项目介绍
🎈 该项目主要分析深圳通刷卡数据,通过大数据技术角度来研究深圳地铁客运能力,探索深圳地铁优化服务的方向;
✨ 强调学以致用,本项目的原则是尽可能使用较多的常用技术框架,加深对各技术栈的理解和运用,在使用过程中体验各框架的差异和优劣,为以后的项目开发技术选型做基础;
👑 解决同一个问题,可能有多种技术实现,实际的企业开发应当遵守最佳实践原则;
🎉 学习过程优先选择较新的软件版本,因为新版踩坑一定比老版更多,坑踩的多了,技能也就提高了,遇到新问题可以见招拆招、对症下药;
架构图
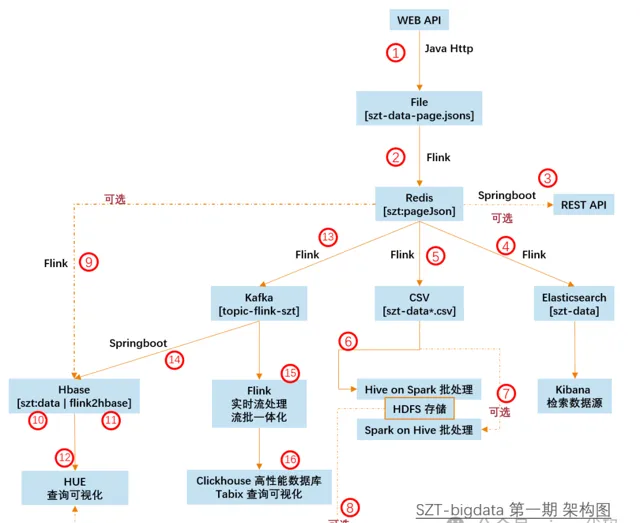
核心技术栈
Java-1.8/Scala-2.11
Flink-1.10,流式业务、ETL 首选
Redis-3.2,天然去重,自动排序
Kafka-2.1,消息队列业务解耦、流量消峰、订阅发布场景首选
kafka-eagle-1.4.5,集生产、消费、Ksql、大屏、监控、报警于一身,同时监控 zk
Zookeeper-3.4.5,集群基础依赖,选举时 ID 越大越优势,通过会话机制维护各组件在线状态
CDH-6.2,解决了程序员最难搞的软件兼容性问题,全家桶服务一键安装;
Docker-19,最快速度部署一款新软件,无侵入、无污染、快速扩容、服务打包。
SpringBoot-2.13,通用 JAVA 生态,敏捷开发必备
knife4j-2.0
Elasticsearch-7,全文检索领域唯一靠谱的数据库,搜索引擎核心服务,亿级数据毫秒响应
Kibana-7.4,ELK 全家桶成员,前端可视化
ClickHouse,家喻户晓的 nginx 服务器就是俄罗斯的代表作,接下来大红大紫的 clickhouse 同样身轻如燕,但是性能远超目前市面所有同类数据库,存储容量可达PB级别。
MongoDB-4.0,文档数据库,对 Json 数据比较友好,主要用于爬虫数据库
Spark-2.3,目前国内大数据框架实时微批处理、离线批处理主流方案
Hive-2.1,Hadoop 生态数仓必备,大数据离线处理 OLAP 结构化数据库
Impala-3.2,像羚羊一样轻快矫健,同样的 hive sql 复杂查询,impala 毫秒级返回
HBase-2.1 + Phoenix,Hadoop 生态下的非结构化数据库,HBase 的灵魂设计就是 rowkey 和多版本控制
Kylin-2.5,麒麟多维预分析系统,依赖内存快速计算,但是局限性有点多啊,适用于业务特别稳定,纬度固定少变的场景
HUE-4.3,CDH 全家桶赠送的,强调用户体验,操作数仓很方便,权限控制、hive + impala 查询、hdfs 文件管理、oozie 任务调度脚本编写
阿里巴巴 DataX,异构数据源同步工具,主持大部分主流数据库
Oozie-5.1,本身 UI 奇丑,但是配合 HUE 食用尚可接受,主要用来编写和运行任务调度脚本
Sqoop-1.4,主要用来从 Mysql 导出业务数据到 HDFS 数仓
