
👉 欢迎 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利
全栈前后端分离博客项目 1.0 版本完结啦,2.0 正在更新中 ... , 演示链接 : http://116.62.199.48/ ,全程手摸手,后端 + 前端全栈开发,从 0 到 1 讲解每个功能点开发步骤,1v1 答疑,直到项目上线。 目前已更新了239小节,累计38w+字,讲解图:1645张,还在持续爆肝中.. 后续还会上新更多项目,目标是将Java领域典型的项目都整一波,如秒杀系统, 在线商城, IM即时通讯,Spring Cloud Alibaba 等等,
Part1 引言
Part2 keySet如何遍历了两次
1 iterator()
2 HashMap.KeySet#iterator()
3 HashMap.KeyIterator
4 HashMap.HashIterator
Part3 总结
Part1 引言
HashMap相信所有学Java的都一定不会感到陌生,作为一个非常重用且非常实用的Java提供的容器,它在我们的代码里面随处可见。因此遍历操作也是我们经常会使用到的。HashMap的遍历方式现如今有非常多种:
使用迭代器(Iterator)。
使用
keySet()获取键的集合,然后通过增强的 for 循环遍历键。使用
entrySet()获取键值对的集合,然后通过增强的 for 循环遍历键值对。使用 Java 8+ 的 Lambda 表达式和流。
以上遍历方式的孰优孰劣,在【阿里巴巴开发手册】中写道:

这里推荐使用的是
entrySet
进行遍历,在Java8中推荐使用
Map.forEach()
。给出的理由是
遍历次数
上的不同。
keySet遍历,需要经过 两次 遍历。
entrySet遍历,只需要 一次 遍历。
其中keySet遍历了两次,一次是转为Iterator对象,另一次是从hashMap中取出key所对应的value。
其中后面一段话很好理解,但是前面这句话却有点绕,为什么转换成了Iterator遍历了一次?
我查阅了各个平台对HashMap的遍历,其中都没有或者原封不动的照搬上句话。(当然也可能是我没有查阅到靠谱的文章,欢迎指正)
Part2 keySet如何遍历了两次
我们首先写一段代码,使用keySet遍历Map。
public class Test {
public static void main(String[] args) {
Map<String, String> map = new HashMap<>();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
for (String key : map.keySet()) {
String value = map.get(key);
System.out.println(key + ":" + value);
}
}
}
运行结果显而易见的是
k1:v1
k2:v2
k3:v3
两次遍历,第一次遍历所描述的是转为Iterator对象我们好像没有从代码中看见,我们看到的后面所描述的遍历,也就是遍历
map,keySet()
所返回的
Set
集合中的key,然后去HashMap中拿取value的。
Iterator对象呢?如何遍历转换为Iterator对象的呢?

