:链接)
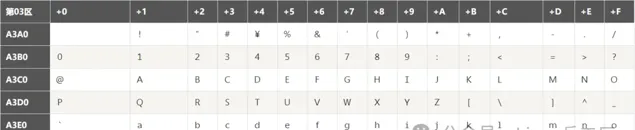
GB2312编码表有个值得注意的点,这个表中也有一些数字和字母,与ASCII里面的字母非常像。例如A3B2对应的是数字2(如下图),但是ASCII里面50(十进制)对应的也是数字2。他们的区别就是输入法中所说的「半角」和「全角」。全角的数字2占两个字节。
通常,我们在打字或编程中都使用半角,即ASCII来编写数字或英文字母。特别是编程中,如果写全角的数字或字母,编译器很有可能不认识……
【GBK】
由于GB2312只有6763个汉字,我汉语博大精深,只有6763个字怎么够?于是GBK中在保证不和GB2312、ASCII冲突(即兼容GB2312和ASCII)的前提下,也用每个字占据2bytes的方式又编码了许多汉字。经过GBK编码后,可以表示的汉字达到了20902个,另有984个汉语标点符号、部首等。值得注意的是这20902个汉字还包含了繁体字,但是该繁体字与台湾Big5编码不兼容,因为同一个繁体字很可能在GBK和Big5中数字编码是不一样的。(GBK编码全表:链接)
【GB18030】
然而,GBK的两万多字也已经无法满足我们的需求了,还有更多可能你自己从来没见过的汉字需要编码。
这时候显然只用2bytes表示一个字已经不够用了(2bytes最多只有65536种组合,然而为了和ASCII兼容,最高位不能为0就已经直接淘汰了一半的组合,只剩下3万多种组合无法满足全部汉字要求)。因此GB18030多出来的汉字使用4bytes编码。当然,为了兼容GBK,这个四字节的前两位显然不能与GBK冲突(实操中发现后两位也并没有和GBK冲突)。
我国在2000年和2005年分别颁布的两次GB18030编码,其中2005年的是在2000年基础上进一步补充。至此,GB18030编码的中文文件已经有七万多个汉字了,甚至包含了少数民族文字。有兴趣的可以到国家标准委官网了解详情,链接
GB2312,GBK,GB18030都是采取了固定长度的办法来解决字符分隔(即前文所提的第2件事情)问题。GBK和GB2312比ASCII多出来的字都是2bytes,GB18030比GBK多出来的字都是4bytes。至于他们具体是如何做到兼容的,可以参考下图:
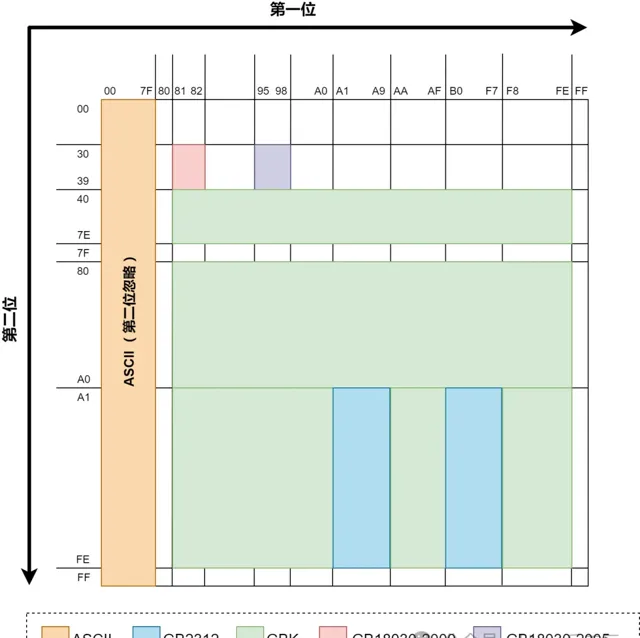
这图中展示了前文所述的几种编码在编码完成后,前2个byte的值域(用16进制表示)。每个byte可以表示00到FF(即0至255)。ASCII编码由于是单字节,所以没有第2位。因为GBK兼容GB2312,所以理论上上图中GB2312的领土面积也可以算在GBK的范围内,GB18030也同理。
上图只是展示出了比之前编码「多」出来的面积。GB18030由于是4bytes编码,上图只是展示了前2bytes的值域,虽然面积最小,但是如果后2bytes也算上,GB18030新编码的字数实际上远远多于GBK。ChatGPT中文网站:https://aigc.cxyquan.com
