先看效果
人脸增强
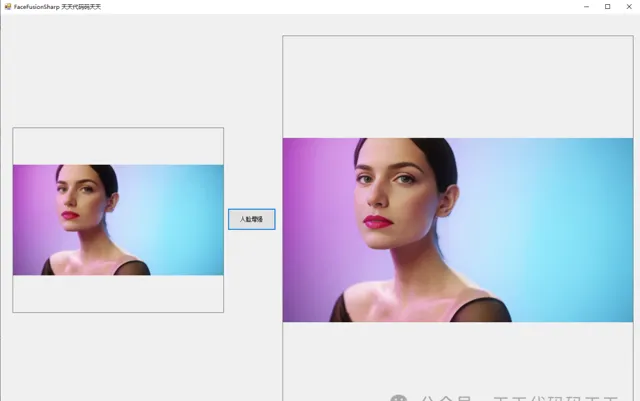
说明
C#版Facefusion一共有如下5个步骤:
1、使用yoloface_8n.onnx进行人脸检测
2、使用2dfan4.onnx获取人脸关键点
3、使用arcface_w600k_r50.onnx获取人脸特征值
4、使用inswapper_128.onnx进行人脸替换
5、使用gfpgan_1.4.onnx进行人脸增强
本文分享使用gfpgan_1.4.onnx实现C#版Facefusion第五步:人脸增强。
到此人脸替换就全部完成了。
顺便再看一下C++、Python代码的实现方式,可以对比学习。
回顾:
模型信息
Inputs
-------------------------
name:input
tensor:Float[1, 3, 512, 512]
---------------------------------------------------------------
Outputs
-------------------------
name:output
tensor:Float[1, 3, 512, 512]
---------------------------------------------------------------
代码
调用代码
using Newtonsoft.Json;
using OpenCvSharp;
using OpenCvSharp.Extensions;
using System;
using System.Collections.Generic;
using System.Drawing;
using System.Windows.Forms;
namespace FaceFusionSharp
{
public partial class Form5 : Form
{
public Form5()
{
InitializeComponent();
}
string source_path = "";
FaceEnhance enhance_face;
private void button1_Click(object sender, EventArgs e)
{
if (pictureBox1.Image == null)
{
return;
}
pictureBox3.Image = null;
button1.Enabled = false;
Application.DoEvents();
Mat source_img = Cv2.ImRead(source_path);
List<Point2f> target_landmark_5 = new List<Point2f>();
string target_landmark_5Str = "[{\"X\":485.602539,\"Y\":247.84906},{\"X\":704.237549,\"Y\":247.422546},{\"X\":527.5082,\"Y\":360.211731},{\"X\":485.430084,\"Y\":495.7987},{\"X\":647.741638,\"Y\":505.131042}]";
target_landmark_5 = JsonConvert.DeserializeObject<List<Point2f>>(target_landmark_5Str);
Mat resultimg = enhance_face.process(source_img, target_landmark_5);
pictureBox3.Image = resultimg.ToBitmap();
button1.Enabled = true;
}
private void Form1_Load(object sender, EventArgs e)
{
enhance_face = new FaceEnhance("model/gfpgan_1.4.onnx");
source_path = "images/swapimg.jpg";
pictureBox1.Image = new Bitmap(source_path);
}
}
}
FaceEnhance.cs
using Microsoft.ML.OnnxRuntime;
using Microsoft.ML.OnnxRuntime.Tensors;
using OpenCvSharp;
using System;
using System.Collections.Generic;
using System.Linq;
namespace FaceFusionSharp
{
internal class FaceEnhance
{
float[] input_image;
int input_height;
int input_width;
List<Point2f> normed_template;
float FACE_MASK_BLUR = 0.3f;
int[] FACE_MASK_PADDING = new int[4] { 0, 0, 0, 0 };
SessionOptions options;
InferenceSession onnx_session;
public FaceEnhance(string modelpath)
{
input_height = 512;
input_width = 512;
options = new SessionOptions();
options.LogSeverityLevel = OrtLoggingLevel.ORT_LOGGING_LEVEL_INFO;
options.AppendExecutionProvider_CPU(0);// 设置为CPU上运行
// 创建推理模型类,读取本地模型文件
onnx_session = new InferenceSession(modelpath, options);//model_path 为onnx模型文件的路径
//在这里就直接定义了,没有像python程序里的那样normed_template = TEMPLATES.get(template) * crop_size
normed_template = new List<Point2f>();
normed_template.Add(new Point2f(192.98138112f, 239.94707968f));
normed_template.Add(new Point2f(318.90276864f, 240.19360256f));
normed_template.Add(new Point2f(256.63415808f, 314.01934848f));
normed_template.Add(new Point2f(201.26116864f, 371.410432f));
normed_template.Add(new Point2f(313.0890496f, 371.1511808f));
}
void preprocess(Mat srcimg, List<Point2f> face_landmark_5, ref Mat affine_matrix, ref Mat box_mask)
{
Mat crop_img = new Mat();
affine_matrix = Common.warp_face_by_face_landmark_5(srcimg, crop_img, face_landmark_5, normed_template, new Size(512, 512));
int[] crop_size = new int[] { crop_img.Cols, crop_img.Rows };
box_mask = Common.create_static_box_mask(crop_size, FACE_MASK_BLUR, FACE_MASK_PADDING);
Mat[] bgrChannels = Cv2.Split(crop_img);
for (int c = 0; c < 3; c++)
