点击上方「Linux开源社区」,选择「设为星标」
优质文章,及时送达
转自:一口Linux
1. 背景
最近在折腾网络编程,发现 IO 模型这块比较模糊,翻了不少资料,这里总结分享下。 关键字:网络编程;IO模型
2. 前置知识一:内核态,用户态
想要弄懂 IO 模型,有一批前置知识需要掌握,首先是内核态和用户态的概念。操作系统为了保护自己,设计了用户态、内核态两个状态。应用程序一般工作在用户态,当调用一些底层操作的时候(比如 IO 操作),就需要切换到内核态才可以进行。用户态和内核态的切换需要消耗一些资源,零拷贝技术就是通过减少用户态和内核态的转换来提高性能的。
3. 前置知识二:应用程序从网络中接收数据的大致流程
服务器从网络接收的大致流程如下:
数据通过计算机网络来到了网卡
把网卡的数据读取到 socket 缓冲区
把 socket 缓冲区读取到用户缓冲区,之后应用程序就可以使用了
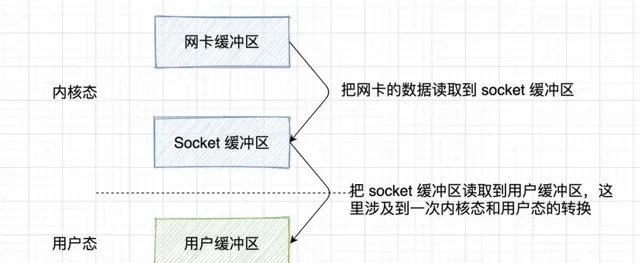
核心就是两次读取操作,五大 IO 模型的不同之处也就在于这两个读取操作怎么交互。
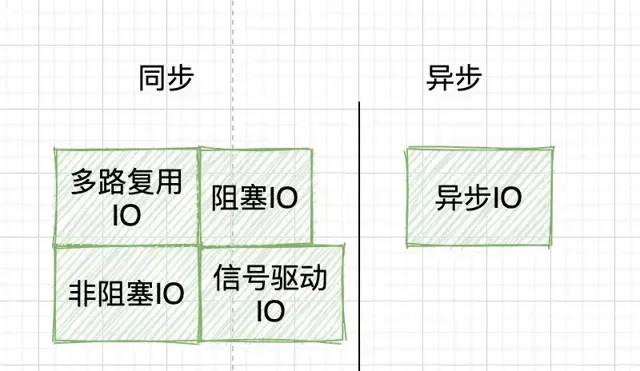
4. 前置知识三:理解同步/异步、阻塞/非阻塞
同步/异步:这个是应用层面的概念,指的是调用一个函数,我们是等这个函数执行完再继续执行下一步,还是调完函数就继续执行下一步,另起一个线程去执行所调用的函数。关注的是 线程间的协作 。阻塞/非阻塞,这个是硬件层面的概念,阻塞是指 cpu 「被」休息,处理其他进程去了,比如IO操作,而非阻塞则是 cpu 仍然会执行,不会切换到其他进程。关注的是CPU会不会「被」休息,表现在应用层面就 是线程会不会「被」挂起 。至于同步和阻塞有什么区别,异步和非阻塞有什么区别,其实这是不同层面的东西,不好相互比较的。在学习IO模型的过程中,千万别钻这个牛角尖。
5. 前置知识四:理解同步阻塞、同步非阻塞、异步阻塞、异步非阻塞
有很多 IO 模型的博客,会把同步/异步、阻塞/非阻塞两两组合,把IO模型分成四类。
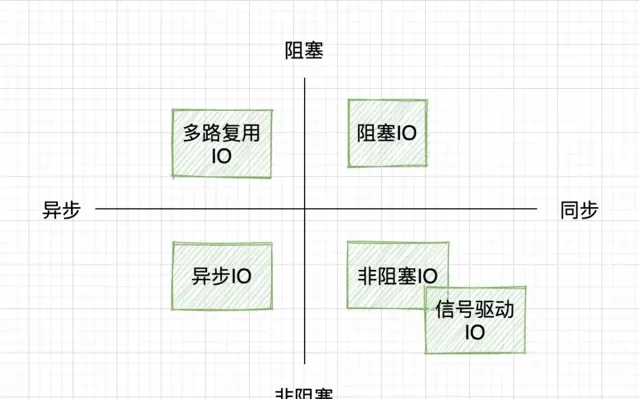
初看其实很纳闷的,都异步了,还咋阻塞啊?
