导读 苏喻博士,高级工程师,合肥人工智能研究院副研究员,原科大讯飞AI 教育研究院副院长,中国科学技术大学博士后,安徽省青少年信息学教育专委会秘书长,CCF 大专委-通讯委员,合肥市 D 类人才。苏喻博士一直在 智慧教育 方向深耕,聚焦于 青少年编程 。面对 数据稀疏 和 学习效果延时性 问题,苏喻博士团队在 教育领域大模型 的研发中, 技术 上有如下三个方面的亮点:1)通过对偶数据的模型训练与评估和历史经验注入实现 青少年编程垂类大语言模型; 2)基于分层知识图谱和推理 prompt 生成实现 基于小知识的大模型学习; 3)融合知识追踪模型和 大模型仿真的强化认知推荐。产品应用 上,苏喻博士团队开发了 青蛙编程平台、AI 编程学习机 以及 数字人 AI 录播课 平台等。
本次的分享会围绕下面五方面展开:
1. 智慧教育背景及挑战
2. 教育领域大模型
3. 产品案例
4. 思考与展望
5. 问答环节
分享嘉宾| 苏喻 博士 合肥人工智能研究院 副研究员
01
背景及挑战
1. 背景
苏喻博士,2011 年 7 月至 2022 年 2 月就职于科大讯飞研究院,历任科大讯飞 AI 教育研究院副院长,AI 研究院认知群教育条线负责人,学习机业务线教研总监,重点负责教育领域个性化学习业务,包括个性化学习相关模型研究,产品设计,服务研发等,其研发的多项成果已经成功应用到讯飞智学网、讯飞智能学习机等相关产品中,于 2018 年获得讯飞首届华夏创新奖,获 2020 年吴文俊人工智能科学技术奖科技进步一等奖。先后参与多项安徽省、部级等层面的重大项目科研工作,如国家自然科学基金重点项目、科技部重大专项等。其间获得多项发明专利,并在 AAAI、KDD、IJCAI 等国际知名学术会议与期刊发表文章近 30 篇,其中 CCF 推荐会议论文 A 类文章 7 篇,中文核心期刊论文 5 篇,SCI 检索英文期刊论文 10 篇。

(1)个性化学习
几千年前,孔子提出 因材施教 的观点,但受限于校内大班教学现状,传统教学方案无法满足学生的个性化需求。

目前市场上的个性化教育产品呈现井喷的态势,如科大讯飞的学习机、腾讯课堂、松鼠 AI(原易学)等,通过信息化及人工智能方法对学生能力进行诊断,并给出推荐。

(2)科大讯飞产品