{
bgrChannels[c].ConvertTo(bgrChannels[c], MatType.CV_32FC1, 1 / (255.0 * 0.5), -1.0);
}
Cv2.Merge(bgrChannels, crop_img);
foreach (Mat channel in bgrChannels)
{
channel.Dispose();
}
input_image = Common.ExtractMat(crop_img);
crop_img.Dispose();
}
internal Mat process(Mat target_img, List<Point2f> target_landmark_5)
{
Mat affine_matrix = new Mat();
Mat box_mask = new Mat();
preprocess(target_img, target_landmark_5, ref affine_matrix, ref box_mask);
Tensor<float> input_tensor = new DenseTensor<float>(input_image, new[] { 1, 3, input_height, input_width });
List<NamedOnnxValue> input_container = new List<NamedOnnxValue>
{
NamedOnnxValue.CreateFromTensor("input", input_tensor)
};
var ort_outputs = onnx_session.Run(input_container).ToArray();
float[] pdata = ort_outputs[0].AsTensor<float>().ToArray();
int out_h = 512;
int out_w = 512;
int channel_step = out_h * out_w;
for (int i = 0; i < pdata.Length; i++)
{
pdata[i] = (pdata[i] + 1) * 0.5f;
if (pdata[i] < -1)
{
pdata[i] = -1;
}
if (pdata[i] > 1)
{
pdata[i] = 1;
}
pdata[i] = pdata[i] * 255.0f;
if (pdata[i] < 0)
{
pdata[i] = 0;
}
if (pdata[i] > 255)
{
pdata[i] = 255;
}
}
float[] temp_r = new float[channel_step];
float[] temp_g = new float[channel_step];
float[] temp_b = new float[channel_step];
Array.Copy(pdata, temp_r, channel_step);
Array.Copy(pdata, channel_step, temp_g, 0, channel_step);
Array.Copy(pdata, channel_step * 2, temp_b, 0, channel_step);
Mat rmat = new Mat(out_h, out_w, MatType.CV_32FC1, temp_r);
Mat gmat = new Mat(out_h, out_w, MatType.CV_32FC1, temp_g);
Mat bmat = new Mat(out_h, out_w, MatType.CV_32FC1, temp_b);
Mat result = new Mat();
Cv2.Merge(new Mat[] { bmat, gmat, rmat }, result);
result.ConvertTo(result, MatType.CV_8UC3);
float[] box_mask_data;
box_mask.GetArray<float>(out box_mask_data);
int cols = box_mask.Cols;
int rows = box_mask.Rows;
MatType matType = box_mask.Type();
for (int i = 0; i < box_mask_data.Length; i++)
{
if (box_mask_data[i] < 0)
{
box_mask_data[i] = 0;
}
if (box_mask_data[i] > 1)
{
box_mask_data[i] = 1;
}
}
box_mask = new Mat(rows, cols, matType, box_mask_data);
Mat paste_frame = Common.paste_back(target_img, result, box_mask, affine_matrix);
Mat dstimg = Common.blend_frame(target_img, paste_frame);
return dstimg;
}
}
}
C++代码
我们顺便看一下C++代码的实现,方便对比学习。
头文件
# ifndef FACEENHANCE
# define FACEENHANCE
#include <fstream>
#include <sstream>
#include "opencv2/opencv.hpp"
//#include <cuda_provider_factory.h> ///如果使用cuda加速,需要取消注释
#include <onnxruntime_cxx_api.h>
#include"utils.h"
class FaceEnhance
{
public:
FaceEnhance(std::string modelpath);
cv::Mat process(cv::Mat target_img, const std::vector<cv::Point2f> target_landmark_5);
private:
void preprocess(cv::Mat target_img, const std::vector<cv::Point2f> face_landmark_5, cv::Mat& affine_matrix, cv::Mat& box_mask);
std::vector<float> input_image;
int input_height;
int input_width;
std::vector<cv::Point2f> normed_template;
const float FACE_MASK_BLUR = 0.3;
const int FACE_MASK_PADDING[4] = {0, 0, 0, 0};
Ort::Env env = Ort::Env(ORT_LOGGING_LEVEL_ERROR, "Face Enhance");
Ort::Session *ort_session = nullptr;
Ort::SessionOptions sessionOptions = Ort::SessionOptions();
std::vector<char*> input_names;
std::vector<char*> output_names;
std::vector<std::vector<int64_t>> input_node_dims; // >=1 outputs
std::vector<std::vector<int64_t>> output_node_dims; // >=1 outputs
Ort::MemoryInfo memory_info_handler = Ort::MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
};
#endif
源文件
#include"faceenhancer.h"
using namespace cv;
using namespace std;