Mysql-5.7
Hadoop3.0(HDFS+Yarn),HDFS 是目前大数据领域最主流的分布式海量数据存储系统,这里的 Yarn 特指 hadoop 生态,主要用来分配集群资源,自带执行引擎 MR
阿里巴巴 DataV 可视化展示
准备工作:
Win10 IDEA 2019.3 旗舰版,JAVA|Scala 开发必备,集万般功能于一身;
Win10 DBeaver 企业版 6.3,秒杀全宇宙所有数据库客户端,几乎一切常用数据库都可以连,选好驱动是关键;
Win10 Sublime Text3,地表最强轻量级编辑器,光速启动,无限量插件,主要用来编辑零散文件、markdown 实时预览、写前端特别友好
其他一些实用工具参考我的博客:https://java666.cn/#/AboutMe
CentOS7 CDH-6.2 集群,包含如下组件,对应的主机角色和配置如图,集群至少需要40 GB 总内存,才可以满足基本使用
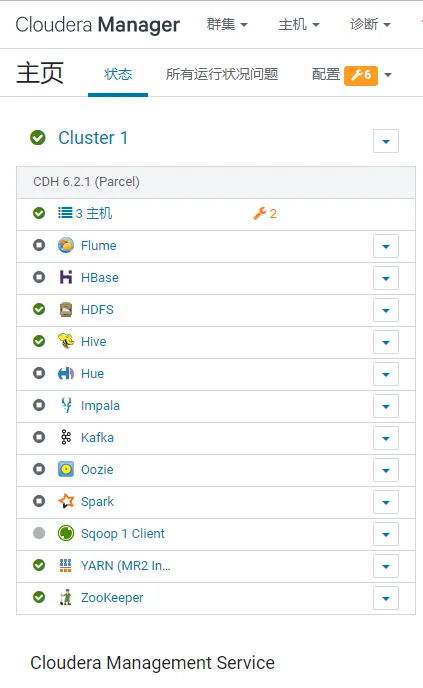

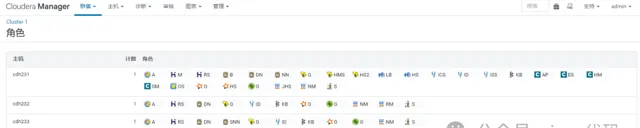
如果你选用原版 Apache 组件搭建大数据集群,那么你会有踩不完的坑。我的头发不够掉了,所以我选 CDH 【2021 年以后,CDH 彻底收费,学习阶段不再推荐,USDP 可以尝试一下,但是占用内存台多,强行部署请准备好足够的硬件,建议的集群配置是 32G RAM * 3,。补充:随着 Hadoop 生态的软件迭代,兼容性问题日趋严重,为了解决兼容问题,推荐自行部署 Apache 版本的原生 Hadoop 集群,你可以从头到尾编译和定制自己的每一个组件每一行代码
物理机配置
以上软件分开部署在我的三台电脑上,Win10 笔记本 VMware + Win10 台式机 VMware + 古董笔记本 CentOS7。物理机全都配置 SSD + 千兆以太网卡,HDFS 需要最快的网卡。好马配好鞍,当然你得有个千兆交换机配合千兆网线

如果你有一台超过 16G RAM 的闲置 Linux 主机,可以尝试使用更快的方式初始化本项目的 hadoop 集群环境,使用 vagrant 批量部署集群,快速体验:
# 在 linux 机器(RAM > 16G)执行以下命令,目前只兼容 centos7
# 科学上网环境部署:https://github.com/juewuy/ShellClash
curl -sSL https://raw.githubusercontent.com/geekyouth/vagrant/main/start.sh | sh -x
如果你想避免网线牵来牵去,可以采用电力猫实现分布式家庭组网方案;
数据源
深圳市政府数据开放平台,深圳通刷卡数据 133.7 万条【离线数据】貌似已经停止服务😒:
https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403601