科大讯飞学习机,自 2019 年开始发力至今成为头部,主要提供给学生自主性、个性化的学习方案,节省学生时间,提高学生的学习兴趣。平台和教师通过学生在平板上的学习,分析学生的做题情况和能力水平,提供给学生一个个性化的知识图谱,学生可依据该图谱对薄弱知识点进行自主强化学习。同时,学习进展可视化,使学生可以了解每天的进步情况,提升学习兴趣。

百度、作业帮等工具,针对考试错题,通过拍搜即可得到正确答案,这样容易导致学生抄答案不再深入思考。而科大讯飞的个性化学习手册是基于考试情况和错题,给每个学生推荐个性化的题目(无答案),同学间无法互相抄。此外,科大讯飞的产品对于试题有较好的表征,同时错题推荐更具科学性。
① 试题表征
多模态资源理解,将包括文本、立体几何图像、音频等在内的试题独立编码到各自多模态的空间中。然后进行多模态的语义对齐、self attention、Multi task 等工作。一道题的知识点、考点、难度作为其标签,这些信息全部映射为空间中的一个向量。传统试题打标签需要人工完成,一方面人工费高,另一方面主观性强,一致率低。通过机器打标签可以提高准确率。
② 错题推荐
根据学生做的一道错题,通过一些相关的内容和语义推荐类似的题目,一方面在双减的情况下,学生更容易掌握错题相关的知识点;另一方面,教师可以针对上课中学生做错的例题,搜集到相似题目作为学生的课堂作业,提升备课效率。
③ 错题难度-最近发展区理论
基于教育心理学中的最近发展区理论,推荐简单的内容,学生觉得无趣、浪费时间;推荐太难的内容,会使学生丧失信心。因此推荐题目的难度非常关键,应是稍高于学生当前水平,可通过一定时间学习达到目标,感受到成就感,这样才可以提升其学习兴趣。
④ 实现方法-同分异构学生错题
实现的方法是收集所有学生的答题记录(百万级别,当前到亿级),放于教育认证诊断模型中,将学生的信息映射到一个空间里,通过寻找目标学生的同分异构学生(水平类似,知识结构有较小的差距),将同分异构学生的错题推荐给目标学生。这是基于假定——该类错题对于目标学生更容易学会。
⑤ 解释性及可视化-知识图谱
针对 C 端场景对于解释性的需求,通过大量的学生数据,基于多模态的编码,将学生的能力映射到一个知识图谱上,为学生提供个性化的学习路径,提升其学习效率和学习积极性。
图谱的每一个 节点 代表知识点或知识点的组合
边 表征了知识点的前后继承关系
颜色 代表学习程度,如绿色代表学得好,红色代表学得差,黄色代表学得一般。
学生基于该图谱,可进行一系列操作,如针对红色的知识点,点击后会出现一条设计好的学习路径。

(3)青少年编程
