随着人工智能的不断发展,AI已经逐渐成为我们日常生活中不可分割的一部分。今天,我为大家带来的是一个我近期投入研究的开源项目——AntSK,它结合了LLamaSharp,不仅带来了高效便捷的本地离线AI知识库搭建方法,更是无需借助公司账户,个人开发者也能轻松搭建和使用。
项目地址请参考:
https://github.com/xuzeyu91/AntSK
AntSK:项目概述与特点
在介绍如何整合LLamaSharp之前,我们首先要了解的是AntSK这个项目。AntSK利用Blazor技术与Semantic Kernel相结合,配合Kernel Memory,构建了一个易于操作和扩展的本地知识管理系统。开源的特性使得它受到了不少朋友的关注和喜爱,并为没有公司资源的个人开发者提供了更多可能。
外部模型依赖的困境
尽管AntSK本身崭露头角,我们发现,在实际应用中,尤其是想要利用国内某些Embedding模型时,往往遇到了限制个人账号申请的壁垒,例如「百川」等AI模型服务。而星火大模型虽然对个人开放,但它缺少必要的Embedding能力,使得我们无法充分利用。
LLamaSharp:融合之道
这个问题的解决方案是引入LLamaSharp,一个可以帮助我们实现本地AI模型部署和使用的开源库。LLamaSharp的优势在于它允许我们在不依赖外部服务的情况下,本地运行大模型。更加详细的信息和代码,你可以在LLamaSharp on GitHub找到。
https://github.com/SciSharp/LLamaSharp/
选型模型:Hugging Face的贡献
为了有一个测试和展示的基础,我们需要从Hugging Face上选择若干AI模型。在我的试验中,我随机挑选了两个模型进行了测试。不过在此过程中,需要注意的是,并非所有模型都能够顺利加载。模型加载时可能会遇到内存保护读取的问题,这可能是由于所选择的模型不支持当前的LLamaSharp版本。
处理这种情况的方法是根据LLamaSharp项目中提供的每个版本对应的
llama.cpp
的commit id,我们可以通过克隆llama仓库,然后切换到符合我们需求的commit id来编译我们需要的版本。
LLamaSharp接口:开启离线AI之门
接下来的重点是如何利用LLamaSharp写接口,这里我们需要编写两个接口,一个是用于聊天的Chat接口,另一个是用于Embedding的接口。代码示例如下,我们将保持接口的返回格式和openai完全一致,这样可以无缝切换到本地模型服务:
[ApiController]public class LLamaSharpController(ILLamaSharpService _lLamaSharpService) : ControllerBase {///<summary>/// 本地会话接口///</summary>///<returns></returns> [HttpPost] [Route("llama/v1/chat/completions")]publicasync Task chat(OpenAIModel model) {if (model.stream) {await _lLamaSharpService.ChatStream(model, HttpContext); }else {await _lLamaSharpService.Chat(model, HttpContext); } }///<summary>/// 本地嵌入接口///</summary>///<param name="model"></param>///<returns></returns> [HttpPost] [Route("llama/v1/embeddings")]publicasync Task embedding(OpenAIEmbeddingModel model) {await _lLamaSharpService.Embedding(model,HttpContext); } }
在配置文件中,把OpenAI的配置修改为本地服务地址,就可以愉快地调用本地的LLamaSharp模型了。
"OpenAIOption": {"EndPoint": "https://localhost:5001/llama/","Key": "……","Model": "……","EmbeddingModel": "……" }
性能优化:因地制宜
由于我的本地模型运行在CPU上,推理速度相对慢一些。为了避免在KernelMemory请求时出现超时,我对HttpClient的超时时间进行了延长,并且降低了段落分片的token数值。
var httpClient = new HttpClient(handler);httpClient.Timeout= TimeSpan.FromMinutes(5);var memory = new KernelMemoryBuilder() .WithPostgresMemoryDb(postgresConfig) .WithSimpleFileStorage(new SimpleFileStorageConfig { StorageType = FileSystemTypes.Volatile, Directory = "_files" }) .WithSearchClientConfig(searchClientConfig)//本地模型需要设置token小一点。 .WithCustomTextPartitioningOptions(new Microsoft.KernelMemory.Configuration.TextPartitioningOptions { MaxTokensPerLine=99, MaxTokensPerParagraph=99, OverlappingTokens=47 }) .WithOpenAITextGeneration(new OpenAIConfig() { APIKey = OpenAIOption.Key, TextModel = OpenAIOption.Model }, null, httpClient) .WithOpenAITextEmbeddingGeneration(new OpenAIConfig() { APIKey = OpenAIOption.Key, EmbeddingModel = OpenAIOption.EmbeddingModel }, null, false, httpClient) .Build<MemoryServerless>();
效果展示与问题排查
经过配置和部署,我们可以看到这样的效果:知识文档已经成功切片导入进AntSK系统。 不过当我进行检索的时候发现效果并不理想,文档的相似度与预期有较大差距 。这是否是因为模型本身的问题,亦或是LLamaSharp的兼容性问题呢?这需要更多的测试和研究才能得出结论。
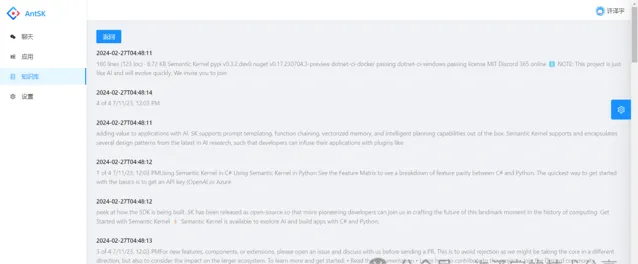
我将会持续关注这个问题,并在后续的文章中为大家带来更多进展。同时,也欢迎广大AI技术爱好者和开发者关注我的公众号,一起交流探讨AI技术的最新趋势和问题解决方案。
以上就是我今天想与大家分享的内容。AI的世界千变万化,搭建一个私人定制的AI知识库可能并不是一条平坦的道路,但正是这样的挑战和不断的试错,才使得我们能够逐步丰富自己的技术武库,开拓更多的可能性。希望我的文章能给你带来启发和帮助,我们下期再见!


![WebAssembly核心编程[4]: Memory](http://img.jasve.com/2024-2/8020795141984d8d410e95c8d81fa0b2.webp)








