点击「 IT码徒 」, 关注,置顶 公众号
每日技术干货,第一时间送达!
开发目的:
提高百万级数据插入效率。
采取方案:
利用
ThreadPoolTaskExecutor
多线程批量插入。
采用技术:
springboot2.1.1
mybatisPlus3.0.6
swagger2.5.0
Lombok1.18.4
postgresql
ThreadPoolTaskExecutor
具体实现细节
application-dev.properties
添加线程池配置信息
# 异步线程配置
# 配置核心线程数
async.executor.thread.core_pool_size = 30
# 配置最大线程数
async.executor.thread.max_pool_size = 30
# 配置队列大小
async.executor.thread.queue_capacity = 99988
# 配置线程池中的线程的名称前缀
async.executor.thread.name.prefix = async-importDB-
spring容器注入线程池bean对象
@Configuration
@EnableAsync
@Slf4j
public classExecutorConfig{
@Value("${async.executor.thread.core_pool_size}")
privateint corePoolSize;
@Value("${async.executor.thread.max_pool_size}")
privateint maxPoolSize;
@Value("${async.executor.thread.queue_capacity}")
privateint queueCapacity;
@Value("${async.executor.thread.name.prefix}")
private String namePrefix;
@Bean(name = "asyncServiceExecutor")
public Executor asyncServiceExecutor(){
log.warn("start asyncServiceExecutor");
//在这里修改
ThreadPoolTaskExecutor executor = new VisiableThreadPoolTaskExecutor();
//配置核心线程数
executor.setCorePoolSize(corePoolSize);
//配置最大线程数
executor.setMaxPoolSize(maxPoolSize);
//配置队列大小
executor.setQueueCapacity(queueCapacity);
//配置线程池中的线程的名称前缀
executor.setThreadNamePrefix(namePrefix);
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CALLER_RUNS:不在新线程中执行任务,而是有调用者所在的线程来执行
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//执行初始化
executor.initialize();
return executor;
}
}
创建异步线程 业务类
@Service
@Slf4j
public classAsyncServiceImplimplementsAsyncService{
@Override
@Async("asyncServiceExecutor")
publicvoidexecuteAsync(List<LogOutputResult> logOutputResults, LogOutputResultMapper logOutputResultMapper, CountDownLatch countDownLatch){
try{
log.warn("start executeAsync");
//异步线程要做的事情
logOutputResultMapper.addLogOutputResultBatch(logOutputResults);
log.warn("end executeAsync");
}finally {
countDownLatch.countDown();// 很关键, 无论上面程序是否异常必须执行countDown,否则await无法释放
}
}
}
创建多线程批量插入具体业务方法
@Override
publicinttestMultiThread(){
List<LogOutputResult> logOutputResults = getTestData();
//测试每100条数据插入开一个线程
List<List<LogOutputResult>> lists = ConvertHandler.splitList(logOutputResults, 100);
CountDownLatch countDownLatch = new CountDownLatch(lists.size());
for (List<LogOutputResult> listSub:lists) {
asyncService.executeAsync(listSub, logOutputResultMapper,countDownLatch);
}
try {
countDownLatch.await(); //保证之前的所有的线程都执行完成,才会走下面的;
// 这样就可以在下面拿到所有线程执行完的集合结果
} catch (Exception e) {
log.error("阻塞异常:"+e.getMessage());
}
return logOutputResults.size();
}
模拟2000003 条数据进行测试
多线程 测试 2000003 耗时如下:耗时1.67分钟
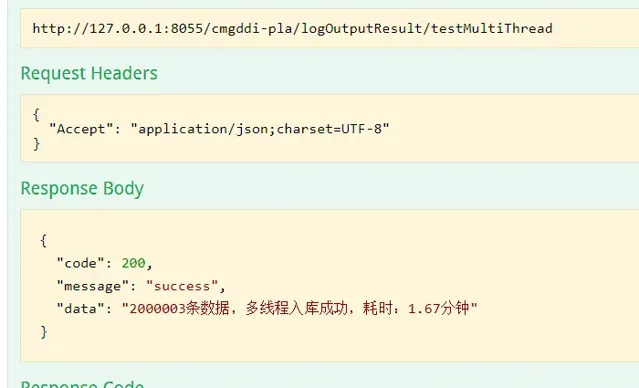