素质教育-编程领域 ,学生对个性化学习的需求更多,难度更大。除了中小学生外,高校学生在上编程实验课时,也会遇到各种问题,老师也会遇到无法针对每个学生的问题一一解答的困境。青少年编程课程,无论是公立校还是教培,即使小班也会是 1 对 6,每个学生在每分钟都会有其个性化的问题(如调不通)等待老师回答。公立校中,老师会尝试性将大部分同学搞不定的问题的标准答案放于屏幕上,私立校会基于学费和学时,重点支持解决问题,但仍难以满足个性化学习的需求。
① OJ 试题
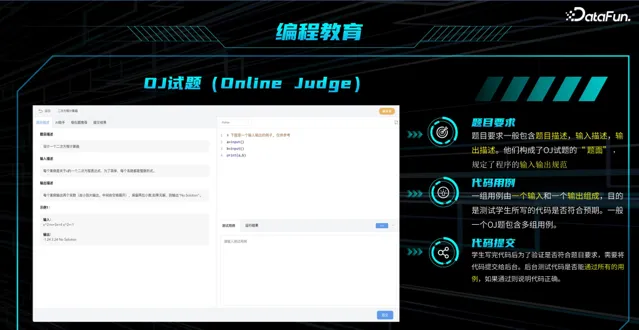
此外,编程教育中会采用 OJ 试题,与传统教育试题不同,会对题目有要求,OJ 试题的题面要求包含题目描述,规定了输入输出规范。一个 OJ 试题包含多组用例,一个代码用例由一个输入和一个输出组成,测试学生所写的代码是否符合预期。
② 个性化编程平台
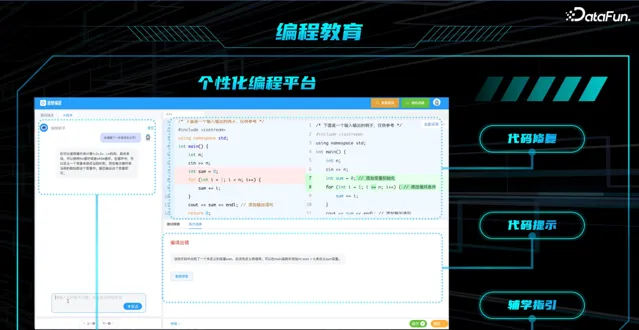
个性化编程平台包含代码修复、代码提示、辅学指引三部分。
代码修复
学生写完代码后,基于大模型的认知诊断,对代码进行修复,根据学生当前的水平,给出代码提示和步骤。
代码提示
基于研发的底层编译器,为用户提供了中文 debug 界面,此外还会针对学生的基础语法等弹出相应的知识卡片。这样可以解决用户 80% 到 90% 的个性化问题。
辅学指引
基于上述代码提示,教师只需解决 10% 的共性难点问题,有助于将编程学习顺畅地进行下去,提升学生的编程积极性。
2. 挑战
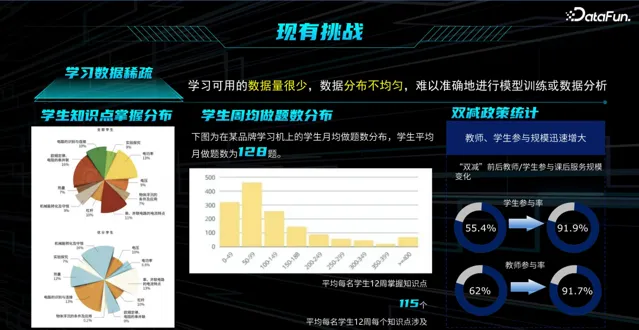
(1)数据稀疏
当前大数据的量很大,但数据稀疏。如平台虽然存在海量的学生编程数据、答题数据,但对于某一个学生的记录是有限的。如何根据学生在平台做的几道编程题,对其进行很好的诊断,是一大挑战。同样,数据稀疏的挑战也存在于其他领域,如医疗大模型,企业可获得很多病人的案例,但平台上某一个人的病例,可能只有一两例。
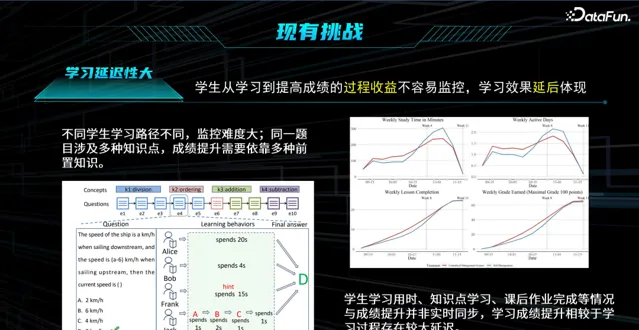
(2)学习延时性
针对学生的推荐,是否使其学习能力提升,能否通过编程等级考试,是无法即刻体现的。学习型的问题,其推荐的收益不易监控,学习效果会延后体现(可能很多天,甚至半年)。
纯 C 端的广告推荐,相对更容易体现效果,推荐内容后,是否点击、购买等都可以通过打点获取到效果信息。
02
