背景
知乎Hadoop集群上每天运行着大量的Spark作业,包括调度平台提交的例行作业、Kyuubi提交的Spark SQL作业,每天Spark作业的Shuffle量达到3PB以上,单个Spark作业Shuffle量最大接近100TB,单个Stage 50TB。 同时Hadoop集群上每天有1PB左右的MR作业Shuffle,以及DataNode的磁盘IO。
Sp ark ESS Shuffle在大作业稳定性上更有优势,在Executor意外退出或者GC严重时,已经完成的Map端的Shuffle数据,可以继续被下游读取,不受影响,所以知乎使用的是ESS(External Shuffle Service)作为Spark的Shuffle服务。
但是ESS也有自己的局限性,ESS Shuffle过程中,每个Reducer Task需要去每个上游Mapper Task的输出文件中读取属于自己的Block,从而产生大量的网络连接以及随机IO,大量的随机IO会导致容易达到磁盘的IOPS瓶颈,作业性能和稳定性都会明显下降 [1][2]。在知乎,经常遇到IO负载高的节点导致个别Spark作业Shuffle Read耗时不稳定甚至超时导致的作业执行耗时不稳定、失败等问题。下图可以清楚的描述ESS Shuffle过程中的磁盘读取及网络连接情况:
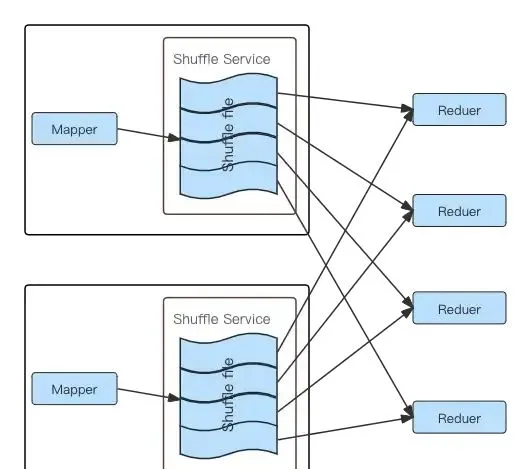
Spark ESS Shuffle 流程图
为了更好的表述ESS Shuffle存在的问题,借用LinkedIn论文中的一张Shuffle数据统计图,图中很清楚的描述了使用ESS Shuffle时,5000个样本作业不同Shuffle Stage的平均Shuffle Read Block大小分布,以及作业平均Shuffle Read Block大小与作业Task Shuffle Read耗时关联关系。从图中不难看出,存在大量的KB级别的Shuffle Read Block(每个Block至少会一次磁盘IO),而且Shuffle Read Block越小,整体Shuffle Read耗时更长。
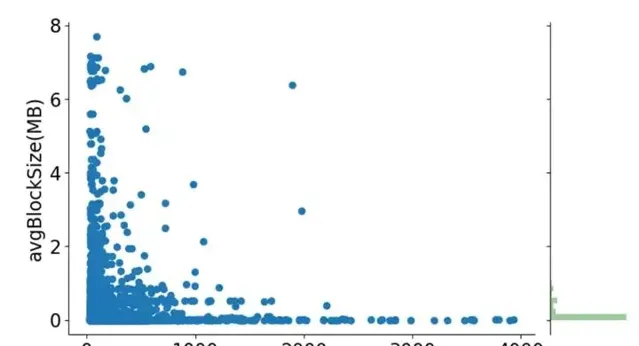
作业ShuffleBlock大小均值、Task Shuffle Read耗时均值的分布
ESS生产环境个别Task ShuffleRead 10M数据10min+
针对ESS 的问题,业界提出了Push Based Shuffle方案,核心思路是Mapper Task Shufle数据不写本地磁盘,而是写入一个远程Shuffle服务(RSS),同一个Reducer Task的数据写入到同一个远程节点,远程Shuffle节点对同一个Reducer Task的数据进行合并,当Reducer Task读取数据时只需从一个节点的连续的磁盘空间读取,下图清楚的描述了RSS在Shuffle过程中磁盘读取时与ESS的不同:
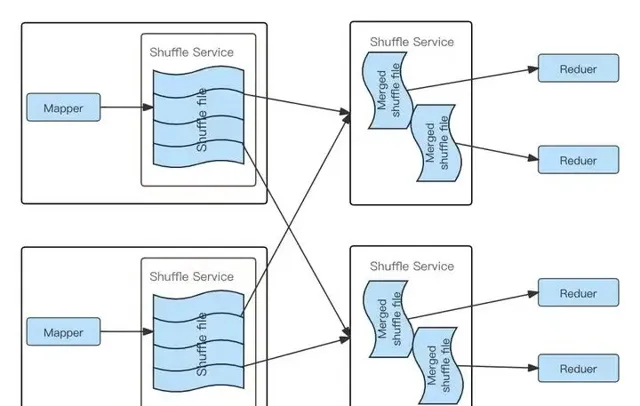
Spark RSS Shuffle流程图
