项目简介
北京大学研究者们推出的Video-LLaVA模型,通过前沿技术,使大型语言模型能同时处理图像与视频内容,推动多模态学习发展。此模型通过将视觉特征预先绑定至统一特征空间,提升了视觉信息的理解与处理效率,特别是在视频问答等应用中表现突出。相较传统模型,Video-LLaVA通过结合图像和视频训练,有效提高了性能和效率。
扫码加入交流群
获得更多技术支持和交流
(请注明自己的职业)

特点
Video-LLaVA在数据集中缺少图像-视频对的情况下,展示出了图像和视频之间非凡的交互能力。
💡 简单的基线,通过在投影之前的对齐来学习统一的视觉表示通过将统一的视觉表示与语言特征空间绑定,我们使一个大型语言模型(LLM)能够同时对图像和视频执行视觉推理能力。
🔥 高性能,视频和图像的互补学习广泛的实验表明了模态间的互补性,与专为图像或视频设计的模型相比,展现出显著的优越性。

Demo
Gradio Web界面
强烈推荐通过以下命令尝试网页演示,该演示集成了Video-LLaVA目前支持的所有功能。
在Huggingface Spaces 也提供在线演示。
python -m videollava.serve.gradio_web_server
CLI 推理
CUDA_VISIBLE_DEVICES=0 python -m videollava.serve.cli --model-path "LanguageBind/Video-LLaVA-7B" --file "path/to/your/video.mp4" --load-4bit
CUDA_VISIBLE_DEVICES=0 python -m videollava.serve.cli --model-path "LanguageBind/Video-LLaVA-7B" --file "path/to/your/image.jpg" --load-4bit
主要结果
·
图像理解
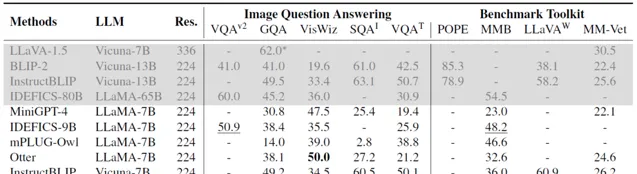
· 视频理解

安装和要求
· Python >= 3.10
· Pytorch == 2.0.1
· CUDA Version >= 11.7
· 安装所需的包:
git clone https://github.com/PKU-YuanGroup/Video-LLaVAcd Video-LLaVAconda create -n videollava python=3.10 -yconda activate videollavapip install --upgrade pip # enable PEP 660 supportpip install -e .pip install -e ".[train]"pip install flash-attn --no-build-isolationpip install decord opencv-python git+https://github.com/facebookresearch/pytorchvideo.git@28fe037d212663c6a24f373b94cc5d478c8c1a1d
API
如果想在本地加载模型,可以使用如下代码
图像推理
import torchfrom videollava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKENfrom videollava.conversation import conv_templates, Separator stylefrom videollava.model.builder import load_pretrained_modelfrom videollava.utils import disable_torch_initfrom videollava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteriadef main():disable_torch_init() image = 'videollava/serve/examples/extreme_ironing.jpg' inp = 'What is unusual about this image?' model_path = 'LanguageBind/Video-LLaVA-7B' cache_dir = 'cache_dir' device = 'cuda' load_4bit, load_8bit = True, False model_name = get_model_name_from_path(model_path) tokenizer, model, processor, _ = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device, cache_dir=cache_dir) image_processor = processor['image'] conv_mode = "llava_v1" conv = conv_templates[conv_mode].copy() roles = conv.roles image_tensor = image_processor.preprocess(image, return_tensors='pt')['pixel_values']if type(image_tensor) is list: tensor = [image.to(model.device, dtype=torch.float16) for image in image_tensor]else: tensor = image_tensor.to(model.device, dtype=torch.float16) print(f"{roles[1]}: {inp}") inp = DEFAULT_IMAGE_TOKEN + '\n' + inp conv.append_message(conv.roles[0], inp) conv.append_message(conv.roles[1], None) prompt = conv.get_prompt() input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda() stop_str = conv.sep if conv.sep_ style != Separator style.TWO else conv.sep2 keywords = [stop_str] stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids) with torch.inference_mode(): output_ids = model.generate( input_ids, images=tensor, do_sample=True, temperature=0.2, max_new_tokens=1024, use_cache=True, stopping_criteria=[stopping_criteria]) outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip() print(outputs)if __name__ == '__main__': main()
视频推理
import torchfrom videollava.constants import IMAGE_TOKEN_INDEX, DEFAULT_IMAGE_TOKENfrom videollava.conversation import conv_templates, Separator stylefrom videollava.model.builder import load_pretrained_modelfrom videollava.utils import disable_torch_initfrom videollava.mm_utils import tokenizer_image_token, get_model_name_from_path, KeywordsStoppingCriteriadef main():disable_torch_init() video = 'videollava/serve/examples/sample_demo_1.mp4' inp = 'Why is this video funny?' model_path = 'LanguageBind/Video-LLaVA-7B' cache_dir = 'cache_dir' device = 'cuda' load_4bit, load_8bit = True, False model_name = get_model_name_from_path(model_path) tokenizer, model, processor, _ = load_pretrained_model(model_path, None, model_name, load_8bit, load_4bit, device=device, cache_dir=cache_dir) video_processor = processor['video'] conv_mode = "llava_v1" conv = conv_templates[conv_mode].copy() roles = conv.roles video_tensor = video_processor(video, return_tensors='pt')['pixel_values']if type(video_tensor) is list: tensor = [video.to(model.device, dtype=torch.float16) for video in video_tensor]else: tensor = video_tensor.to(model.device, dtype=torch.float16) print(f"{roles[1]}: {inp}") inp = ' '.join([DEFAULT_IMAGE_TOKEN] * model.get_video_tower().config.num_frames) + '\n' + inp conv.append_message(conv.roles[0], inp) conv.append_message(conv.roles[1], None) prompt = conv.get_prompt() input_ids = tokenizer_image_token(prompt, tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda() stop_str = conv.sep if conv.sep_ style != Separator style.TWO else conv.sep2 keywords = [stop_str] stopping_criteria = KeywordsStoppingCriteria(keywords, tokenizer, input_ids) with torch.inference_mode(): output_ids = model.generate( input_ids, images=tensor, do_sample=True, temperature=0.1, max_new_tokens=1024, use_cache=True, stopping_criteria=[stopping_criteria]) outputs = tokenizer.decode(output_ids[0, input_ids.shape[1]:]).strip() print(outputs)if __name__ == '__main__': main()
项目链接
https://github.com/PKU-YuanGroup/Video-LLaVA
关注「 开源AI项目落地 」公众号