教育领域大模型
应用大语言模型去辅助青少年编程,一方面依赖大语言模型的 NLG(Natural Language Generation)能力,可对提示做出连贯且符合上下文的文本回应,另一方面凭借大模型的 Zero-shot 或 Few-shot 的学习能力,可以帮助理解新任务,并在最小提示和样本下达到有利结果。此外,大语言模型也展现了强大的跨领域泛化能力。
针对数据稀疏或者个人真实数据较少的现状,如何实现 Zero-shot 能力?是否可以基于其他领域的知识,通过大模型实现泛化学习?团队就此开展了以下几个工作:一是青少年编程垂类大语言模型,二是基于小知识的大模型学习,三是基于大模型的仿真强化认知推荐。
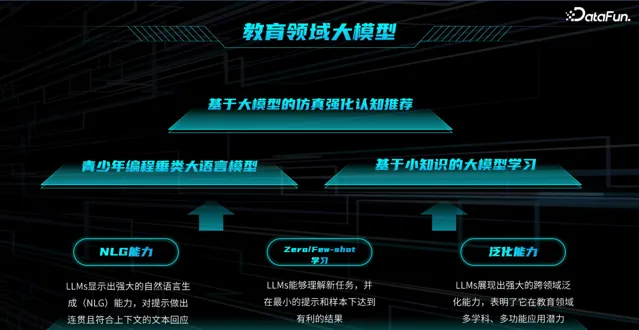
垂类大语言模型和小知识大模型主要解决数据稀疏性的挑战,基于大模型的仿真强化认知推荐解决收益闭环太长的问题。
1. 编程垂类大语言模型

编程垂类大模型构建流程主要包括数据获取、模型训练和知识注入三个步骤。
(1)数据获取
通过对成熟优秀的 LLM 提问,让其模仿孩子给出错误代码。在编程领域这种做法的一大问题是,得到的回答可能经常是一些简单的语法错误,比如缺少一半括号,这对于编程领域大模型是没有帮助的。
因此,我们构建了生成数据鉴别器,来区分生成的数据和真实的数据。
同时,我们也通过 Prompt 生成器,来自动生成更为真实的指令。
最终,基于这样两个模型的 对抗神经网络 进行错误代码生成,使得生成数据的分布与真实数据非常接近。
(2)模型训练(Fine Tuning)
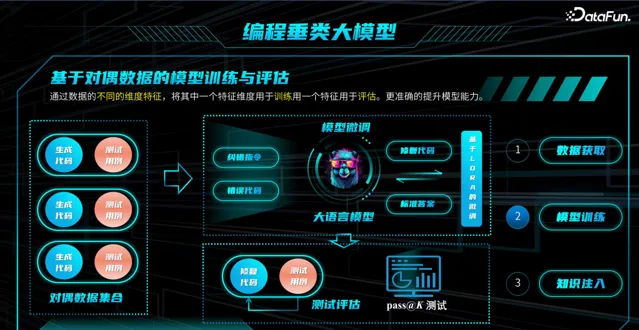
在开源大模型 LLaMA 基础上,通过 Lora 微调生成代码相关的垂类大模型,实现输入错误代码,生成正确代码。然而有时 错误代码修正后,虽与标准答案很像,但仍存在一些逻辑上的错误,无法通过测试用例。
因此提供了测试评估的接口,对答案进行评分。整个微调有两个监督信号,本质上有两个 loss,首先 要求修复的代码与标准答案很像,第二要通过测试用例,通过得越多,评分越高。这一工作,我们称之为对偶数据,因为标准答案和测试用例在本质上是对同一事物的两种描述。
(3)基于历史经验的知识注入
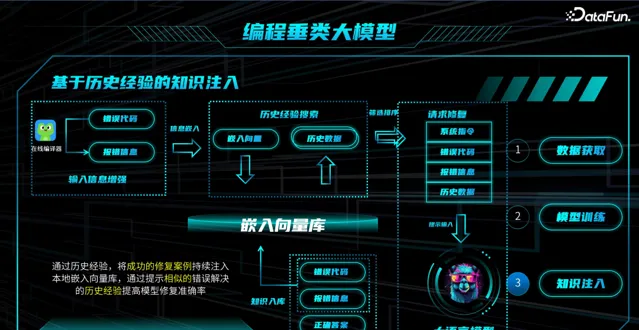
