最近经常看到有小伙伴在问,哪个开源的TTS好。
阿里的CosyVoice终于迎来重大升级,化身CosyVoice2。
它最大的亮点是流式合成输出。
这个开源项目一定会让非常多的软件、硬件交互体验提升一个档次。
讲下原因,互动性的AI产品,比如AI陪伴等,产品体验要好, 必须把AI回答的延迟降到最低。
想要延迟低,就必须想办法在各个环节降时间,ASR、LLM部分方案已经很多了,但是TTS方案确实是比较少,大部分方案开发周期比较长,问题在于流式这部分做不好。
像是豆包等产品的API已经有流式了,但是价格上确实是不低,尤其是加上声音克隆,成本太高,用户也难以接受。
CosyVoice 2在各方面做得都不错,粉丝朋友们可以尝试。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
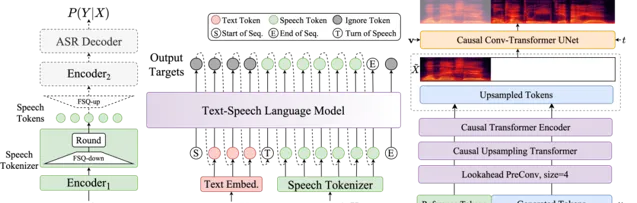
CosyVoice 2是阿里巴巴开发的流式语音合成模型,它通过整合大型语言模型,实现了高质量的语音合成。该模型支持流式和非流式合成,采用有限标量量化技术提高语音信息捕捉,简化模型架构,并开发了块感知因果流匹配模型以适应不同合成场景。CosyVoice 2在保持人类同等自然度的同时,几乎无损地实现了流式模式下的合成质量。
DEMO
各方面能力都很强,咱们一个一个来看。
1、普通的音频克隆。
输入音频
输出音频
2、跨语言声音克隆
输入音频
输出音频
3、有情感的音频合成
快乐的
生气的
4、顺口溜
5、角色扮演
6、方言
粤语
上海话
2.0版本亮点
语言支持
支持语言:中文、英文、日语、韩语、中国方言(粤语、四川话、上海话、天津话、武汉话等)
跨语言和混合语言:支持跨语言和代码切换场景的零样本语音克隆。
超低延迟
双向流支持:CosyVoice 2.0 集成了离线和流建模技术。
快速首包合成:实现低至 150 毫秒的延迟,同时保持高质量的音频输出。
高精度
改进发音:与 CosyVoice 1.0 相比,发音错误减少了 30% 到 50%。
基准测试成果:在Seed-TTS评估集的硬测试集上取得最低的字符错误率。
稳定性强
音色一致性:确保零样本和跨语言语音合成的可靠语音一致性。
跨语言合成:与 1.0 版本相比有显著的改进。
自然体验
增强韵律和音质:改进了合成音频的对齐,将 MOS 评估分数从 5.4 提高到 5.53。
情感和方言灵活性:现在支持更细致的情感控制和口音调整。
项目链接
https://github.com/FunAudioLLM/CosyVoice
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯
关注「 向量光年 」公众号
加速全行业向AI转变