Spark RSS 实现调研
RSS有不少开源实现,我们主要关注了两个国内大厂的开源实现,腾讯开源的Apache Uniffle以及阿里开源的Apache Celeborn。Uniffle在知乎之前的在离线混部项目中有使用,当时的Celeborn版本还不支持MR作业,而我们需要同时把符合条件的MR、Spark作业调度到混部Hadoop集群,该项目就选择了Uniffle,很好地支持了知乎的在离线混部项目,参考【知乎k8s在离线混部-离线篇】。
在本次大数据作业迁移RSS项目中,我们跟Celeborn社区进行了一次交流,Celeborn社区给介绍了下Celeborn的特性,发现Celeborn具有一些吸引我们的特性,比如平滑升级、磁盘容错、基于磁盘负载的调度等,同时Celeborn也已经支持了MR作业,于是我们重新对ESS、Uniffle、Celeborn做了一次对比测试。
我们在测试环境中使用TPC-DS 3000sf数据集进行了ESS、Celeborn、Uniffle对比测试,在我们的测试场景Celeborn、Uniffle查询性能相比ESS都有明显优势,Celeborn与Uniffle差距不大,同时Celeborn的内存消耗更低,下图是在测试环境ESS与Celeborn的耗时比值,数值是ESS耗时相对Celeborn耗时的倍数,大于1代表ESS更慢:
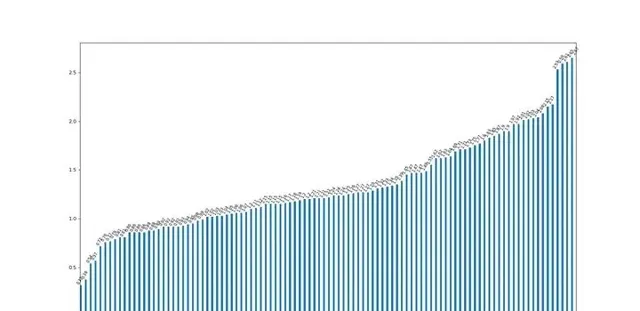
ESS与Celeborn查询耗时比值(大于1表示ESS耗时高于Celeborn)
线上环境相对测试环境磁盘负载要高很多,我们线上环境目前确实存在严重的随机Shuffle问题,理论上线上环境RSS相对ESS的优势会更大一些,所以选择RSS势在必行;另外,考虑到我们在测试中Celeborn相对Uniffle的内存消耗优势,以及Celeborn社区介绍的平滑升级、磁盘容错、基于负载的调度的特性,最终我们选择了在线上环境部署Celeborn。
Celeborn 上线
Celeborn 部署
在Celeborn之前,知乎使用ESS为Spark、MR作业提供Shuffle服务,ESS嵌入在NodeManager服务中,为了更好的ESS性能,缓存更多的Shuffle 分区元数据信息到内存,给NodeManager配置了比较高的内存。
我们上线RSS的目标除了解决Spark作业Shuffle稳定性和性能问题,同时希望不增加额外的机器成本,最终RSS可以完全平替ESS,所有作业迁移到RSS后,下线ESS,降低NodeManager的资源配置,整体不因为部署RSS增加资源开销。所以我们最终确定Celeborn跟Hadoop集群混合部署,每一台Hadoop节点部署一个Celeborn Worker服务。
为了保障Spark作业迁移到RSS过程的稳定性,作业分批进行灰度迁移,前期只在部分机器上部署Celeborn Worker服务,同时为了验证Spark作业迁移到RSS后是否确实有收益,在灰度上线阶段,避免ESS和RSS共用磁盘互相影响,我们对RSS使用的磁盘及ESS使用的磁盘进行了隔离,每台Hadoop机器有12块磁盘,DataNode依然同时使用所有磁盘,但是配置ESS只使用其中的10块磁盘,RSS使用另外2块磁盘,整体部署架构如下:
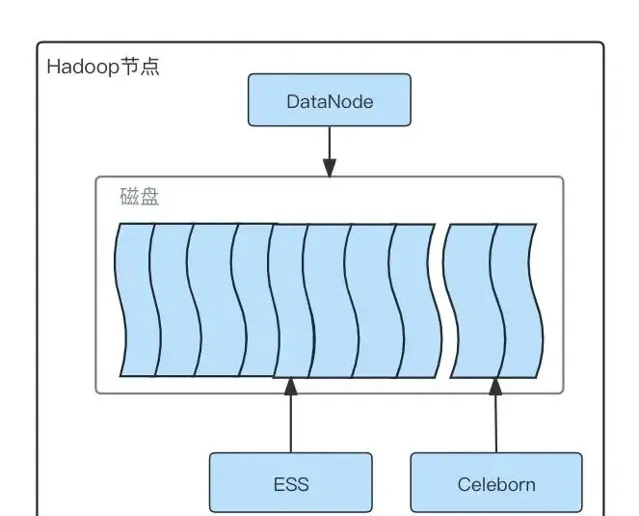
Celeborn部署磁盘分配图
Spark 作业迁移 Celeborn
迁移Spark作业到Celeborn Shuffle,需要解决两个问题:
1. 在灰度迁移过程中,如何对迁移的作业自动添加Celeborn相关Spark参数,如设置CelebornShuffleManger、Celeborn Master地址等,异常时支持快速回滚,避免人工手动修改;
2. 哪些作业更适合优先灰度迁移到Celeborn Shuffle。
针对自动修改Spark作业Celeborn参数问题,知乎之前做过一个Spark作业自动优化资源参数的项目,该项目支持通过规则自动修改Spark作业参数。在该项目中,通过改造Spark Launcher模块的逻辑,在Spark Launcher模块中采集用户Spark作业参数,使用采集的参数请求作业优化服务,作业优化服务基于不同规则计算新的Spark作业参数返回给客户端,客户端在收到返回的新参数后,修改用户原始参数,并使用新参数提交Spark作业。这个项目正好可以用到我们灰度迁移Spark 作业到Celeborn上,通过增加新的参数修改规则,以及黑白名单控制该规则对哪些队列、哪些作业生效,即可做到对我们预期的作业自动增删Celeborn参数。整体流程如下:
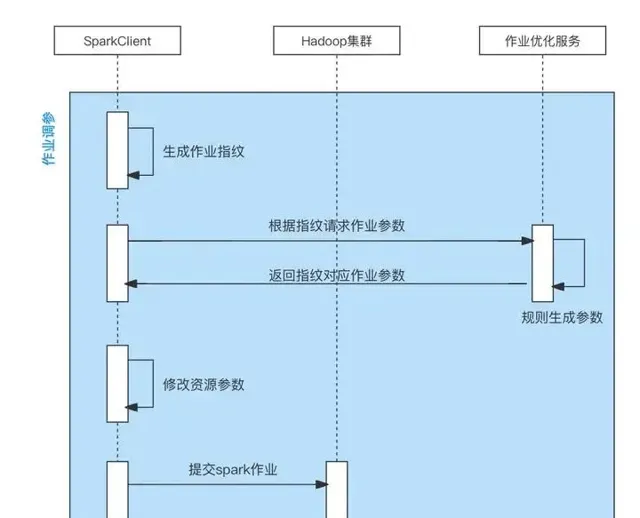
自动调整Spark作业Celeborn参数
在选择哪些作业优先灰度到RSS时,我们综合考虑了作业的优先级、作业Shuffle Read Block数、作业Shuffle Read Block平均大小(我们在Spark作业自动调参项目中采集了每个作业Shuffle Read大小、Shuffle Read Block数等Metric信息),为了降低RSS异常时对业务的影响以及尽快减少ESS磁盘IO压力,前期我们优先迁移的是作业优先级低的、Shuffle Read Block数多的、平均Shuffle Read Block Size小的作业,灰度几个批次后,符合条件的作业都已经迁移完成,后期就直接按照队列和作业优先级迁移了。
Celeborn 升级
知乎最初部署Celeborn时,是基于社区Release 0.3.1之后的main分支部署的,截止到我们迁移完所有Spark jar包类型的作业,我们部署的Celeborn已经落后社区最新代码几百个Commit,有些急迫的特性我们通过patch的方式在我们公司用了起来,但我们也想追齐社区最新的代码,包括一些bug的修复以及新特性。中间穿插着patch过几个社区的补丁,继续patch剩余补丁会有大量冲突,我们最终选择了使用社区最新代码直接替换我们在用的代码。