由于原始数据量不同,通过历史经验,将成功修复案例持续注入本地嵌入向量库中,通过提示相似错误解决的历史经验,提高模型修复的准确率。
高质量数据积累 :现实中学生写出的错误代码,基于报错信息修正后得到正确答案,这一系列真实数据作为历史经验持续注入知识库中;
嵌入向量库 : 将上述数据放入编程垂类大模型中,把大模型作为编码器,将其转为向量存放于一个嵌入向量库中;
输入信息增强 :通过在线编译器,将新的学生写出的错误代码生成报错信息;
筛选排序,找到协同数据 :在编码后的知识库当中检索与新学生的嵌入向量(原始问题)类似的问题,生成一个极为复杂的 prompt;
请求修复 :将上述包含相似错误解决历史经验的 prompt 输入到大语言模型中,请求修复,提高修复的准确率。
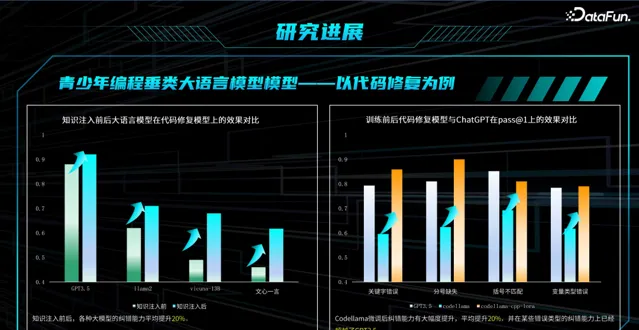
如上图测试了四个大模型—GPT3.5、LLAMA2、Vicuna-13B 和文心一言,经过历史经验知识注入后嵌入式寻找协同数据,使得大模型的代码能力较原来未采用知识注入的效果有较大的提升。
此外,以代码修复为例,与 ChatGPT3.5 对比,经过上述知识注入后微调的结果,在关键字错误、分号缺失、括号不匹配、变量类型错误等方面都有提升,平均提升 20%,大部分任务优于 GPT3.5。
2. 小知识学习
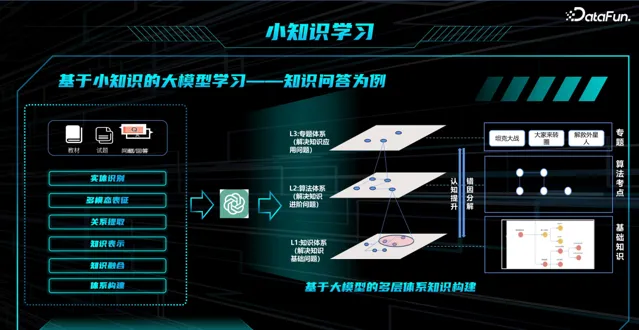
在微调中,通常面临如下的问题:基于整理好的垂类领域数据,如 TB 级别的数据灌入到大模型中,但是大模型只能对已经输入的特定知识进行回答,泛化一些的问题,则完全无法给出答案。 如何基于小的垂类知识,激活大模型相关能力? 下面以 知识问答 为例,介绍 基于小知识的大语言模型学习。
多层知识体系: 我们采用 人机耦合 方式构建 分层知识图谱 ,下层为粒度细的知识点,上层为泛化的知识。利用大模型,自己挖掘节点之间的关系。
示例: 二分查找怎么做?
知识查找 :将二分查找问题的关键点抽取出来,并映射到图谱上,找到所有相关的分层图谱,建立相关性连接;
推理图构建 :在局部知识图谱上进行简单推理;
知识推理 :基于图将其变成一个 prompt,并放入大模型中;

这样,将二分查找的相关细节输入到大模型中进行微调,经过微调的大模型更有机会激发得到正确的答案。
多轮迭代的大语言模型小知识学习
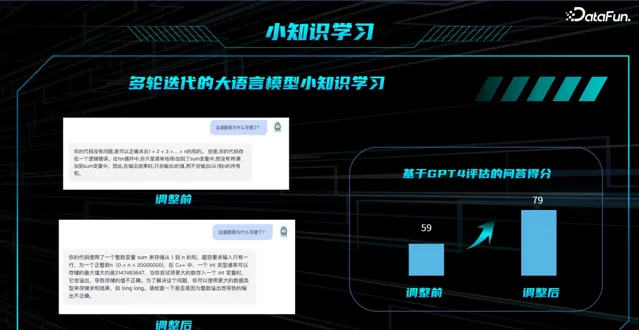
示例:学生问循环累加哪里错了?
