作者 | Aidan McLaughlin
译者 | 弯月 责编 | 苏宓
出品 | CSDN(ID:CSDNnews)
假设我们能够自动化 AI 研究,结果会怎样?假设我们不必等待 2030 年的超级集群,就能治愈癌症,结果会怎样?假设超级人工智能(ASI) 就在我们身边,情况又会如何呢?
赋予基础模型「搜索」的能力(即更长时间的思考能力)可能会颠覆规模定律,改变 AI 的发展轨迹。
Leela 的终结
2019 年,一组研究人员构建了一台具有突破性的国际象棋计算机,名叫Leela Chess Zero(莱拉国际象棋零),名字中包含「零」是因为她只知道规则。这台引擎通过与自己对弈数十亿次,完成了国际象棋的学习。她的走法颠覆了几个世纪以来人类建立的国际象棋规则。她富有创造性,并愿意做出长期牺牲。Leela 玩弄她的对手,并展现出一些奇怪的人类倾向。她甚至赢得了世界冠军。然而,后来她被Stockfish击败了。
我爱 Leela。我投入了数年的时间来了解和研究这个引擎,并做了很多基准测试。小时候,我总幻想遇到超级智能的外星人,然后他们教我如何下棋。观看了Leela的棋局,我发现我找到了答案。
当然,Leela 的魔力在于深度学习。她通过自学,获得了更深入的象棋表征,远胜人类的硬编码。多年后,我仍然认为 Leela 是一个惨痛的教训。Leela 摒弃了人类的傲慢,并自行解决问题。
早在规模定律流行之前,Leela 就证明了这一点。2018 年,我和团队中的其他人注意到,大型网络始终优于小网络。我们甚至观察到了一些显著的涌现特性,大型网络似乎能够在没有明确指示或搜索的情况下「预见」几步。
2020 年,Leela 团队竞相训练更大的网络。他们通过企业捐赠和朋友的 GTX 1070获得了计算资源。我们跟踪了许多自我对弈指标,就像今天许多人跟踪 Wandb 损失曲线一样。Leela 最大的模型赶在世界冠军赛之前出炉了。然而,她遭遇了惨败。
Stockfish的时代
Stockfish 是 2010 年代国际象棋程序的主宰,它是旧世界 AI 的遗物。2019 年,Stockfish 的代码是由人类精心编写的,他们将自己的对弈知识提炼成了巧妙的数学公式。在2019年的比赛中,Leela的深度学习和白板启发法惊人地推翻了 Stockfish。那么,为什么Leela使用了更大的网络,却被Stockfish重新夺回了王冠呢?
Stockfish 拥有更好的搜索。
小时候,爸爸教我下棋。四岁那年,我问他,为什么他的朋友(一位脾气古怪的克罗地亚特级大师)这么厉害?我爸回答说:「他能看到很多步棋。」
「看到很多步棋」是我最喜欢的「搜索」的定义。这正是国际象棋计算机的任务:评估棋盘,然后预见后面的很多步。在国际象棋之外,人类也经常这样做。在破解一个棘手的数学问题时,你也会使用某种形式的搜索。
Leela 颠覆了国际象棋,因为她抛弃了人类的国际象棋知识,自学成才。在当时,虽然Stockfish具备处理数十亿个棋位的能力,但这根本没用,因为它对每个棋位的理解受限于它的人类创造者。
为了改进这一点,Stockfish 团队借鉴了 Leela 的深度学习技术,训练了一个比顶级 Leela 模型小数百倍的模型。
在这个小模型完成训练后,他们将其投入到了搜索管道中,于是 Stockfish 在一夜之间击败了 Leela。

Stockfish 完全否定了规模法则。他们反其道而行之,制作了一个更小的模型。但是,由于他们的搜索算法更高效,更好地利用了硬件,并且看得更远,所以他们赢了。
我们由此明白了一个惨痛的教训: 在深度学习的世界中,你不应该低估 AI 搜索的力量。
Leela 的搜索能力不佳,从而失去了世界冠军。我们本来有机会将搜索功能添加到大型语言模型,但我担心没有人注意到这一点。
搜索时代
基础模型,如 GPT-4,缺乏搜索能力。你不能指望 GPT-4 思考一个月的问题并给出更好的答案。如今,要求模型「逐步思考」可以改善性能,但回报大幅降低。但是,如果我们赋予现有模型搜索功能,结果会怎样?