备用数据源(之前上传的一批 jsons 数据有些纰漏,于是重新整理压缩后放到本仓库中,速度慢的同学可以尝试码云 https://gitee.com/geekyouth/SZT-bigdata ):
.file/2018record3.zip
理论上可以当作实时数据,但是这个接口响应太慢了,如果采用 kafka 队列方式,也可以模拟出实时效果。
本项目采用离线 + 实时思路 多种方案处理。
开发进度
1- 获取数据源的 appKey:
https://opendata.sz.gov.cn/data/api/toApiDetails/29200_00403601
2- 代码开发:
2.1- 调用 cn.java666.etlspringboot.source.SZTData#saveData 获取原始数据存盘 /tmp/szt-data/szt-data-page.jsons,核对数据量 1337,注意这里每条数据包含1000条子数据;
2.2- 调用 cn.java666.etlflink.sink.RedisSinkPageJson#main 实现 etl 清洗,去除重复数据,redis 天然去重排序,保证数据干净有序,跑完后核对 redis 数据量 1337。
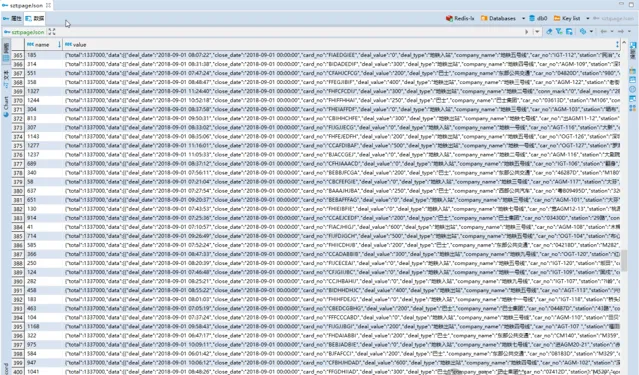
2.3- redis 查询,redis-cli 登录后执行 hget szt:pageJson 1
或者 dbeaver 可视化查询:
2.4- cn.java666.etlspringboot.EtlSApp#main 启动后,也可以用 knife4j 在线调试 REST API:
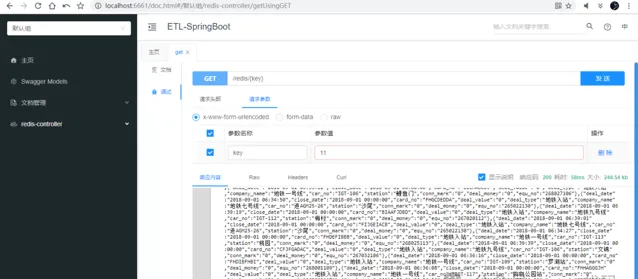
2.5- cn.java666.etlflink.source.MyRedisSourceFun#run 清洗数据发现 133.7 万数据中,有小部分源数据字段数为9,缺少两个字段:station、car_no;丢弃脏数据。
合格源数据示例:
{
"deal_date": "2018-08-31 21:15:55",
"close_date": "2018-09-01 00:00:00",
"card_no": "CBHGDEEJB",
"deal_value": "0",
"deal_type": "地铁入站",
"company_name": "地铁五号线",
"car_no": "IGT-104",
"station": "布吉",
"conn_mark": "0",
"deal_money": "0",
"equ_no": "263032104"
}
不合格的源数据示例:
{
"deal_date": "2018-09-01 05:24:22",
"close_date": "2018-09-01 00:00:00",
"card_no": "HHAAABGEH",
"deal_value": "0",