未调整前的 Prompt : 直接问循环累加怎么做,大模型给到的答案较敷衍,无法解决学生的问题。
调整后的 Prompt:基于推理图,给到更精准的 Prompt。
基于 GPT4 进行回答评分,调整前基本 10 道题有 6 道题答得不错,调整后 10 道题会有 8 道题回答较好,有了大幅提升。
知识注入后,大模型了解了概念,但是仍然无法回答问题,原因在于 prompt 不够好。通过模仿 prompt 工程师,可以有效提升大模型的效果。这样解决了只是简单将语料给到大模型,大模型没有办法激活相关能力的问题。
3. 强化认知推荐
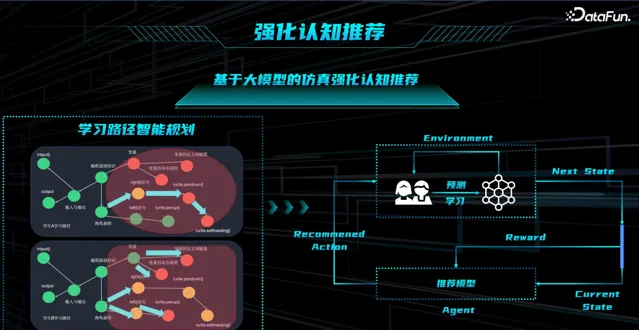
由于给学生推荐学习路径的收益显现历时较长,如何评判哪个学习路径推荐更好呢?两个水平近似但知识分布不同的学生,推荐的学习路径也应不同。面对上述挑战,我们采用了强化学习的方案,推荐模型即为 Agent,缺乏的环境通过大模型模拟生成,也即 基于大模型的仿真强化认知推荐 。
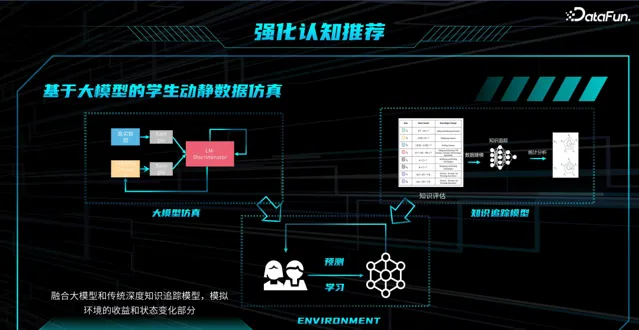
融合大模型和传统深度知识追踪模型,模拟环境的收益和状态变化情况。
给出 状态 ,如推荐一道题后,学生状态发生哪些变化。
推荐一道题后,基于领域的函数,得出其即时的 收益。
学生的知识图谱:
黄色: 待学习的知识点
蓝色: 推荐学习知识点
绿色: 已掌握知识点
红色: 未掌握知识点
通过大模型解决了没有交互数据(即推荐学习后状态和收益数据)实现强化学习的问题。
在原来比较小规模数据中,实现学会一道题,按照之前逻辑可能需要 9 步,通过当前的方式,提高推荐能力,解决同一道题目,只需要更少的步骤。

在中等知识点学习中,强化认知推荐比普通的认知推荐平均步骤下降了 30%,有更高的学习效率。
03
产品案例
1. 青蛙编程平台
上述教育大模型,已集成于青蛙(找 bug)编程平台和 AI 编程学习机中。

青蛙编程平台可以实现 AI 自主学习,基于知识卡进行智能交互式练习,更加轻松有趣。当前已与多位名师、多家机构合作,服务 2 万 + 学生,基于数据驱动的教学更高效、精准。
上述技术已经发表 40+论文、10+ 专利。
2. AI 编程学习机
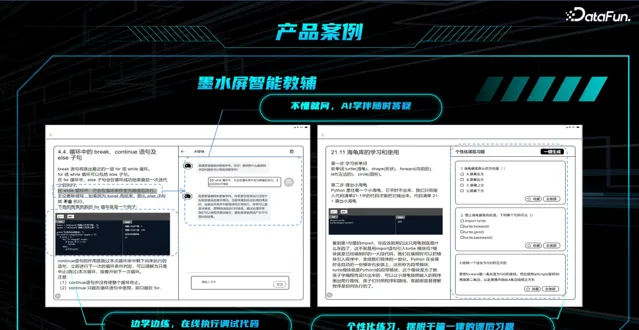
AI 编程学习机采用了墨水屏幕,无蓝光,更护眼。
智能教辅示例:
学生: 这道题怎么做?