using namespace Ort;
FaceEnhance::FaceEnhance(string model_path)
{
/// OrtStatus* status = OrtSessionOptionsAppendExecutionProvider_CUDA(sessionOptions, 0); ///如果使用cuda加速,需要取消注释
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_BASIC);
/// std::wstring widestr = std::wstring(model_path.begin(), model_path.end()); ////windows写法
/// ort_session = new Session(env, widestr.c_str(), sessionOptions); ////windows写法
ort_session = new Session(env, model_path.c_str(), sessionOptions); ////linux写法
size_t numInputNodes = ort_session->GetInputCount();
size_t numOutputNodes = ort_session->GetOutputCount();
AllocatorWithDefaultOptions allocator;
for (int i = 0; i < numInputNodes; i++)
{
input_names.push_back(ort_session->GetInputName(i, allocator)); /// 低版本onnxruntime的接口函数
////AllocatedStringPtr input_name_Ptr = ort_session->GetInputNameAllocated(i, allocator); /// 高版本onnxruntime的接口函数
////input_names.push_back(input_name_Ptr.get()); /// 高版本onnxruntime的接口函数
Ort::TypeInfo input_type_info = ort_session->GetInputTypeInfo(i);
auto input_tensor_info = input_type_info.GetTensorTypeAndShapeInfo();
auto input_dims = input_tensor_info.GetShape();
input_node_dims.push_back(input_dims);
}
for (int i = 0; i < numOutputNodes; i++)
{
output_names.push_back(ort_session->GetOutputName(i, allocator)); /// 低版本onnxruntime的接口函数
////AllocatedStringPtr output_name_Ptr= ort_session->GetInputNameAllocated(i, allocator);
////output_names.push_back(output_name_Ptr.get()); /// 高版本onnxruntime的接口函数
Ort::TypeInfo output_type_info = ort_session->GetOutputTypeInfo(i);
auto output_tensor_info = output_type_info.GetTensorTypeAndShapeInfo();
auto output_dims = output_tensor_info.GetShape();
output_node_dims.push_back(output_dims);
}
this->input_height = input_node_dims[0][2];
this->input_width = input_node_dims[0][3];
////在这里就直接定义了,没有像python程序里的那样normed_template = TEMPLATES.get(template) * crop_size
this->normed_template.emplace_back(Point2f(192.98138112, 239.94707968));
this->normed_template.emplace_back(Point2f(318.90276864, 240.19360256));
this->normed_template.emplace_back(Point2f(256.63415808, 314.01934848));
this->normed_template.emplace_back(Point2f(201.26116864, 371.410432));
this->normed_template.emplace_back(Point2f(313.0890496, 371.1511808));
}
void FaceEnhance::preprocess(Mat srcimg, const vector<Point2f> face_landmark_5, Mat& affine_matrix, Mat& box_mask)
{
Mat crop_img;
affine_matrix = warp_face_by_face_landmark_5(srcimg, crop_img, face_landmark_5, this->normed_template, Size(512, 512));
const int crop_size[2] = {crop_img.cols, crop_img.rows};
box_mask = create_static_box_mask(crop_size, this->FACE_MASK_BLUR, this->FACE_MASK_PADDING);
vector<cv::Mat> bgrChannels(3);
split(crop_img, bgrChannels);
for (int c = 0; c < 3; c++)
{
bgrChannels[c].convertTo(bgrChannels[c], CV_32FC1, 1 / (255.0*0.5), -1.0);
}
const int image_area = this->input_height * this->input_width;
this->input_image.resize(3 * image_area);
size_t single_chn_size = image_area * sizeof(float);
memcpy(this->input_image.data(), (float *)bgrChannels[2].data, single_chn_size); ///rgb顺序
memcpy(this->input_image.data() + image_area, (float *)bgrChannels[1].data, single_chn_size);
memcpy(this->input_image.data() + image_area * 2, (float *)bgrChannels[0].data, single_chn_size);
}
Mat FaceEnhance::process(Mat target_img, const vector<Point2f> target_landmark_5)
{
Mat affine_matrix;
Mat box_mask;
this->preprocess(target_img, target_landmark_5, affine_matrix, box_mask);
std::vector<int64_t> input_img_shape = {1, 3, this->input_height, this->input_width};