"deal_type": "地铁入站",
"company_name": "地铁一号线",
"conn_mark": "0",
"deal_money": "0",
"equ_no": "268005140"
}
2.6- cn.java666.etlflink.app.Redis2Kafka#main 根据需求推送满足业务要求的源数据到 kafka,topic-flink-szt-all 保留了所有源数据 1337000 条, topic-flink-szt 仅包含清洗合格的源数据 1266039 条。
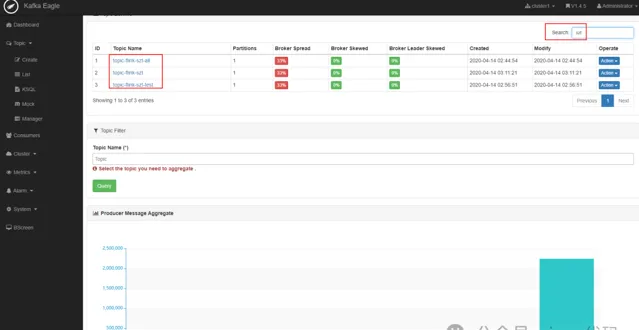
2.7- kafka-eagle 监控查看 topic,基于原版去掉了背景图,漂亮多了:
}
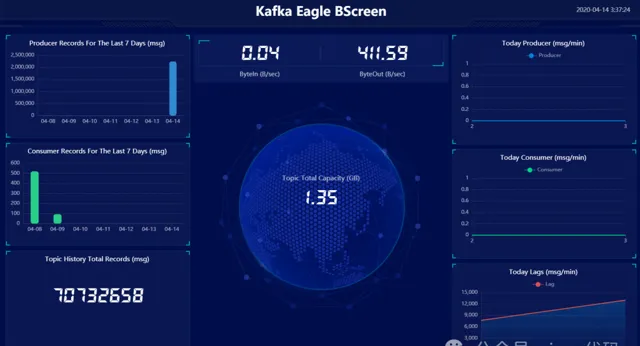
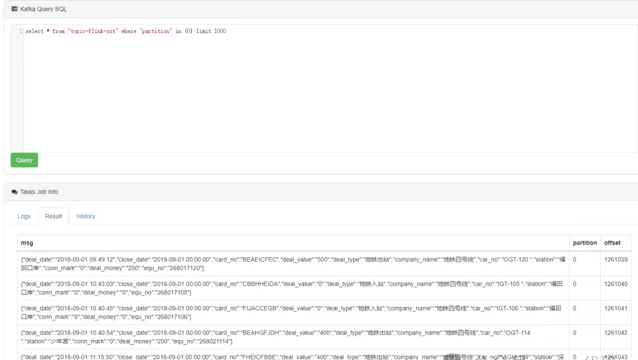
ksql 命令查询:
select * from "topic-flink-szt" where "partition" in (0) limit 1000
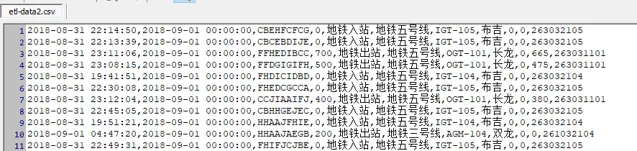
2.8- cn.java666.etlflink.app.Redis2Csv#main 实现了 flink sink csv 格式文件,并且支持按天分块保存。
2.9- cn.java666.etlflink.app.Redis2ES#main 实现了 ES 存储源数据。实现实时全文检索,实时跟踪深圳通刷卡数据。
这个模块涉及技术细节比较多,如果没有 ES 使用经验,可以先做下功课,不然的话会很懵。
这部分内容有更新:修正了上一个版本时区问题。
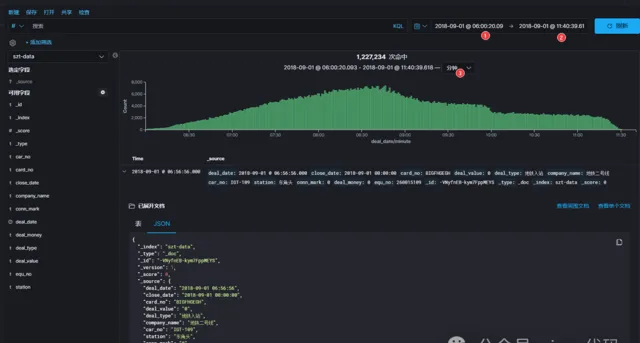
🎬接下来,让我们时光倒流,回到 2018-09-01这一天,调整 kibana 面板时间范围 2018-09-01 00:00:00.000~2018-09-01 23:59:59.999,看看当天深圳通刷卡记录的统计图曲线走向是否科学,间接验证数据源的完整性。
修正时区后统计数量,字段完整的合格源数据 1266039 条,2018-09-01全天 1229180 条。
图中可以看出 2018-09-01 这一天刷卡记录集中在上午6点~12点之间,早高峰数据比较吻合,虽然这一天是周六,高峰期不是特别明显。我们继续缩放 kibana 时间轴看看更详细的曲线:
回顾一下本项目 ETL 处理流程:
1337000 条源数据清洗去除字段不全的脏数据,剩余的合格数据条数 1266039 已经进入 ES 索引
szt-data
在 1266039 条合格数据中,有 1227234 条数据集中在 2018-09-01 这一天的上午时段;
我们暂且相信上午时段的数据是真实的,那么是否说明官方提供的数据并不是全部的当天完整刷卡数据???
