来源:量子位 | 公众号 QbitAI
家人们,要爬虫——现在用 一个电子表格 就行了。
一行代码也别写,第三方软件也甭安。
只需在表格里 点几下 就ok。
不信,你瞧:
就这么两下,网页上的商品信息都有了。
网友看完都惊呆了,码个不停。
一看到这是来自谷歌的产品 (Google Sheet,谷歌的「Excel」) ,大家就立马cue起了 微软 ,问它慌不慌。
还有人称这是在「跨界打击」它。

△ 扫盲:「巨硬」就是微软,网友给的调侃
好不热闹。
来看具体怎么实现。
详细步骤
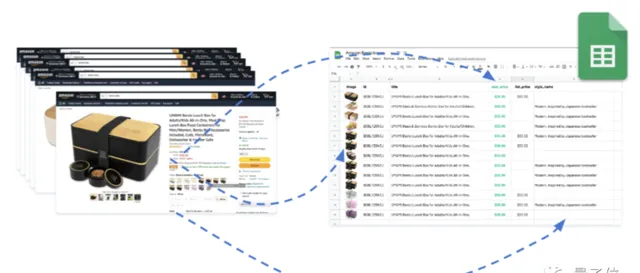
以爬亚马逊某个手机产品的商品页为例。
我们先打开谷歌Sheet (网友版即可) ,新建一个文档。
然后copy一下要爬的网址,粘进去。
剩下的都在Sheet里完成。
我们先列一下要爬的元素,这里依次为:
商品图片-识别码 (asin,亚马逊给每个商品生成的唯一标识) -商品名-价格-评分-图片网址。

然后就可以正式开始爬了。
要诀就是一个叫做 ImportFromWe b 的函数。
它也是个插件,没有的需要先安装一下 (安装地址放文末了) ,然后通过Google Sheet程序的「扩展程序」菜单导入就行。

我们只需把ImportFromWeb函数放进asin那一列,然后第一个参数选中刚刚粘过来的网址,第二个参数把要爬的元素单元格拖一遍 (除了「图片」) 。
稍等个1~2s ,价格、商品名等信息就都出来了!
还差图片。
简单~基操~
用IMAGE函数把G3格子里得到的图片网址值给过去就行。
至此,第一个商品页里的东西就爬到了。
唯一麻烦的是,如果还需要爬更多商品的信息,需要把商品网址挨个粘一遍。
然后就没啥了,除了给单元格地址的行标列标加一下 绝对引用符「$」 。
这里可以不学视频,直接一个 f4 就行。
拖一下,全部搞定!
怎么样?是不是非常方便。
看完整个操作,你也发现了,其实就是谷歌写了个脚本给咱封装好了直接用。
而据官方介绍,这个ImportFr omWeb功能还能 自动更新 爬取到的信息。
而且只要是用JS写的网站都可以爬 (基本等于绝大数网站了) ,每个函数还可支持50个url,以及数千个数据点。
end
我之前还用过一个低代码数据收集平台——亮数据Bright Data,也是比较方便就能爬取数据。
它提供数据采集浏览器、网络解锁器、数据采集托管IDE三种方式,能通过简单的几十行Python代码实现复杂网络数据的采集,对于反爬、验证码、动态网页等进行自动化处理,完全不需要你操心。

官网地址(点击原文链接也可查看):
https://get.brightdata.com/weijun
有数据抓取需求的可以试试,非常简单,能节省大量时间和精力!!!
亮数据也提供了现成的数据集,包括电商、社媒、金融、新闻、视频等等
这些现成的数据集,对于有数据分析需求的人来说非常有节省时间,可以做市场分析、训练模型等等。