
视频生成模型又有新进展啦!!
由浙大联合阿里推出的框架—— MovieDreamer !
MovieDreamer实现了高质量、 长时段 的 连续性 视频生成,这对于AI电影等长篇视频制作十分有意义!

扫码加入AI交流群
获得更多技术支持和交流

项目简介
传统的视频生成方法在短视频内容上取得了一定成果,但在处理复杂叙事和角色一致性上依然表现不好。
这些方法往往无法对复杂的叙事进行建模,也无法在较长时间内保持角色的一致性,而这对于电影等长篇视频制作至关重要。
MovieDreamer将自回归模型的优势与基于扩散的渲染相结合,开创了具有 复杂情节发展 和 高视觉保真度 的 长时 视频生成。
Demo
下面均是由MovieDreamer结合现有长视频生成方法所生成的视频片段。
MovieDreamer➕Luma
MovieDreamer➕their model
能够看出这些视频的前后人物相关性以及叙事连贯性都十分优秀,至少能够让观众感受到故事的存在。👏
下面是MovieDreamer在视频生成中的人物的细节图,可以说小编已经真真假假分不清是真人还是AI啦。🤔




技术原理
扩散模型在处理复杂逻辑和长时段叙事方面表现欠佳,但 自回归 模型在处理 复杂推理和预测未来事件 方面具有明显优势。
MovieDreamer利用自回归模型预测视觉令牌序列,通过扩散渲染将这些令牌转换为高质量的视频帧。
其中自回归模型将 多模态 脚本作为输入,并预测关键帧的标记。
然后将这些标记渲染成图像,形成用于扩展视频生成的锚帧。
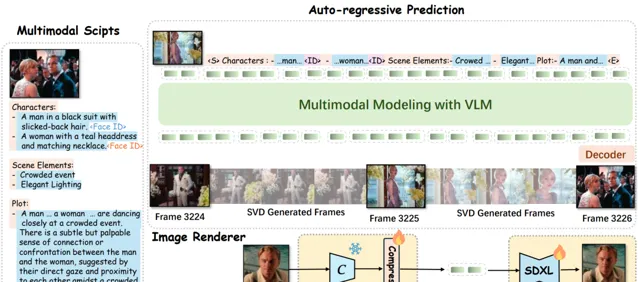
大家可以理解为传统的电影制作过程,将复杂的故事分解为易于管理的场景拍摄,确保叙事的一致性和角色身份的连贯性。
通过保留ID的渲染器显著增强了角色的感知身份。

并且MovieDreamer能够在 小样本 场景中生成具有更好 ID的结果。

由此MovieDreamer能够零样本下在 长时间跨度内保留角色身份 。

MovieDreamer在与其他方法的比较中也能够达到突出的高质量效果。

MovieDreamer框架实现了高质量的视觉叙事,突破了短视频生成的局限,为将来的 自动化电影制作 开辟了道路。
也许未来我们看到的许多影片都将由AI来生成,这样演员是不是就轻松了许多呢??
🔗 项目链接 :
https://aim-uofa.github.io/MovieDreamer
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 AGI光年 」公众号
获取每日最新咨询
更多AI信息,尽在www.dongaigc.com