如果按照上午的刷卡量来估测全天的刷卡量,考虑到是周六,那么深圳通全天的刷卡记录数据应该在 122万 X 2 左右,当然这么武断的判断方式不是程序员的风格,接下来我们用科学的大数据分析方式来研究这些数据背后的意义。
注意,ES 大坑:
ES 存数据时,带有时间字段的数据如何实时展示到 kibana 的图表面板上?需要在存入 index 之前设置字段映射。
{
"properties": {
"deal_date": {
"format": "yyyy-MM-dd HH:mm:ss",
"type": "date"
}
}
}
这里并没有指定时区信息,但是 ES 默认使用 0 时区,这个软件很坑,无法设置全局默认时区。但是很多软件产生的数据都是默认机器所在时区,国内就是东八区。因为我们的源始数据本身也没有包含时区信息,这里我不想改源数据,那就假装自己在 ES 的 0 时区。同时需要修改 kibana 默认时区为 UTC,才可以保证 kibana 索引图表时间轴正确对位。不过这并不是一个科学的解决方案。
ES 存数据时,需要使用 json 格式包装数据,不符合json 语法的纯字符无法保存;
ES 序列化复杂的 bean 对象时,如果 fastjson 报错,推荐使用 Gson
Gson 相比 fastjson:Gson 序列化能力更强,但是 反序列化时,fastjson 速度更快。
2.10- 查看 ES 数据库卡号,对比自己的深圳通地铁卡,逐渐发现了一些脱敏规律。
日志当中卡号脱敏字段密文反解猜想:
由脱敏的密文卡号反推真实卡号,因为所有卡号密文当中没有J开头的数据, 但是有A开头的数据,A != 0,而且出现了 BCDEFGHIJ 没有 K,所以猜想卡号映射关系如图!!!

类似摩斯电码解密。。。我现在还不确定这个解密方式是否正确🙄🙄🙄
2.11-
cn.java666.sztcommon.util.ParseCardNo#parse
实现了支持自动识别卡号明文和密文、一键互转功能。
cn.java666.etlspringboot.controller.CardController#get
实现了卡号明文和密文互转 REST API。

3- 搭建数仓:深圳地铁数仓建模
3.1- 第一步,分析业务
确定业务流程 ---> 声明粒度 ---> 确定维度 ---> 确定事实
3.2- 第二步,规划数仓结构
参考行业通用的数仓分层模式:ODS、DWD、DWS、ADS,虽然原始数据很简单,但是我们依然使用规范的流程设计数据仓库。
第一层:ODS 原始数据层
ods/ods_szt_data/day=2018-09-01/
# szt_szt_page/day=2018-09-01/
第二层:DWD 清洗降维层
区分维表 dim_ 和事实表 fact_,为了使粒度更加细化,我们把进站和出站记录分开,巴士数据暂不考虑。