大模型: 给出一些提示
学生: 基于提示还是不会做,怎么办?
大模型: 给出正确答案
学生: 将正确答案抄写后,编译通过,但未通过测试用例
大模型: 英语少了一个字母
学生: 终于完成这道题目
智能教辅一方面解决了通常只能一对一才能解决的问题,另一方面孩子自主完成题目,提升其自信心和学习兴趣。同时可以让教师集中精力解决共性的难点问题。
3. 智能云端编译器
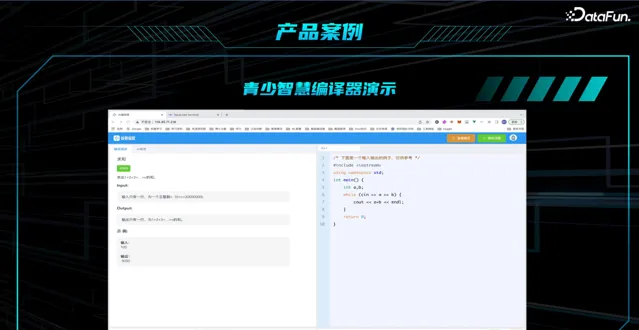
平台中集成了青少智慧编译器(智能云端编译器),超过行业头部品牌。
编译器具有如下四大优势:
更轻便: 云端免安装,降低对硬件的要求
更智能: 内置青少编程大模型,可智能纠错
更专业: 内置各种编程环境,减少出错的问题
更简单: 编译器汉化,降低调试的门槛。
4. 数字人 AI 录播课平台
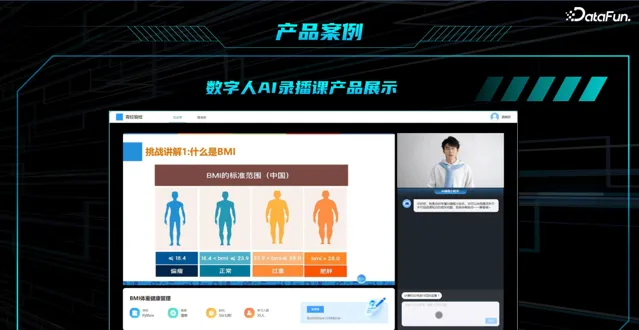
录播课通常为老师持续输出内容,学生可能无法长时间专注。基于数字人的 AI 录播课平台,提供了 个性化课程、智能化老师、精准化练习 。
虚 拟老师可实现针对学生的问题,实时回答,提高 互动性 。
根 据学生的历史信息以及录播课的情况、编程情况,可生成个性化编程题目,提高学习的 趣味性 。
如下为一段 示例 :
虚拟老师 :如图,目前公认的在中国适用的 BMI 标准是:当 BMI 小于等于 18.4,说明你的体重偏瘦。当 BMI 大于 18.4,小于等于 23.9,说明你的体重正常。当 BMI 大于 23.9 且小于等于 28.0,就是过重。当 BMI 大于 28.0 就达到肥胖程度。
孟同学 :为什么 BMI 大于 28 是肥胖而不是 27?
