这里我们直接使用kaggle中的 Store Sales — Time Series Forecasting作为数据。这个比赛需要预测54家商店中各种产品系列未来16天的销售情况,总共创建1782个时间序列。数据从2013年1月1日至2017年8月15日,目标是预测接下来16天的销售情况。虽然为了简洁起见,我们做了简化处理,作为模型的输入包含20列中的3,029,400条数据,。每行的关键列为' store_nbr '、' family '和' date '。数据分为三类变量:
defdivide_shuffle(df,div_num): space = df.shape[0]//div_num division = np.arange(0,df.shape[0],space) return pd.concat([df.iloc[division[i]:division[i]+space,:].sample(frac=1) for i in range(len(division))]) defcreate_time_blocks(time_length,window_size): start_idx = np.random.randint(0,window_size-1) end_idx = time_length-window_size-16-1 time_indices = np.arange(start_idx,end_idx+1,window_size)[:-1] time_indices = np.append(time_indices,end_idx) return time_indices defdata_loader(x_numeric_tensor, x_category_tensor, x_static_tensor, y_tensor, batch_size, time_shuffle): num_series = x_numeric_tensor.shape[0] time_length = x_numeric_tensor.shape[1] index_pd = pd.DataFrame({'serie_idx':range(num_series)}) index_pd['time_idx'] = [create_time_blocks(time_length,window_size) for n in range(index_pd.shape[0])] if time_shuffle: index_pd = index_pd.explode('time_idx') index_pd = index_pd.sample(frac=1) else: index_pd = index_pd.explode('time_idx').sort_values('time_idx') index_pd = divide_shuffle(index_pd,5) indices = np.array(index_pd).astype(int) for batch_idx in np.arange(0,indices.shape[0],batch_size): cur_indices = indices[batch_idx:batch_idx+batch_size,:] x_numeric = torch.stack([x_numeric_tensor[n[0],n[1]:n[1]+window_size,:] for n in cur_indices]) x_category = torch.stack([x_category_tensor[n[0],n[1]:n[1]+window_size,:] for n in cur_indices]) x_static = torch.stack([x_static_tensor[n[0],:] for n in cur_indices]) y = torch.stack([y_tensor[n[0],n[1]+window_size:n[1]+window_size+forecast_length] for n in cur_indices]) yield x_numeric.to(device), x_category.to(device), x_static.to(device), y.to(device) defval_loader(x_numeric_tensor, x_category_tensor, x_static_tensor, y_tensor, batch_size, num_val): num_time_series = x_numeric_tensor.shape[0] for i in range(num_val): for batch_idx in np.arange(0,num_time_series,batch_size): x_numeric = x_numeric_tensor[batch_idx:batch_idx+batch_size,window_size*i:window_size*(i+1),:] x_category = x_category_tensor[batch_idx:batch_idx+batch_size,window_size*i:window_size*(i+1),:] x_static = x_static_tensor[batch_idx:batch_idx+batch_size] y_val = y_tensor[batch_idx:batch_idx+batch_size,window_size*(i+1):window_size*(i+1)+forecast_length] yield x_numeric.to(device), x_category.to(device), x_static.to(device), y_val.to(device)
模型
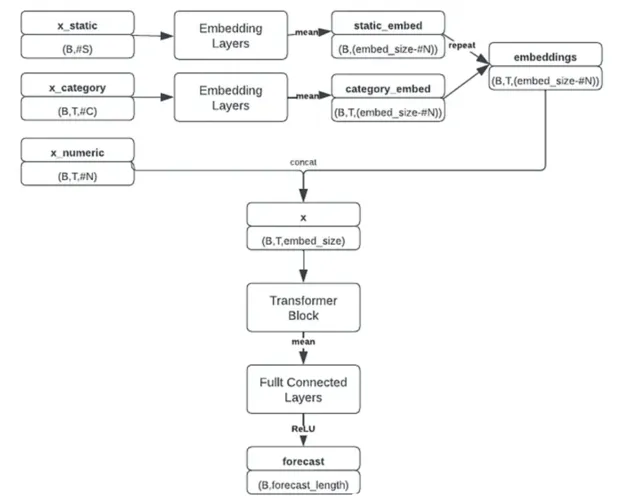
我们这里通过Pytorch来简单的实现【Attention is All You Need】(2017)²中描述的Transformer架构。因为是时间序列预测,所以注意力机制中不需要因果关系,也就是没有对注意块应用进行遮蔽。
引用:
[1]: Alexis Cook, DanB, inversion, Ryan Holbrook. (2021). Store Sales — Time Series Forecasting. Kaggle. https://kaggle.com/competitions/store-sales-time-series-forecasting
[2]: Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need.
Advances in neural information processing systems
,
30
.
[3]: Lim, B., Arık, S. Ö., Loeff, N., & Pfister, T. (2021). Temporal fusion transformers for interpretable multi-horizon time series forecasting.
International Journal of Forecasting
,
37
(4), 1748–1764.