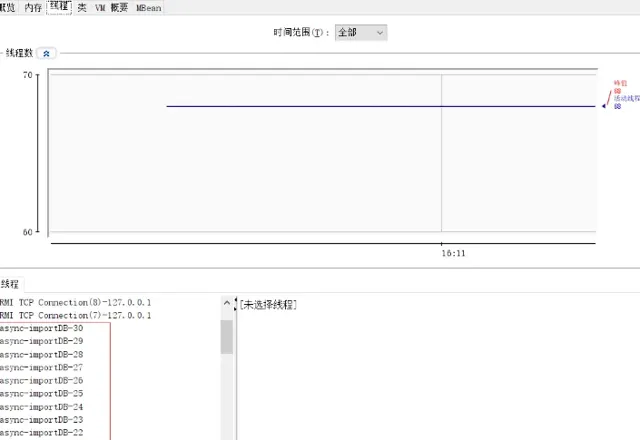
本次开启30个线程,截图如下:
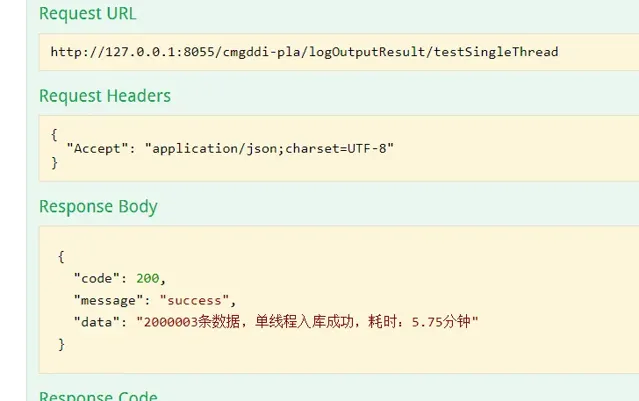
单线程测试2000003 耗时如下:耗时5.75分钟

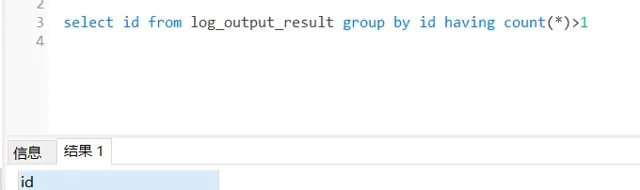
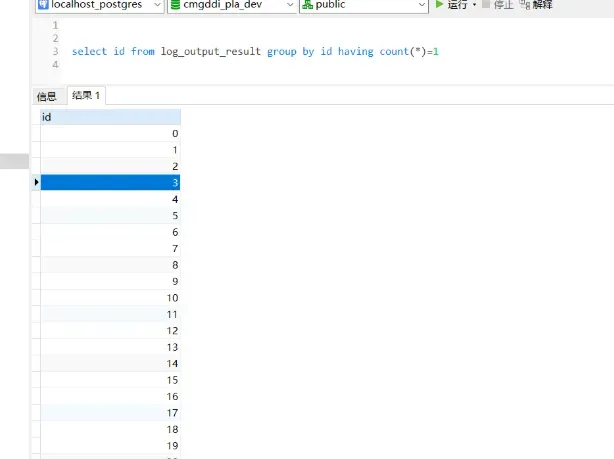
检查多线程入库的数据,检查是否存在重复入库的问题:
根据id分组,查看是否有id重复的数据,通过sql语句检查,没有发现重复入库的问题
检查数据完整性:
通过sql语句查询,多线程录入数据完整
测试结果
不同线程数测试:


总结
通过以上测试案列,同样是导入2000003 条数据,多线程耗时1.67分钟,单线程耗时5.75分钟。通过对不同线程数的测试,发现不是线程数越多越好,具体多少合适,网上有一个不成文的算法:
CPU核心数量*2 +2 个线程。
来源:azdebug.blog.csdn.net/article/details/
— END —
PS:防止找不到本篇文章,可以收藏点赞,方便翻阅查找哦。
往期推荐