其实大可不必纠结这个,同步/异步、阻塞/非阻塞本身就是不同层面的东西,强行组合起来就是不好理解,甚至是错误的。
建议是抛开这个,直接去理解五大 IO 模型,千万别钻牛角尖。其实,真要分,也只能拆成两个维度分,而不是四个维度。首先是按阻塞/非阻塞分:
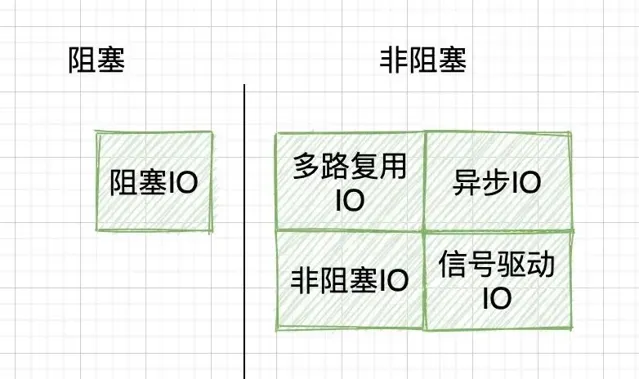
然后是按同步/异步分:
6. 五大 IO 模型之:阻塞 IO
好了,如果掌握了前面提到的的这些前置知识,理解IO模型就稍微轻松点了,现在开始。
之前提了,应用程序从网络中接收数据的大致流程就是两步:
数据准备:等待网络数据,把网卡的数据读取到 socket 缓冲区
数据复制:把 socket 缓冲区的数据读取到用户态 Buffer,供应用程序使用
IO模型的不同之处也就在于这两个操作怎么交互,我们先看看阻塞IO模型
当应用程序发起 read 调用时,调用线程会阻塞住直到第一步读取操作的完成。等第一步读取操作完成后,会将数据读取到用户态 Buffer 中,这个过程中调用线程仍然是阻塞的,直到数据复制完成,整个流程用图来表示就张这样:
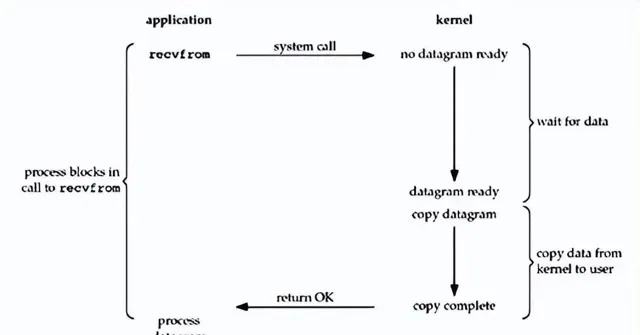
这种 IO 模型的好处就是好理解,API 简单好上手,适用于连接数不多的网络应用。
7. 五大 IO 模型之:非阻塞 IO
当应用程序发起 read 调用时,如果没有数据可读,调用线程不会阻塞。但应用程序为了读到数据,就会一直循环调用,直到有数据可读。微信搜索公众号:架构师指南,回复:架构师 领取资料 。
等第一步读取操作完成后,第二步就和阻塞IO一样了。会将数据读取到用户态 Buffer 中,这个过程中调用线程仍然是阻塞的,直到数据复制完成,整个流程用图来表示就张这样:
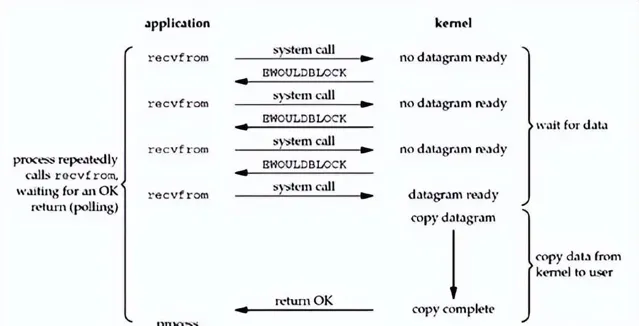
这种 IO 模型的并没有特别好处,而且会一直循环调用底层的接口,性能堪忧,很少使用。
8. 五大 IO 模型之:信号驱动 IO
当应用程序发起 read 调用,注册一个handler,等待有数据后的回调。应用程序一旦被回调,就说明数据已经可以读取了,就会进行第二步操作,把数据读取到用户态 Buffer 中。同样,第二步仍然是阻塞的。
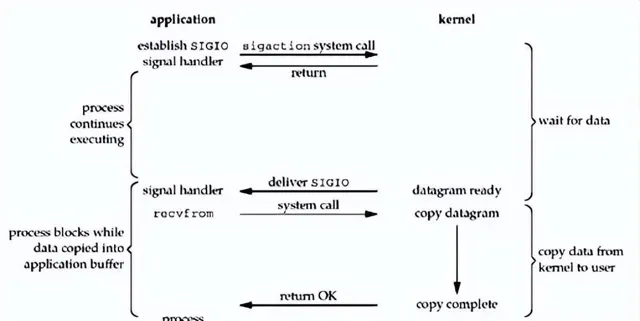