可以看出为了做到兼容性,以上所有编码的前2bytes做到了相互值域不冲突,这样就可以允许几种不同编码中的文字同时出现在同一个文本文件中。只要全都按照GB18030编码的规则去解析并展示文件,就不会有乱码出现。实际业务中GB18030很少提到,通常GBK见得比较多,这是因为如果你去看一下GB18030里面所编码的文字,你会发现自己一个字也不认识……
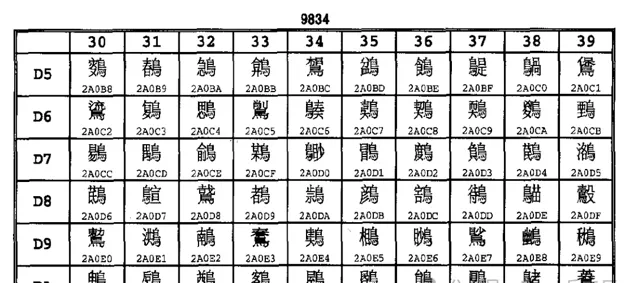
UTF8编码(Unicode Transformation Format)
99%的前端写网页时都会加上,99%的后端工程师新建数据库表时都会加上DEFAULT CHARSET=utf8(剩下的1%应该是忘了写)。
之所以我们想让UTF8一统天下,就是因为UTF8可以表示出世界上所有的文字!UTF8与前面说的GB系列编码不兼容,所以如果一个文件中即有UTF8编码的文字,又有GB18030编码的文字,那绝对会有乱码。
Unicode赋予了全世界所有文字和符号一个独一无二的数字编号,UTF8所做的事情就是把这个数字编号表示出来(即解决前文提到的第2件事情)。UTF8解决字符间分隔的方式是数二进制中最高位连续1的个数来决定这个字是几字节编码。0开头的属于单字节,和ASCII码重合,做到了兼容。
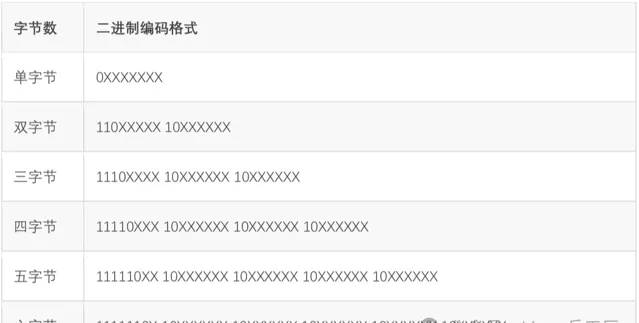
以三字节为例,开头第一个字节的」1110」,有连续三个1,说明包括本字节在内,接下来三个字节一起构成了一个文字。凡是不属于文字首字节的byte都以「10」开头,上表中标注X的位置才是真正用来表示Unicode数值的。
这种巧妙设计,把Unicode的数值和每个字的字节数融合在一起,最坏情况是6个字节表示一个字,已经足够表示世界上所有语言的所有文字了。不过从这种表示方式也可以很显然地看出来,UTF8和GBK没有任何关系,除了都兼容ASCII以外。

举例说明,中文「鹅」字,Unicode十进制值为40517(16进制为9E45,2进制为1001 1110 0100 0101)。这个2进制值长度为12位,查询上面表格发现,二字节不够表示,四字节太长,三字节刚好,因此可以表示为 11101001 10111001 10000101,换算为16进制即E9B985,这就是「鹅」字的UTF8编码,占3字节。另外,经查询,「鹅」的GBK编码为B6EC,和UTF8的值完全不相干。
对于中文汉字来说,所有常用汉字的Unicode值都可以用3字节的UTF8表示出来,而GBK编码的汉字基本是2字节(GB18030虽4字节但是日常没人会写那些字)。这也就导致了,如果把GBK编码的中文文本另存为UTF8编码,体积会大50%左右。这也是UTF8的一点小瑕疵,存储同样的汉字,体积比GBK要大50%。