首先我们这种遍历方式大家都应该知道是叫:
增强for循环,for-each
这是一种Java的语法糖~。
我们可以通过反编译,或者直接通过Idea在 class文件中查看对应的 class文件
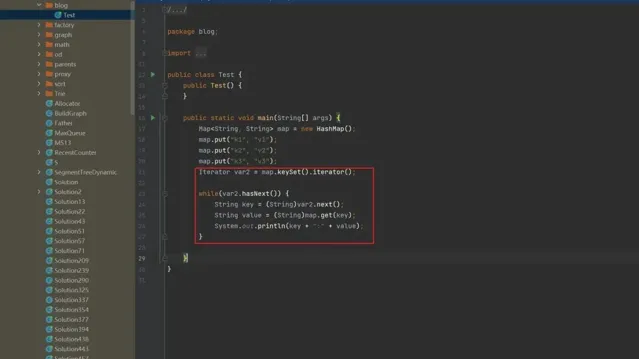
public class Test {
public Test() {
}
public static void main(String[] args) {
Map<String, String> map = new HashMap();
map.put("k1", "v1");
map.put("k2", "v2");
map.put("k3", "v3");
Iterator var2 = map.keySet().iterator();
while(var2.hasNext()) {
String key = (String)var2.next();
String value = (String)map.get(key);
System.out.println(key + ":" + value);
}
}
}
和我们编写的是存在差异的,其中我们可以看到其中通过
map.keySet().iterator()
获取到了我们所需要看见的
Iterator
对象。
那么它又是怎么转换成的呢?为什么需要遍历呢?我们查看
iterator()
方法
1 iterator()
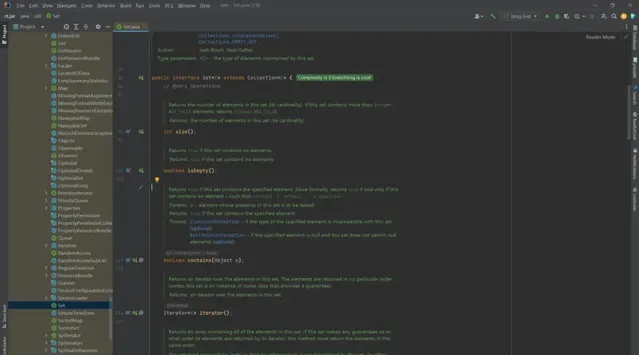
发现是Set定义的一个接口。返回此集合中元素的迭代器
2 HashMap.KeySet#iterator()
我们查看HashMap中keySet类对该方法的实现。
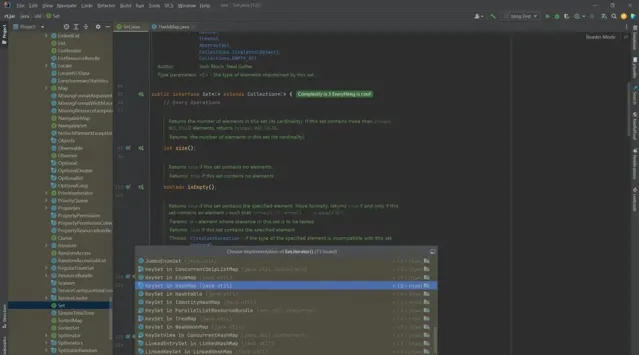
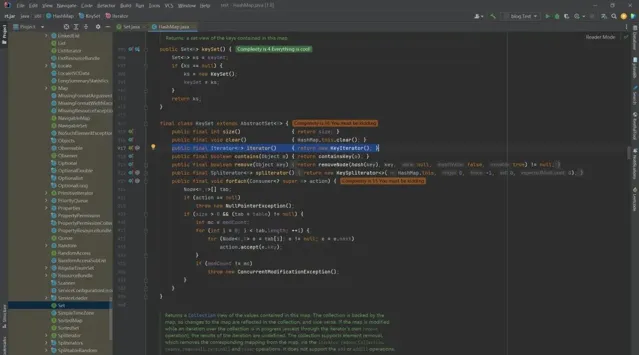
final class KeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { HashMap.this.clear(); }
public final Iterator<K> iterator() { return new KeyIterator(); }
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return new KeySpliterator<>(HashMap.this, 0, -1, 0, 0);
}
public final void forEach(Consumer<? super K> action) {
Node<K,V>[] tab;
if (action == null)
throw new NullPointerException();
if (size > 0 && (tab = table) != null) {
int mc = modCount;
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next)
action.accept(e.key);
}
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
}
其中的iterator()方法返回的是一个
KeyIterator
对象,那么究竟是在哪里进行了遍历呢?我们接着往下看去。
3 HashMap.KeyIterator
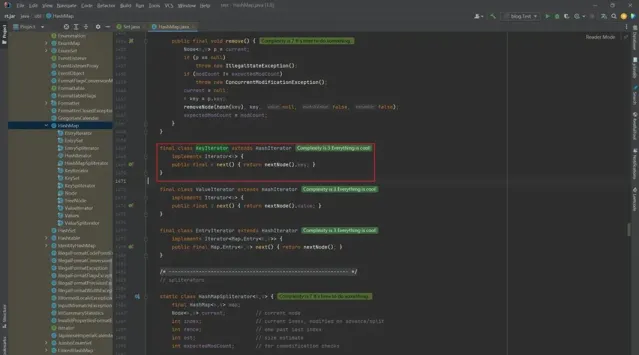
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
这个类也很简单:
继承了
HashIterator类。实现了
Iterator接口。一个
next()方法。
还是没有看见哪里进行了遍历,那么我们继续查看
HashIterator
类
4 HashMap.HashIterator
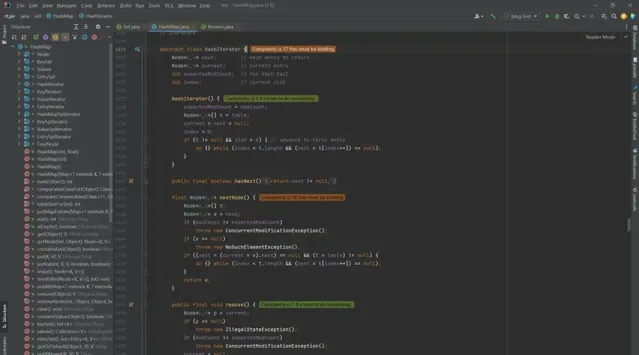
abstract class HashIterator {
Node<K,V> next; // next entry to return
Node<K,V> current; // current entry
int expectedModCount; // for fast-fail
int index; // current slot
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
public final boolean hasNext() {
return next != null;
}
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
}
我们可以发现这个构造器中存在了一个
do-while
循环操作,目的是找到一个第一个不为空的
entry
。
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
而
KeyIterator
是extend
HashIterator
对象的。这里涉及到了继承的相关概念,大家忘记的可以找相关的文章看看,或者我也可以写一篇~~dog。
例如两个类
public class Father {
public Father(){
System.out.println("father");
}
}
public class Son extends Father{
public static void main(String[] args) {
Son son = new Son();
}
}
创建Son对象的同时,会执行Father构造器。也就会打印出
father
这句话。
那么这个循环操作就是我们要找的循环操作了。
Part3 总结
使用keySet遍历,其实内部是使用了对应的
iterator()方法。iterator()方法是创建了一个KeyIterator对象。KeyIterator对象extendHashIterator对象。HashIterator对象的构造方法中,会遍历找到第一个不为空的entry。
keySet->iterator()->KeyIterator->HashIterator
👉 欢迎 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利
全栈前后端分离博客项目 1.0 版本完结啦,2.0 正在更新中 ... , 演示链接 : http://116.62.199.48/ ,全程手摸手,后端 + 前端全栈开发,从 0 到 1 讲解每个功能点开发步骤,1v1 答疑,直到项目上线。 目前已更新了239小节,累计38w+字,讲解图:1645张,还在持续爆肝中.. 后续还会上新更多项目,目标是将Java领域典型的项目都整一波,如秒杀系统, 在线商城, IM即时通讯,Spring Cloud Alibaba 等等,

1.
2.
3.
4.
最近面试BAT,整理一份面试资料【Java面试BATJ通关手册】,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点「在看」,关注公众号并回复 Java 领取,更多内容陆续奉上。
PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下「在看」,加个「星标」,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点「在看」支持小哈呀,谢谢啦