这种 IO 模型的好处就是相比于非阻塞IO,使用通知&回调机制减少了循环的开销,但是对于连接数多的场景,可能会因为信号队列溢出导致没法通知,用的不多。
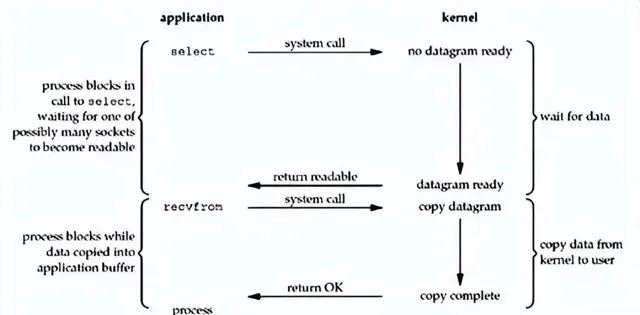
9. 五大 IO 模型之:多路复用 IO
当应用程序发起 read 调用时,如果没有数据可读,调用线程不会阻塞,系统会把 socket 注册到一个「多路复用器」上,等到有数据了会把可读的socket加入队列,供应用层使用。
大概的代码如下:
java复制代码while (true) {
if (selector.select(READ_KEY) > 0) { // selector 就是多路复用器,READ_KEY 大于 1 说明有可读的socket
Set<SelectionKey> set = clientSelector.selectedKeys();
Iterator<SelectionKey> keyIterator = set.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isReadable()) {
// 读取数据
}
}
}
}
这种 IO 模型的好处是能够应对大量的连接,尤其适用于大量的短连接。现在大多数网络应用,底层采用的都是多路复用IO。
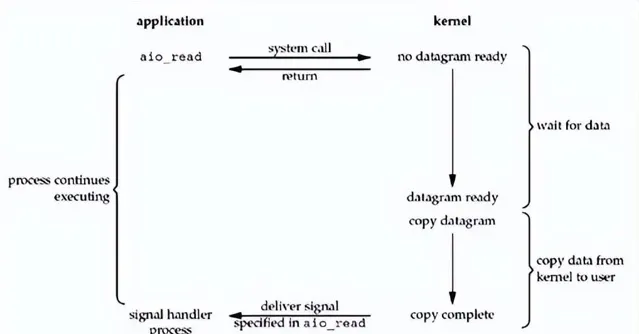
10. 五大 IO 模型之:异步 IO
异步IO 则和上面四种IO模型都不通,他是完完全全的异步,两步操作都不会阻塞。应用程序发起 read 调用后,等收到回调通知,就可以去使用用户态 Buffer 的数据了,如下图所示。
11. 打个比方
打个个人认为很贴切的比方,帮助理解。

大家都去医院取过药吧,五种IO模型就像是不同的取药方式。
阻塞IO: 排队等药,排到我了但是药还没准备好,那我也继续等着,别人也不能取。这种我没好,别人也落不着好的方式,就是阻塞IO的体现。
非阻塞IO: 排队等药,排到我了但是药还没准备好,那我重新排吧。重新排队就是轮询,因为重新排了也没有阻塞别人取消,就是非阻塞IO的体现。
信号驱动IO: 不用排队等药,药准备好了就直接短信通知你去取。短信通知就相当于信号驱动了,因为不用排队,节省了不少时间。
多路复用IO: 这个就是日常中常见的那种取药方式了,付了钱后要去药房的机器上扫码,然后盯着显示器,上面显示了你的名字,再去取药。在机器上扫码就相当于注册,显示了你的名字就相当于有需要处理的IO事件了。现实中显示了我的名字,我还是要去排队,这也是对应上的,因为一个 selector 返回的是多个需要处理的IO时间,一个个处理就相当于一个个排队取药。