dwd_fact_szt_in_detail 进站事实详情表
dwd_fact_szt_out_detail 出站事实详情表
dwd_fact_szt_in_out_detail 地铁进出站总表
第三层:DWS 宽表层
dws_card_record_day_wide 每卡每日行程记录宽表【单卡单日所有出行记录】
第
四层: ADS 业务指标层【待补充】
【体现进站压力】 每站进站人次排行榜
ads_in_station_day_top
【体现出站压力】 每站出站人次排行榜
ads_out_station_day_top
【体现进出站压力】 每站进出站人次排行榜
ads_in_out_station_day_top
【体现通勤车费最多】 每卡日消费排行
ads_card_deal_day_top
【体现线路运输贡献度】 每线路单日运输乘客总次数排行榜,进站算一次,出站并且联程算一次
ads_line_send_passengers_day_top
【体现利用率最高的车站区间】 每日运输乘客最多的车站区间排行榜
ads_stations_send_passengers_day_top
【体现线路的平均通勤时间,运输效率】 每条线路单程直达乘客耗时平均值排行榜
ads_line_single_ride_average_time_day_top
【体现深圳地铁全市乘客平均通勤时间】 所有乘客从上车到下车间隔时间平均值
ads_all_passengers_single_ride_spend_time_average
【体现通勤时间最长的乘客】 单日从上车到下车间隔时间排行榜
ads_passenger_spend_time_day_top
【体现车站配置】 每个站点进出站闸机数量排行榜
每个站点入站闸机数量 ads_station_in_equ_num_top
每个站点出站闸机数量 ads_station_out_equ_num_top
【体现各线路综合服务水平】 各线路进出站闸机数排行榜
各线路进站闸机数排行榜 ads_line_in_equ_num_top.png
各线路出站闸机数排行榜 ads_line_out_equ_num_top
【体现收入最多的车站】 出站交易收入排行榜
ads_station_deal_day_top
【体现收入最多的线路】 出站交易所在线路收入排行榜
ads_line_deal_day_top
【体现换乘比例、乘车体验】 每天每线路换乘出站乘客百分比排行榜
ads_conn_ratio_day_top
【体现每条线的深圳通乘车卡普及程度 9.5 折优惠】 出站交易优惠人数百分比排行榜
ads_line_sale_ratio_top
【体现换乘的心酸】 换乘耗时最久的乘客排行榜
ads_conn_spend_time_top