注意:在后文中,我所说的基础模型搜索指的是模型利用推理计算(搜索),而不是训练计算(模型扩展),以更好地解决问题的能力。
我所交谈过的每一位AI研究人员、经济学家和CEO都极大地低估了赋予基础模型搜索能力的重要性。
原因大致如下:
我们不需要规模来解决搜索问题。
我们可以利用搜索有针对性地分配计算资源。
我们能够利用搜索自动化AI研究。
无需规模
人们普遍认为,我们需要更大的模型才能实现大型语言模型搜索。Sholto Douglas等人声称,我们需要更多的大型语言模型来处理长期思考。而Leopold Aschenbrenner等人则认为,预训练可能已经包含了搜索所需的必要因素,我们只需要「稍微扩展」和一些额外的标记就可以实现。但是,事实证明,规模并非搜索的先决条件。
最近,DeepMind研究了没有搜索的棋类算法,并指出这种算法自然地产生了搜索行为(预测走步)。研究人员指出,由于棋类已经有了搜索算法,为什么我们还要等待低效的大模型预测后面的走法呢?
此外,文章【Scaling Scaling Laws with Board Games】(棋牌游戏的扩展法则的扩展)表明,「训练时间每额外增加10倍,就可以消除大约15倍的测试时间计算」,这个结果甚至适用于单个神经元模型。请记住,Stockfish用于打败Leela的模型在规模上小三个数量级。
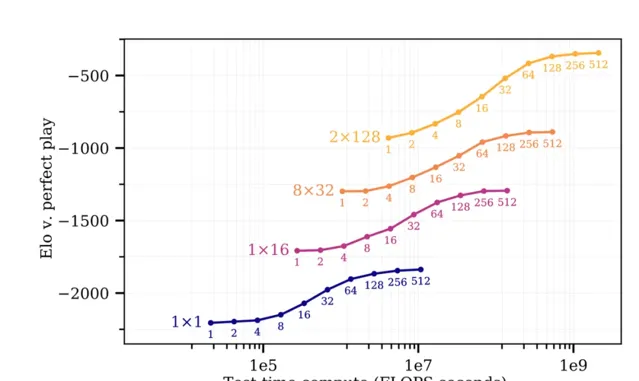
现如今,我们的模型非常庞大(也许是过于庞大了),足以支持搜索。
虽然很少有人完全理解搜索的重大意义,但许多人正在致力于此项研究。Demis Hassabis和Sam Altman公开表示,他们希望模型能够长时间思考。网上有大量关于大型语言模型的文献资料。在GPT-4发布后的一年里,我们看到了许许多多「思维图谱」、「思维链」、「LLM MCTS」等论文。我们会解决搜索问题。甚至有可能许多已发表的技术已经投入了使用,只是我们还没有跟上节奏。
有针对性的计算
训练时间和推理时间计算之间的权衡大致相同。初听之下,这似乎令人失望。Aidan曾声称大型语言模型搜索将吞噬整个世界。如果推理成本和训练一样昂贵,这又怎么可能实现呢?
简单来说:
搜索可以有针对性地分配计算资源:你只需为自己的领域买单。
想象一下,我是辉瑞,我想利用人工智能研究新药。在一个具有AI搜索能力的世界中,我有两个选择:
等到2030年,直至OpenAI发布一个比现在大四个数量级的模型。
使用比现在大四个数量级的推理计算资源。
辉瑞当然会选择第二个!
