最近,OpenAI 把自己的语音识别项目 Whisper 开源了,声称能把视频和语音文件转换成文字。
听说效果能和科大讯飞那些收费产品一较高下,而且最妙的是,这玩意儿不需要 GPU,家用电脑就能跑!
我是个折腾爱好者,尤其对这种开源项目兴趣满满。官方文档固然详细,但我这次打算走个捷径,找到了一个基于 Whisper 的 web 服务项目,直接用 Docker 部署,听起来是不是很酷?
下载镜像
在 Docker 里搜索 openai-whisper-asr-webservice,拉下第一个镜像。
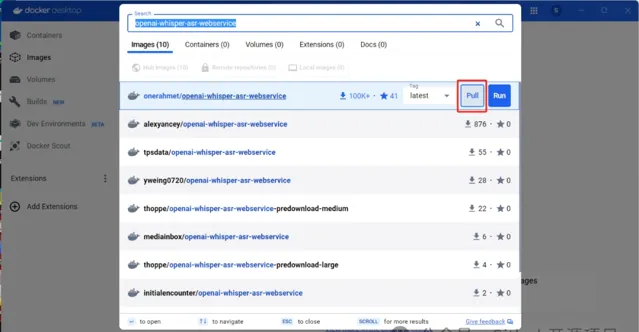
启动服务
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest
运行完毕后,打开浏览器访问 http://localhost:9000/,初次访问会下载模型,稍等片刻后,就能看到部署成功的页面,简单至极!
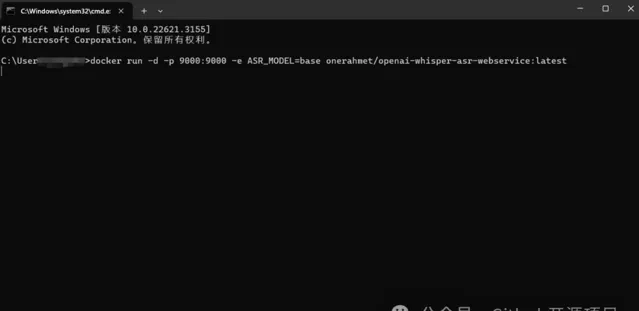
开始使用
提供了两个 HTTP 接口:语音识别和语言检测。语音识别接口,上传文件后转换成文字;语言检测接口,则是识别上传文件的语言类型。
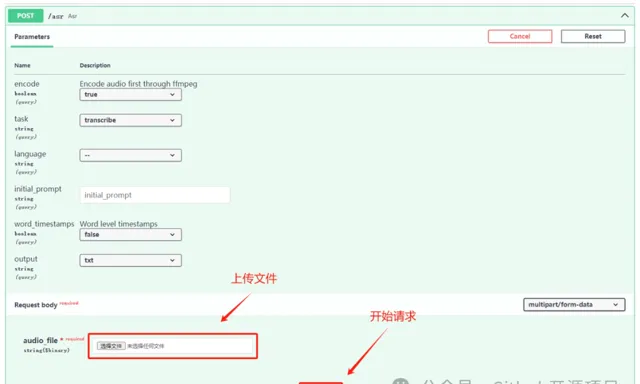
音/视频转文字
试了下英文音频,上传后点击执行,一会儿工夫就看到了转换结果。
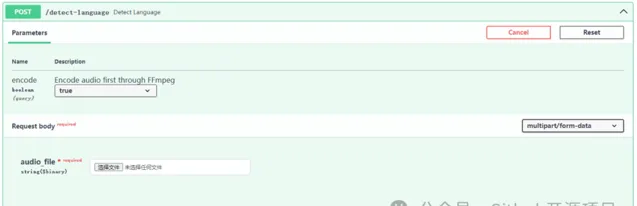
语言检测
还能检测视频或音频文件里的语言类型,这对于多语言文件也是非常友好的。
最后
用 Whisper,我在家里就能把各种语音视频文件变成文字,无论是制作字幕还是整理访谈记录,都变得轻而易举。最关键的是,这一切都是开源免费的,简直太棒了!
而且,通过 Docker 部署这个 web 服务项目,整个过程简单到让人惊讶。只要几步操作,就能搭建起一个功能强大的语音识别服务,这在我看来,无疑是开源世界的又一次伟大胜利。
由于有些小伙伴网络问题,导致下载不了,这里我已经整理到网盘了。
链接地址: https://www.j301.cn/blog/github_ai_tool_whisper.html
点击下方公众号,回复关键字: github , 获取 Github开源项目合集 !

点分享
点收藏
点点赞
点在看