Value input_tensor_ = Value::CreateTensor<float>(memory_info_handler, this->input_image.data(), this->input_image.size(), input_img_shape.data(), input_img_shape.size());
Ort::RunOptions runOptions;
vector<Value> ort_outputs = this->ort_session->Run(runOptions, this->input_names.data(), &input_tensor_, 1, this->output_names.data(), output_names.size());
float* pdata = ort_outputs[0].GetTensorMutableData<float>();
std::vector<int64_t> outs_shape = ort_outputs[0].GetTensorTypeAndShapeInfo().GetShape();
const int out_h = outs_shape[2];
const int out_w = outs_shape[3];
const int channel_step = out_h * out_w;
Mat rmat(out_h, out_w, CV_32FC1, pdata);
Mat gmat(out_h, out_w, CV_32FC1, pdata + channel_step);
Mat bmat(out_h, out_w, CV_32FC1, pdata + 2 * channel_step);
rmat.setTo(-1, rmat < -1);
rmat.setTo(1, rmat > 1);
rmat = (rmat+1)*0.5;
gmat.setTo(-1, gmat < -1);
gmat.setTo(1, gmat > 1);
gmat = (gmat+1)*0.5;
bmat.setTo(-1, bmat < -1);
bmat.setTo(1, bmat > 1);
bmat = (bmat+1)*0.5;
rmat *= 255.f;
gmat *= 255.f;
bmat *= 255.f;
rmat.setTo(0, rmat < 0);
rmat.setTo(255, rmat > 255);
gmat.setTo(0, gmat < 0);
gmat.setTo(255, gmat > 255);
bmat.setTo(0, bmat < 0);
bmat.setTo(255, bmat > 255);
vector<Mat> channel_mats(3);
channel_mats[0] = bmat;
channel_mats[1] = gmat;
channel_mats[2] = rmat;
Mat result;
merge(channel_mats, result);
result.convertTo(result, CV_8UC3);
box_mask.setTo(0, box_mask < 0);
box_mask.setTo(1, box_mask > 1);
Mat paste_frame = paste_back(target_img, result, box_mask, affine_matrix);
Mat dstimg = blend_frame(target_img, paste_frame);
return dstimg;
}
Python代码
import numpy as np
import onnxruntime
from utils import warp_face_by_face_landmark_5, create_static_box_mask, paste_back, blend_frame
FACE_MASK_BLUR = 0.3
FACE_MASK_PADDING = (0, 0, 0, 0)
class enhance_face:
def __init__(self, modelpath):
# Initialize model
session_option = onnxruntime.SessionOptions()
session_option.log_severity_level = 3
# self.session = onnxruntime.InferenceSession(modelpath, providers=['CUDAExecutionProvider', 'CPUExecutionProvider'])
self.session = onnxruntime.InferenceSession(modelpath, sess_options=session_option) ###opencv-dnn读取onnx失败
model_inputs = self.session.get_inputs()
self.input_names = [model_inputs[i].name for i in range(len(model_inputs))]
self.input_shape = model_inputs[0].shape
self.input_height = int(self.input_shape[2])
self.input_width = int(self.input_shape[3])
def process(self, target_img, target_landmark_5):
###preprocess
crop_img, affine_matrix = warp_face_by_face_landmark_5(target_img, target_landmark_5, 'ffhq_512', (512, 512))
box_mask = create_static_box_mask((crop_img.shape[1],crop_img.shape[0]), FACE_MASK_BLUR, FACE_MASK_PADDING)
crop_mask_list = [box_mask]
crop_img = crop_img[:, :, ::-1].astype(np.float32) / 255.0
crop_img = (crop_img - 0.5) / 0.5
crop_img = np.expand_dims(crop_img.transpose(2, 0, 1), axis = 0).astype(np.float32)
###Perform inference on the image
result = self.session.run(None, {'input':crop_img})[0][0]
###normalize_crop_frame
result = np.clip(result, -1, 1)
result = (result + 1) / 2
result = result.transpose(1, 2, 0)
result = (result * 255.0).round()
result = result.astype(np.uint8)[:, :, ::-1]
crop_mask = np.minimum.reduce(crop_mask_list).clip(0, 1)
paste_frame = paste_back(target_img, result, crop_mask, affine_matrix)
dstimg = blend_frame(target_img, paste_frame)
return dstimg
其他
【C#版Facefusion:让你的脸与世界融为一体!】中的Demo程序已经在QQ群(758616458)中分享,需要的可以去QQ群文件中下载体验。
模型下载
https://docs.facefusion.io/introduction/license#models