有了搜索功能,辉瑞就不必等待Sam Altman筹集7万亿美元,微软股票升值,或者国会批准人工智能支出法案。辉瑞可以自掏腰包,投资推理计算,并立即获得GPT-8的能力。
假设,辉瑞每年在GPT-4上的支出为10万美元。
如果他们想利用搜索功能,马上获得2030年超级智能(ASI)的能力,那么他们需要将人工智能预算增加四个数量级,即每年10亿美元。
虽然对于一家公司来说,这是一笔巨款,但辉瑞的研发预算高达120亿美元!
再次强调,这是为了获得超级智能而投入的10亿美元。
对于辉瑞来说,这项投资非常值得,因为他们不必等待OpenAI训练下一个重要模型。对于OpenAI来说,这也是一个好消息,因为他们的推理可以赚更多钱。双赢局面。
尚未成熟的超级智能
下面,我们来简单地介绍一下搜索宇宙与规模宇宙的区别。根据Leopold Aschenbrenner的详细说明,2030年超级智能的构建方式如下:
各大公司自掏腰包购买大型集群。
这些大型集群能够推动收入增长。
各大公司获得巨额贷款,建设更大的集群。
更大的集群再次推动收入增长。
政府介入并建设最大的集群。
然后,模型达到逃逸速度,可以自行进行AI研究。
在没有搜索的世界里,Leopold的模型似乎是合理的。
以下是我的愿景:
我们发现搜索功能可以应用于现有模型。
大型实验室和政府意识到,他们可以即刻将搜索应用于进一步的AI研究。
推理计算受到限制:政府或大型实验室将其限制在安全或AI研究领域。
在搜索的驱动下,AI不断进步,并发现了更高效的搜索算法和模型架构。
「数据壁垒」问题消失,因为搜索不需要更多的训练数据。
智能爆炸从明年开始,而不是2030年。
尽管一些人承认,搜索确实可以在一些狭窄领域带来几个数量级的增益,但他们似乎忘记了我们很可能会将搜索首先应用于AI研究。
许多人认为,当人工智能发展到足够强大,可以研究自身时,整个人类的科技力量都会腾飞。但正如辉瑞无需等待GPT-8,就可以利用搜索研究更好的药物一样,人工智能实验室无需等待更大的模型,也可以利用搜索研究人工智能。
当然,我们可能需要打破更多枷锁,取代自主和主动的人工智能研究者。但我认为,以GPT-8的智能水平,一个简单的聊天机器人就足以加速提升AI的能力。
利用搜索自动化AI研究有巨大的上升空间。
虽然我怀疑早期的搜索增强模型可能没有人类代理,但它们可能是超人类的「扶手椅理论家」,推动了算法进步。
假设GPT-4花费一万亿个令牌(1500万美元),发现了一种减少训练成本3%或增加搜索效率10%的算法,那么这将收获巨大的回报。
假设辉瑞公司利用搜索发现了一种更好的药物,这虽然也是一种进步,但新药物对辉瑞的进一步研究并没有帮助。而对于人工智能研究来说,更好的算法将帮助你构建更好的人工智能。
自我改进的人工智能并非新概念,这种「科幻」距离我们的生活之近超出了许多人的想象。
总结
如果你认同我的预测,则必须相信:
基础模型搜索算法已存在,这些算法所能带来的性能增益并不低于强化学习系统。
相较于模型扩展,搜索可以更高效地将现有资本转化为智能。
也许对于许多AI领域的人来说,这两个说法都很离谱。但与2020年代深入研究的规模定律不同,我们缺乏关于搜索性能和经济学的充分证据。以上是我根据自己的游戏强化学习研究得出的推断。
2019年,人工智能研究人员希望计算机在棋牌游戏中能有更好的表现。通过几个月的努力,他们意识到了:
一个惨痛的教训
规模定律
搜索的力量
以上第一点和第二点得到广泛的认可,并推动了2020年代AI空前的发展。但我们仍需努力。
原文:https://yellow-apartment-148.notion.site/AI-Search-The-Bitter-er-Lesson-44c11acd27294f4495c3de778cd09c8d
本文为 CSDN 翻译。
推荐阅读:












