大模型的强大能力给我们的现在的生活带来了许多便利,但全球的研究人员们没有就此止步~
因为AGI的实现是我们的最终目标!🎯
今天给大家介绍的模型无疑为AGI的未来打下了深厚的基础。
它就是由Meta公司FAIR团队研发的多模态模型—— Chameleon !
Chameleon是一款能够 理解和生成任意序列的图像和文本 的 混合多模态 模型。
用户可以输入一个文本提示,要求生成一系列相关图像和描述。

扫码加入AI交流群
获得更多技术支持和交流

项目简介
多模态基础模型由于能处理更加复杂多变的任务得到了广泛的应用。
然而,当前的多模态模型仍然倾向于分开处理不同的模态,使用模态特定的编码器或解码器。
这种做法限制了模型跨模态整合信息和生成包含任意序列图像和文本的多模态文档的能力。
作为能够理解和生成任意序列图像和文本的混合模态模型的Chameleon可谓是这一技术突破的启明灯✨
Demo
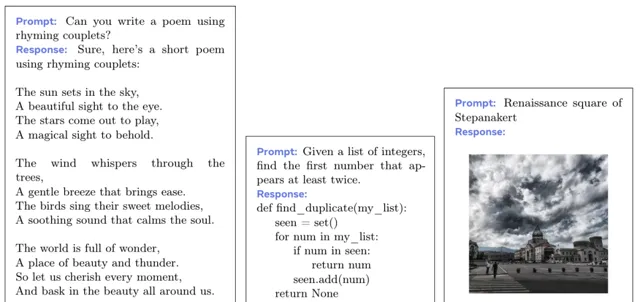
下面展示了通过给模型提供文字以及图像等Prompt,模型给予的图像结合文字的回答。
👇下面是一个分析所提供照片的细节,并让模型分析变色龙的融入的难度的同时生成一张变色龙的照片的案例。

👇下面是一个让模型提供一个用所给图片制作食物的完整而详细的食谱的案例。

👇下面是一个让模型科普所给图片中的小狗的种类相关的知识并生成一张同品种的小狗的案例。

👇下面是一个让模型生成一张指定种类的熊并对其进行介绍的案例。

项目原理
Chameleon模型采用了统一的基于token的表示方法,将图像量化为离散的tokens,类似于文本中的单词。
这种方法允许使用相同的Transformer架构处理图像和文本tokens序列,而无需分离的图像或文本编码器。
Chameleon的融合方法将所有模态从一开始就投射到一个共享的表示空间中,实现了跨模态的无缝推理和生成。

团队还展示了如何将用于文本生成的监督微调方法适应混合模式设置,从而实现大规模的强对齐。
在微调期间,每个数据集实例都包含一个成对的提示及其对应的答案。
为了提高效率,团队将尽可能多的提示和答案打包到每个序列中,插入一个不同的标记来划分提示的结束和答案的开始。
下面是微调时的任务类别以及提示示例。

因此,Chameleon既可以推理任意混合模式文档,也可以生成任意混合模式文档。
同时也可以处理各种各样的单模态或多模态复杂任务统统不在话下。👏
下面分别展示了Chameleon处理文本生成、编码、图像生成、视觉问答、图像文字混合生成等各种任务。

Chameleon模型在多个任务上进行了广泛的评估,结果表明,Chameleon不仅在图像描述任务上实现了最先进的性能,还在仅文本任务上超越了Llama-2。

此外,Chameleon在长篇混合模式生成评估中,匹配或超越了包括Gemini Pro和GPT-4V在内的更大模型的性能。
Chameleon的出现无疑代表了实现灵活推理和生成多模态内容的统一基础模型的一个重要进步。
小编期待Chameleon未来能够在更多领域发挥重要作用!
🔗 项目链接 :
https://github.com/facebookresearch/chameleon
关注「 向量光年 」公众号
加速全行业向AI的改变
关注「 开源AI项目落地 」公众号
与AI时代更靠近一点
关注「 AGI光年 」公众号
获取每日最新咨询











