项目简介
Umi-OCR是一款免费、开源的离线OCR软件,旨在为用户提供快速、高效的文本识别服务。它支持多种语言,能够处理图片、PDF文档,并具备批量识别功能。此外,软件还包括二维码的扫描和生成,以及对水印和页眉页脚的智能排除,适用于个人和企业用户。
扫码加入交流群
获得更多技术支持和交流

特点
· 免费:项目代码完全开源且免费使用。
· 易用:解压后直接使用,无需联网,支持离线操作。
· 效率:配备高效的离线OCR引擎,支持多语言文本识别。
· 灵活:提供多种使用方式,包括命令行和HTTP接口。
· 功能:集成了截图文本识别、批量处理、PDF文件识别、二维码处理及公式识别等功能。
开始使用
下载链接在文章最后
软件发布包下载为 .7z 压缩包或 .7z.exe 自解压包。自解压包可在没有安装压缩软件的电脑上,解压文件。
本软件无需安装。解压后,点击 Umi-OCR.exe 即可启动程序。
界面语言
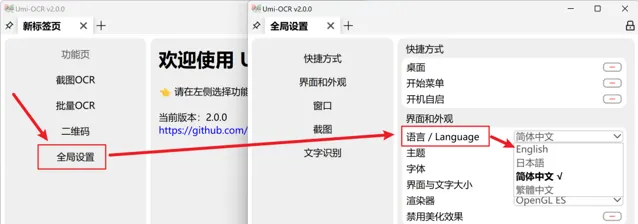
Umi-OCR支持多种界面语言,首次使用时会根据电脑系统设置自动选择语言。如需手动更改语言,可在软件的「全局设置」中找到「语言/Language」选项进行调整。
截图OCR
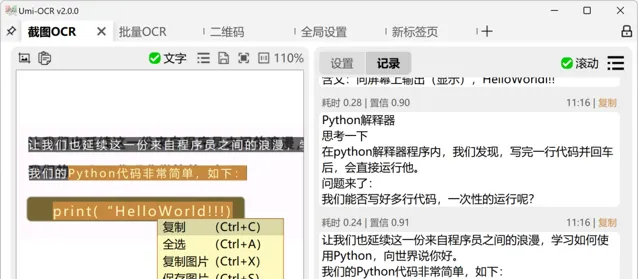
在Umi-OCR中,启用软件后可通过快捷键进行截图并识别图中文字。软件界面左侧为图片预览区,支持鼠标划选文本复制。右侧则为识别记录区,允许编辑和复制多个记录。此外,Umi-OCR还支持从其他应用复制图片后,直接粘贴到软件中进行文本识别。
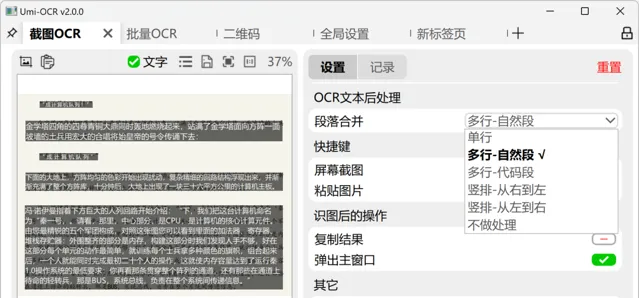
在Umi-OCR的文本后处理中,用户可以选择不同的排版解析方案以优化OCR结果,使文本更易于阅读和应用。包括适应多栏或单栏布局的不同换行规则,如按自然段换行、总是换行、或无换行。特别的,还有针对代码截图的排版保留选项,以及保持OCR引擎原始输出的选择。这些设置旨在满足不同文本排版需求,同时支持横排和竖排文本的自动处理。
批量OCR
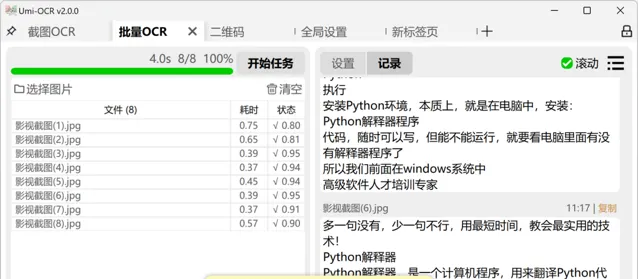
这个页面允许用户批量导入本地图片以进行识别,并支持将识别结果保存为多种文件格式,如txt、jsonl、md、csv等。它也提供文本后处理功能,用以整理OCR识别后的文本排版和顺序,同时支持设置忽略特定区域。此功能无导入数量限制,支持一次性处理大量图片,并且可设置在任务完成后自动关机或待机。
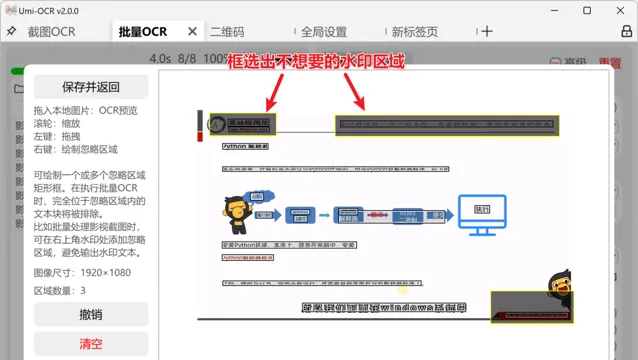
OCR文本后处理中的「忽略区域」是批量OCR功能的一部分,旨在排除不需要的文本,如水印或LOGO。用户可以通过绘制矩形框来指定图片中的忽略区域,以避免这些部分的文字干扰识别结果。设置时,确保矩形框覆盖所有潜在的干扰元素。
文档识别
· 支持导入 pdf, xps, epub, mobi, fb2, cbz 格式的文件。
· 对扫描件进行OCR,或提取原有文本。可输出为 双层可搜索PDF 。
· 支持设定 忽略区域 ,可用于排除页眉页脚的文字。
· 可设置任务完成后 自动关机/休眠 。
项目链接
https://github.com/hiroi-sora/Umi-OCR
关注「 开源AI项目落地 」公众号











