D-ID大家都不陌生吧
就是最早发布图片生成说话视频的那个软件
这几天新开源了一个项目, <hallo> ,跟D-ID一样的功能,凭出色的效果, 4天在github拿下了2.2k星星

效果几乎可以平替, 主要是免费 啊!而且比之前开源的那些类似项目效果都要好不少
先来看下D-ID的官方演示效果
说实话,D-ID做了这么久, 瑕疵还是能非常明显 的看出来
主要是价格也不便宜啊,下面这是D-ID的价目表
108美金100分钟, 贵贵贵!太贵!
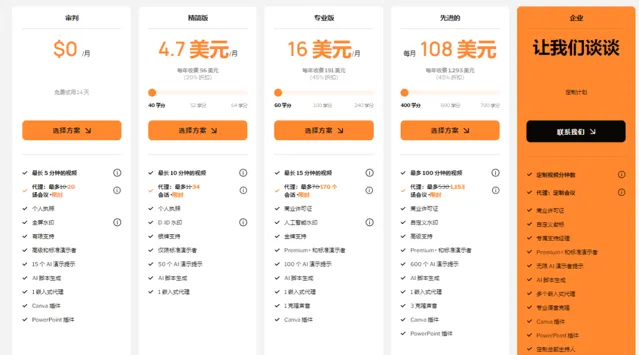
还是<hallo>开源免费的香~
扫码加入AI交流群
获得更多技术支持和交流
(请注明自己的职业)

项目简介
<Hallo> 由复旦大学生成视觉实验室开发,是一个层次化音频驱动的视觉合成系统,用于肖像图像动画制作。该系统利用音频输入驱动肖像图像产生自然的面部动作,可用于视频制作、游戏和其他多媒体应用。支持多种预训练模型和自定义配置,使得用户可以根据需求生成具有高度逼真表情的动画肖像。
DEMO
技术架构
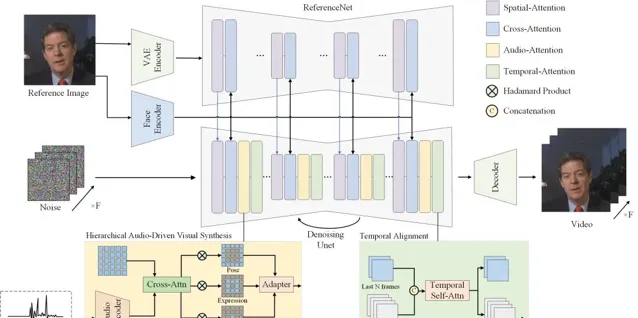
<hallo>采用了基于扩散的方法,开发出一种层次化音频驱动的视觉合成系统,用于生成动态且逼真的肖像动画。
技术框架摒弃了传统依赖参数模型的方法,采用端到端的扩散范式,并引入了用于提高音频输入与视觉输出对齐精度的视觉合成模块,包括嘴唇、表情和姿势动作。
网络架构融合了基于UNet的去噪器、时间对齐技术和参考网络。
输入数据要求
·源图像:
1.图像需裁剪为正方形。
2.脸部应为主要焦点,占图片的50%-70%。
3.脸部应正面朝向,旋转角度小于30°,不可为侧面。
·驱动音频:
1.必须为WAV格式。
2.只支持英语,因为训练数据集仅包括此语言。
3.人声必须清晰,可包含背景音乐。
项目链接
https://github.com/fudan-generative-vision/hallo
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新资讯