【体现线路拥挤程度】 上车以后还没下车,每分钟、小时每条线在线人数
ads_on_line_min_top
3.3- 第三步:建库建表计算指标
hdfs 关闭权限检查。hive 设置保存目录 /warehouse;
hue 创建 hue 用户,赋予超级组。hue 切换到 hue 用户,执行 hive sql 建库 szt;
库下面建目录 ods dwd dws ads;
上传原始数据到 /warehouse/szt.db/ods/
szt-etl-data.csv szt-etl-data_2018-09-01.csv szt-page.jsons
查看:
hdfs dfs -ls -h hdfs://cdh231:8020/warehouse/szt.db/ods/
接下来使用 HUE 按照
sql/hive.sql
依次执行 HQL 语句.....
也可以使用 IDEA Database 工具栏操作,附送idea cdh hive 完美驱动 https://github.com/timveil/hive-jdbc-uber-jar/releases:
也可以使用 DBeaver (我只想说, 上古产品 Sqlyog、navicat、heidisql、workbench 全都是战五渣),因为有时候复杂的查询可以一边执行一边在另一个客户端工具查看结果,这对于复杂的嵌套查询 debug 非常有助于分析和跟踪问题。DBeaver 客户端自带图表,不过没有 HUE 好看:
已经完成的指标分析:
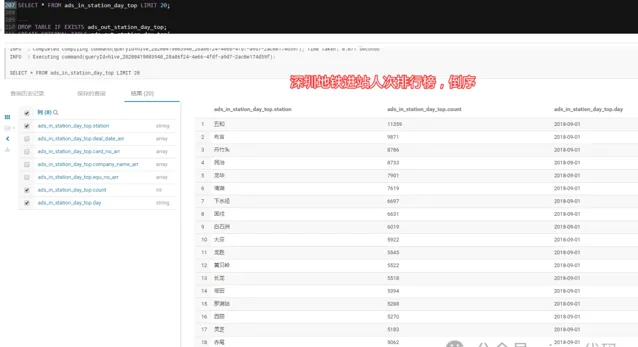
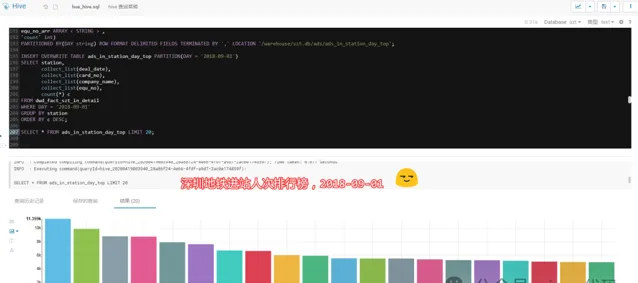
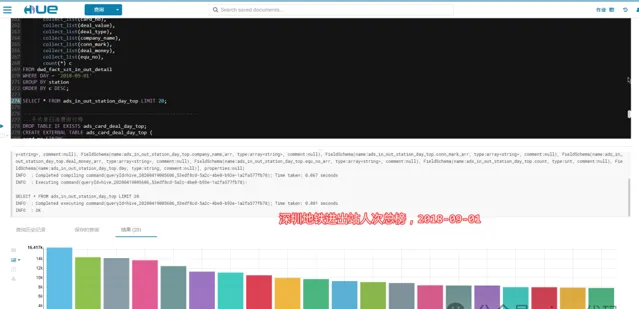
3.3.1 - 深圳地铁进站人次排行榜:
2018-09-01,当天依次为:五和、布吉、丹竹头,数据说明当天这几个站点进站人数最多。
3.3.2 - 深圳地铁出站人次排行榜:
2018-09-01,当天出站乘客主要去向分别为:深圳北高铁站、罗湖火车站、福田口岸。
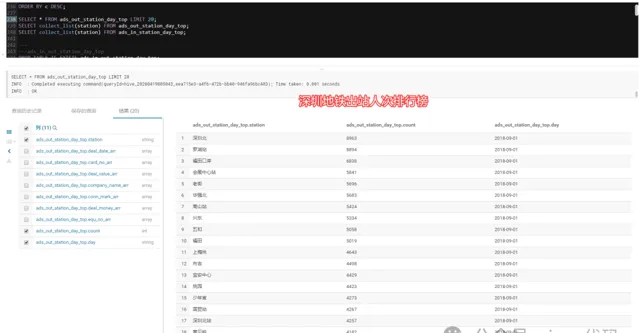
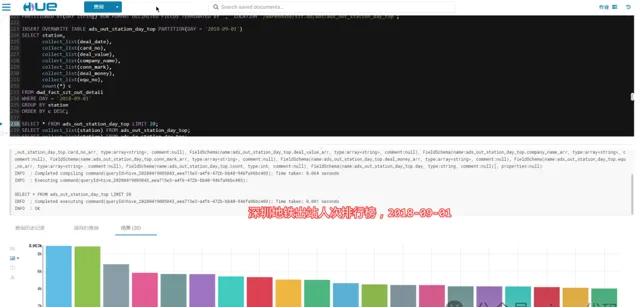
3.3.3- 深圳地铁进出站总人次排行榜:
2018-09-01,当天车站吞吐量排行榜:
五和站???、布吉站(深圳东火车站)、罗湖站(深圳火车站)、深圳北(深圳北高铁站)
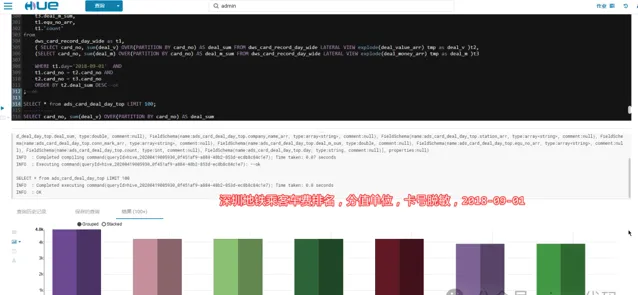
3.3.4- 深圳地铁乘客车费排行榜:
2018-09-01,当天车费最高的乘客花了 48 元人民币
🚄🚄🚄 说明:深圳通地铁卡不记名,未涉及个人隐私!!!
