
反向 ETL 是将数据从数据仓库或数据湖移回到操作系统、应用程序或其他数据源的过程。「反向 ETL」一词可能看起来令人困惑,因为传统的 ETL(提取、转换、加载)涉及从源系统提取数据、出于分析目的对其进行转换,然后将其加载到数据仓库或数据湖中。
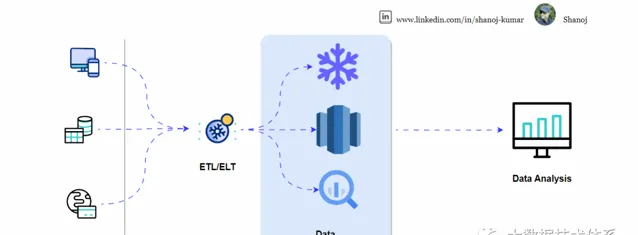
传统 ETL 与反向 ETL
| 传统ETL | 反向ETL |
| 提取:从各种操作源系统(如数据库、CRM、ERP等)提取数据。 | 从已经在数据仓库或数据湖中的数据开始(通常是在清理转换和丰富之后)。 |
| 变换: 然后将这些数据进行转换 (清理、丰富、重组),使其适合于分析。 | 然后将这些数据推(或「加载」)回操作系统、SaaS应用程序或其他数据源。 |
| 加载:转换后的数据被加载到数据仓库或数据湖中,用于分析查询和报告 | 其目的通常是使用在数据仓库中执行的高级分析、转换或聚合来增强或更新操作系统。 |
传统的 ETL 包括:
从数据库、CRM 和 ERP 等运营源系统中提取数据。
转换这些数据以进行分析,使其更清晰、更有条理。
将优化的数据加载到数据仓库或数据湖中,以进行高级分析查询和报告。
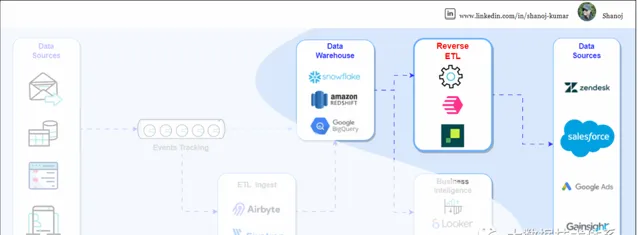
与传统的 ETL 不同,在传统 ETL 中,数据从源系统中提取、转换并加载到数据仓库中,而反向 ETL 的运行方式不同。它从数据仓库或数据湖中已存在的转换数据开始。从这里开始,该过程将这些增强的数据推送回各种操作系统、SaaS 应用程序或其他数据源。反向 ETL 的主要目标是利用来自数据仓库的见解来更新或增强这些操作系统。
为什么要反向 ETL?
一些关键趋势正在推动反向 ETL 的采用:
现代数据仓库: Snowflake、BigQuery 和 Redshift 等平台可以更轻松地集中数据。
运营分析:
一旦数据集中并收集到见解,下一步就是将这些见解付诸实施,将它们推回应用和系统中。
SaaS 热潮:
SaaS 工具的爆炸式增长意味着跨应用程序的数据同步比以往任何时候都更加重要。
反向 ETL 的应用
反向 ETL 不仅仅是一个花哨的概念,它还具有可以改变业务运营的实际应用。以下是三个有效的用例:
1. 客户数据同步: 想象一下,一个组织使用 Salesforce (CRM)、HubSpot(营销)和 Zendesk(支持)等多个平台。每个平台都在孤岛中收集数据。借助反向 ETL,可以将统一的客户档案从数据仓库推送到每个平台,从而确保所有部门对客户都有一致的了解。
2. 操作机器学习模型: 电子商务企业经常使用 ML 模型来预测客户流失等趋势。借助反向 ETL,在集中式数据环境中做出的预测可以直接推送到营销工具。这样就可以在没有手动数据传输的情况下进行有针对性的营销工作。
3. 库存和供应链管理: 对于制造商来说,库存水平、销售预测和销售数据等关键数据可以集中在数据仓库中。分析后,可以使用反向 ETL 将这些数据推送回 ERP 系统,确保运营决策有数据支持。
需要考虑的挑战
反向 ETL 无疑是有价值的,但它也带来了一定的挑战。仓库中的数据刷新率不一致,有些表每天更新一次,有些表可能每年更新一次。此外,某些进程偶尔会运行,并且可能会在数据管理中进行手动干预。因此,在开始反向 ETL 之旅之前,必须深入了解源数据的特征和性质。
总结
反向 ETL 方法已经使用了一段时间,但直到最近才获得正式认可。Census、Hightouch 和 Grouparoo 等专用反向 ETL 工具的日益普及表明了其日益增长的重要性。如果实施得当,它可以显著改善运营并提供有价值的数据见解。对于希望简化流程并从数据中获得更深入见解的企业来说,这使其成为游戏规则的改变者。
来源丨公众号:大数据技术体系(ID:BigDataTechStack)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱: [email protected]












