GPT-4o其实也做到了比较流利的实时对话,但是往往这些模型都需要外接一个TTS,就导致对话还是会产生延迟。
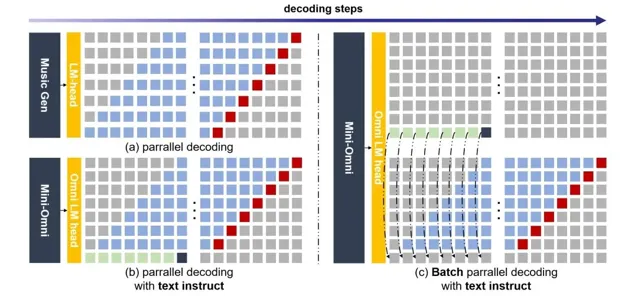
Mini-Omni采用了一种文本指令的语音生成方法,并在推理过程中批量并行进一步提升性能。
所以说Mini-Omni可能是第一个完整意义上的端到端实时语音交互模型。
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
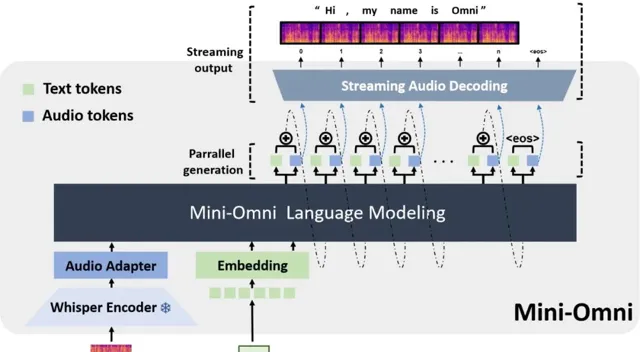
Mini-Omni是一个开源多模态大型语言模型,具备实时对话能力和端到端的语音输入输出功能。通过独特的文本指导并行生成方法,实现了与文本能力一致的语音推理输出,仅需极少的额外数据和模块。
Mini-Omni还引入了一种「任何模型都能说话」的创新方法,通过最小的训练和修改,快速地将其他模型的文本处理能力转换为语音交互能力。
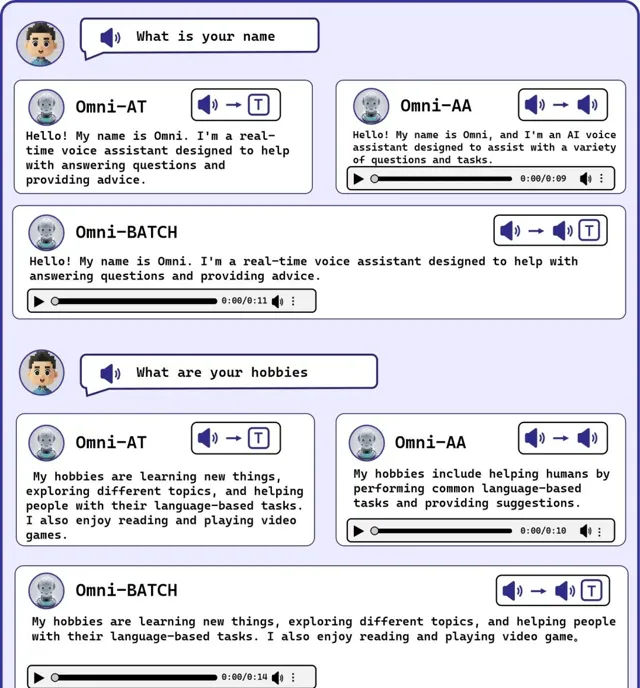
DEMO
只能说,确实快。
这没有延迟的感觉实在是太爽了!
下面图片是流式输出的示例
主要特点和贡献
·端到端的多模态交互能力:
Mini-Omni不仅支持文本输入输出,还能处理语音信号,实现真正的语音到语音的交流,这一点是通过文本指导并行生成技术实现的。
·高效的实时对话能力:
通过创新的并行生成和批处理并行解码技术,Mini-Omni能够在对话中实时响应,显著减少了延迟,提高了交互的自然流畅性。
·模型和数据效率:
该模型使用的是比较小的0.5B参数规模,但通过高效的训练和优化策略,实现了与大模型相媲美的性能,特别是在资源有限的环境下表现出色。
·"任何模型都能说话"的方法:
这是一种新颖的方法,允许通过最小的训练和修改,迅速将其他语言模型的文本处理能力扩展到语音交互领域。
·专门优化的数据集VoiceAssistant-400K:
为了训练和优化语音输出,Mini-Omni使用了特别开发的VoiceAssistant-400K数据集,该数据集旨在帮助模型在提供语音助手服务时减少生成代码符号,增强模型在真实应用中的实用性。
项目链接
https://github.com/gpt-omni/mini-omni
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 向量光年 」公众号
加速全行业向AI转变
关注「 AGI光年 」公众号
获取每日最新资讯