3.3.5- 深圳地铁各线路单日发送旅客排行榜:
2018-09-01,当天五号线客运量遥遥领先,龙岗线碾压一号线
3.3.6- 深圳地铁每日运输乘客最多的区间排行榜:
2018-09-01当天前三名分别是:赤尾>华强北,福民>福田口岸,五和>深圳北
3.3.7- 深圳地铁每条线路单程直达乘客耗时平均值排行榜:
2018-09-01,当天五号线单程直达乘客平均耗时1500s,约合25分钟,平均值最长的是 11号线,平均耗时 40 分钟
3.3.8- 深圳地铁所有乘客通勤时间平均值:
2018-09-01,当天所有乘客通勤时间平均值 1791 s,约合 30 分钟
3.3.9- 深圳地铁所有乘客通勤时间排行榜:
2018-09-01,当天所有乘客通勤时间排行榜,站内滞留最久的乘客间隔 17123 秒,约合 4.75 小时,实际情况只需要 20 分钟车程
3.3.10- 深圳地铁每个站点进出站闸机数量排行榜:
2018-09-01,当天福田站双项第一
3.3.11- 深圳地铁各线路进出站闸机数量排行榜:
2018-09-01,当天深圳地铁一号线长脸了@_@,两个指标都是第一,港铁四号线全部垫底
3.3.12- 深圳地铁各站收入排行榜:
2018-09-01,当天上午深圳北站收入 4 万元人民币,排名第一
3.3.12- 深圳地铁各线路收入排行榜:
2018-09-01,数据显示一号线依然是深圳地铁最多收入的线路,1号线上午收入 30 万元人民币,其次是五号线紧随其后
3.3.13- 深圳地铁各线路换乘出站乘客百分比排行榜:
换乘后从五号线出来的乘客是占比最高的 15.6%,从九号线出站的乘客,换乘比例最低,仅 9.42%
3.3.14- 深圳地铁各线路直达乘客优惠人次百分比排行榜:
目前可以确定的是,持有深圳通地铁卡可以享受9.5折优惠乘坐地铁,从统计结果看,2018-09-01当天,七号线使用地铁卡优惠的乘客人次占比最高,达到 90.36%,排名最低的是五号线,占比 84.3%
3.3.15- 深圳地铁换乘时间最久的乘客排行榜:
统计过程发现难以理解的现象,有几个乘客进站以后,没有刷卡出站就换乘了公交车,于是出现了同一个地铁站进出站,但是标记为联程的记录
4- 新增模块:SZT-kafka-hbase
SZT-kafka-hbase project for Spring Boot2
看过开源的 spring-boot-starter-hbase、spring-data-hadoop-hbase,基础依赖过于老旧,长期不更新;引入过程繁琐,而且 API 粒度受限;数据库连接没有复用,导致数据库服务读写成本太高。
于是自己实现了 hbase-2.1 + springboot-2.1.13 + kafka-2.0 的集成,一个长会话完成 hbase 连续的增删改查,降低服务器资源的开销。
主要特色:
knife4j 在线调试,点击鼠标即可完成 hbase 写入和查询,再也不用记住繁琐的命令。
hbase 列族版本历史设置为 10,支持配置文件级别的修改。可以查询某卡号最近 10 次交易记录。
hbase rowkey 设计为卡号反转,使得字典排序过程消耗的服务器算力在分布式环境更加均衡。
全自动的建库建表【本项目的 hbase 命名空间为 szt】,实现幂等操作,无需担心 hbase 数据库的污染。
效果展示:
准备部署完成的 hbase,适当修改本项目配置文件,运行 SZT-kafka-hbase 项目,效果如下:
启动:
api-debug,随便写点东西进去,狂点发送。
hue-hbase 查表:
hue-hbase 查看历史版本:
hbase-shell 命令:
全表扫描,返回十个版本格式化为字符串显示
scan 'szt:data', {FORMATTER => 'toString',VERSIONS=>10
接下来接入 kafka
启动
cn.java666.etlflink.app.Redis2Kafka
,生产消息,适当调慢生产速度,以免机器崩溃。
不出意外的话,你会看到 SZT-kafka-hbase 项目的控制台打印了日志:
如果 hbase 崩溃了,看看内存够不够,我就直接怼上 2GB X 3 个节点
5-
SZT-flink
模块新增
cn.java666.etlflink.app.Json2HBase
实现了从 redis 或者其他数据源取出 json 串,保存到 hbase 表。本项目中从 redis 获取 json(当然更推荐 kafka),通过 flink 清洗存到 hbase flink:flink2hbase 表中。用于实时保存深圳通刷卡记录,通过卡号查询可以获取卡号最近10次(如果有10次)交易记录。
valkeys= jsonObj.keySet().toList
valsize= keys.size()
for (i <-0 until size) {
valkey= keys.get(i)
valvalue= jsonObj.getStr(key)
putCell(card_no_re, cf, key, value)
}
6- 新增实时处理模块 SZT-flink
完成 flink 读取 kafka,存到 clickhouse 功能。
源代码下载地址:
https://github.com/geekyouth/SZT-bigdata.git
看到最后,如果这个项目对你有用,一定要给我点个「 在看和赞 」。