虚拟老师 :BMI 大于 28 被定义为肥胖是基于大量的研究和统计数据得出的结论,这个标准是根据全球范围内的人群数据进行分析得出的。不同的人群可能有不同的标准,但是 28 是一个被广泛接受的标准。
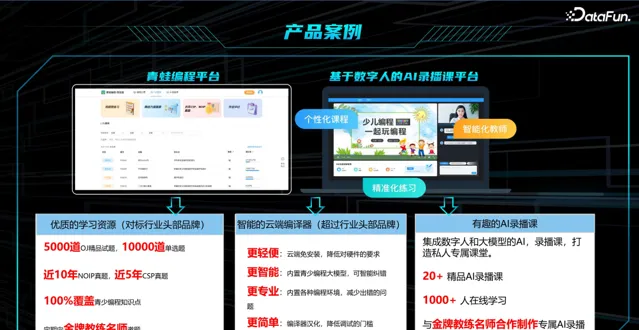
青蛙编程平台以及数字人 AI 录播课平台 ,涵盖优质的学习资源,可对标行业头部品牌,集成了智能云端编译器,已经超过行业头部品牌,与金牌教练名师合作制作专属AI 录播课,打造私人专属课堂。
04
思考与展望
1. 大模型 VS.「小模型」
大模型能力全面,但存在如下限制:
(1)计算资源需求大
高 性能计算机、专用加速器(如 GPU 、 TPU 等)。
大 量的存储空间。
(2)训练时间长
通常需要数天甚至数周的时间,需要高效的算法和硬件加速训练过程。
(3)不易定制
通 常达到千亿级别的参数才能实现特殊能力的涌现,不易定制。
垂 类大模型做完后,到实现上线和 B 端机仍有很多工作要做。
中小厂的取胜之道,降低模型 size、做定制化、本地化。
利 用网络剪枝、向量量化、低秩近似等技术减少大模型的参数。
利 用知识蒸馏等技术将大模型的特殊能力迁移到小规模网络参数的模型。
2. 融入领域知识
在通用大模型上,小公司与大公司有较大的差距,但小公司基于小而美的专家团队,融入领域知识,结合知识图谱,可以在垂类大模型上赢得先机。
3. 「人工的智能」在于精细化的数据
「人工的智能」胜在垂类的精细化数据。中小厂做垂类大模型的商业模式,一定不是花钱做标注,那将需要非常大的资金成本。中小公司可通过设计商业模式, 让用户免费「帮忙」标数据 。例如,我们有虚拟老师、自主编程平台,孩子在完成代码的修订过程中,就是在帮忙标记数据,随着业务的推广,数据飞轮效应将逐渐显现。
05
问答环节
Q1 :贵司的教育大模型是如何训练微调的?
A1:由于当前很多大模型相关训练和微调的技巧未写专利和论文,今日更多分享的是思路,用的还是通用的一些方法,如 SFT 等。
Q 2: 小知识学习中,客体知识多,但是单个用户(主体)的知识很少的问题,是如何来增强解决的?
A2 : 对于主体知识的补足 , 我们 基于对抗神经网络,通过仿真生成更多的主体数据。例如,一个学生在平台做了三道题,基于其他学生的题目,通过大模型仿真模拟学生做第四道题、第五道题、第六道题。同时基于对抗神经网络实现模拟的题目与学生的真实水平一致。
以上就是本次分享的内容,谢谢大家。
分享嘉宾
INTRODUCTION
苏喻 博士
合肥人工智能研究院
副研究员
苏喻,工学博士,硕士生导师,合肥综合性国家科学中心人工智能研究院副研究员,合肥师范学院计算机学院副教授,专业负责人,中国计算机学会大数据专家委员会通讯委员,安徽省计算机学会青少年信息学教育专委会秘书长,研究方向为自然语言理解,数据挖掘与推荐系统。2011 年 7 月-2022 年 2 月就职于科大讯飞研究院,历任科大讯飞 AI 教育研究院副院长,AI 研究院认知群教育条线负责人,学习机业务线业务总监,重点负责教育领域个性化学习业务,其研发的多项成果已经成功的应用到讯飞智学网、讯飞学习机等相关产品中,于 2018 年获得讯飞首届华夏创新奖,获 2020 年吴文俊人工智能科学技术奖科技进步一等奖。同时,先后参与多项安徽省、部级等层面的重大项目科研工作,如国家自然科学基金重点项目「基于多模态数据的学习者认知诊断理论与关键技术研究」、科技部重大专项「面向分类用户个性化需求的科技大数据精准服务技术」等。其间获得多项发明专利,并在 AAAI、KDD、IJCAI 等国际知名学术会议与期刊发表文章近 50 余篇 。
点个 在看 你最好