异步IO: 这个就很赛博朋克了,异步IO就像是不用排队,不用取药,药好了直接寄你家,完全异步。
12. 可能会产生的疑问:
12.1 Java 的 nio 是对多路复用IO模型的实现,为什么叫非阻塞?
首先 Java 的 nio 包可以用来实现多路复用IO模型,也可以用来实现非阻塞IO模型,只不过非阻塞IO模型性能差没人用而已。其次,nio 中的那个「n」是 new 的意思。当时 JDK 的开发者为了和老的io包做区分,才用nio 来表示的,并不是 nonblocking 的「n」,所以叫「新IO包」更准确,也不容易弄混。
12.2 select、poll、epoll有什么关系
select、poll、epoll 都是用来实现多路复用的,原理也都是通过遍历找到可读写的socket,区别在于
select 有限制,最多1024个,poll、epoll没有这个限制。
poll 对数据结构有优化,没有 1024 个的限制,但还是要遍历所有socket,目前很少用。
epoll 对遍历有优化,不会遍历所有socket,只会遍历那些可读的socket,所以效率有所提升。
12.3 信号驱动 IO 和多路复用 IO 很难分辨
信号驱动 IO 的底层机制是事件通知,多路复用 IO 的底层机制是遍历+回调,只不过在应用层面包装成了事件而已。
13. 总结
从网卡中读取数据有两步:第一步是网卡到 socket 缓存区,第二步是从 socket 缓冲区到内核态。
IO 模型有五种:阻塞IO、非阻塞IO、信号驱动IO、多路复用IO、异步IO。
阻塞IO:两步都阻塞
非阻塞IO:第一步不阻塞,但应用层不知道什么时候数据可读,所以需要不断轮询
信号驱动IO:第一步不阻塞,但应用层不感知这一步的阻塞,机制是事件通知机制,数据准备好后直接通知应用层读取
多路不用IO:第一步不阻塞,但应用层不感知这一步的阻塞,机制是遍历所有 Socket,有准备好的再通知应用层读取
异步IO:纯异步,数据准备好后,应用层直接使用。
-End-
读到这里说明你喜欢本公众号的文章,欢迎 置顶(标星)本公众号 Linux技术迷,这样就可以第一时间获取推送了~
在本公众号,后台回复:Linux,领取2T学习资料 !
推荐阅读
1.
2.
3.
4.