不过在「可表示世界上所有文字」这一巨大优势面前,UTF8的这点小瑕疵可以忽略了,所以日常开发中最常使用UTF8。
其他经常遇到的编码
【ANSI编码】
准确说,并不存在哪种具体的编码方式叫做ANSI,它只是一个Windows操作系统上的别称而已。在中文简体Windows操作系统上,ANSI就是GBK;在泰语操作系统上,ANSI就是TIS-620(一种泰语编码);在韩语操作系统上,ANSI就是EUC-KR(一种韩语编码)。并且所谓的ANSI只存在于Windows操作系统上。
【Latin1编码(又名ISO-8859-1编码)】
相信99%的人第一次听到Latin1都是在使用Mysql数据库的时候接触到的。Latin1是Mysql数据库表的默认编码方式。Latin1也是单字节编码方式,也就是说最多只能表示256个字母或符号,并且前128个和ASCII完全吻合。
Latin1在ASCII基础上又充分利用了后面那128个值,赋予他们一些泰语、希腊语等字母或符号,将1个字节的256个值全部占满了。因为项目中用不到,我对这种编码的细节没兴趣了解,唯一感兴趣的是为什么Mysql选它做默认编码(为什么默认编码不是UTF8)?以及如果忘了设置Mysql表的编码方式时,用Latin1存储中文会不会出问题?
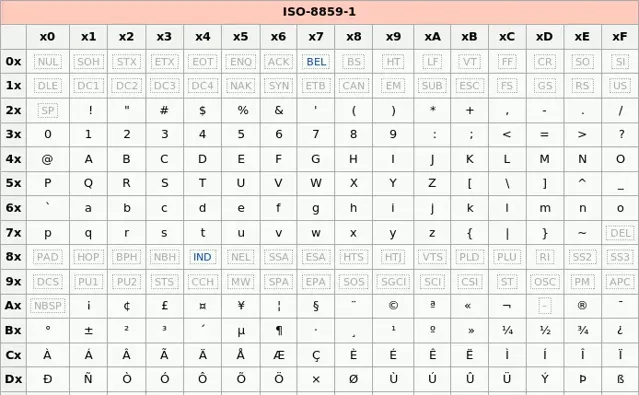
为什么默认编码是Latin1而不是UTF8?原因之一是Mysql最开始是某瑞典公司搞的项目,故默认collate都是latin1_swedish_ci。swedish可以理解为其私心,不过latin1不管是否出于私心目的,单字节编码作为默认值肯定是比多字节做默认值更不容易在插入数据时报错。
既然Latin1为单字节编码,并且将1个字节的所有256个值全部占满,因此理论上把任何编码的值塞到Latin1字段都是可以存的(无非就是显示乱码而已)。
假设默认为UTF8这一多字节编码,在用户误把一个不使用UTF8编码的字符串存进去时,很有可能因为该字符串不符合UTF8的编码要求导致Mysql根本没法处理。这也是单字节编码的一大好处:显示可以乱码,但是里面的数据值永远正确。
用Latin1存储中文有没有问题?答案是没有问题,但是并不建议。例如你把UTF8编码的「讯」字(UTF8编码为0xE8AEAF,占三个字节)存入了Latin1编码的Mysql表,那么在Mysql眼里,你存入的并不是一个「讯」字,而是三个Latin1的字母(0xE8,0xAE,0xAF)。本质上,你存的数据值依然是0xE8AEAF,这种「欺骗」Mysql的行为并没有导致数据丢失,只不过你需要注意读取出来该值的时候,自己要以UTF8编码的方式显示出来,要不然就是乱码。
因此,用Latin1存任何文字技术上都可以,但是经常会导致数据显示乱码。通常的解决方案,就是让UTF8一统天下,建表的时候就声明charset为utf8。
<END>
点这里👇关注我,记得标星呀~
感谢你的分享,点赞,在看三连