这样要面临一次整体集群的升级,Celeborn 支持滚动升级,无论是升级还是下线,都能够在不影响当前正在运行的作业的情况下进行。这种优雅的升级和下线方式,保证了业务的连续性和稳定性,避免了长尾作业的等待时间,提高了运维效率。
而且在部署层面,运维的感知就是部署了一个程序,然后检测到程序启动即可,很多的状态等等恢复工作 Celeborn 都会自动完成,不需要运维干预,相较于常规部署与升级 Hadoop 要简单很多。
同时这次的升级我们全程都在正常的工作时间进行,搭配自身的 Ansible 运维平台,我们只需极低的运维开发就可以实现数千个 Celeborn Worker 节点的运维。
Celeborn 兼容 Spark1.6
前面介绍过,我们最终的目标是期望Celeborn可以平替ESS,所有Spark作业的Shuffle都迁移到Celeborn,但是Celeborn官方不支持Spark1.6(发现所有的RSS开源实现都没有支持Spark1.6版本)。跟Celeborn社区交流后得知Celeborn之所以没有支持Spark1.6,是因为目前使用Spark1.6的公司已经很少,并不是无法支持。
但是知乎还有不少历史作业是使用Spark1.6实现的,每天大概600个作业,当时评估推动业务方升级作业Spark版本到Spark2、Spark3很困难,为了把所有Spark作业都迁移到RSS,我们自己实现了Celeborn Spark1.6的客户端,支持Spark1.6作业。
Spark1客户端相对于Spark2、Spark3版本最主要的不同在于处理Stage重试相关逻辑。Celeborn Spark高版本客户端在发生Shuffle Fetch Failed异常触发Stage重试时,通过Spark的MapOutputTracker接口清理异常Stage上游所有Map的输出,依赖TaskContext中的stage重试次数信息,决定是否生成新的Celeborn内部ShuffleID。Spark1中MapOutputTracker接口、TaskContext字段信息跟高版本不同,针对Spark1的Stage重试,我们在Celeborn侧ShuffleWriter尝试获取ShuffleID时,是否生成新的ShuffleID不依赖Stage重试信息,而是依赖当前Stage在用的ShuffleID是否发生了ShuffleFetch异常,发生过异常,则在后面同一个Shuffle Stage的Write任务申请ShuffleID时,分配新的ShuffleID;Spark侧在开启Celeborn Shuffle的情况下,发生Stage重试时,内部直接清理Shuffle Stage Output信息,保障重试时上游Stage所有Task的重新提交。
目前已经在所有Spark1.x作业上线,运行稳定,并且遇到异常Celeborn Worker节点导致FetchFailed时,可以触发Stage重试并成功。
遇到的问题
Kyuubi Spark SQL上线Celeborn后无法创建线程
知乎使用Kyuubi管理支持Spark SQL Adhoc查询的不同租户的Spark引擎,在两台高配服务器上部署了Kyuubi服务,Kyuubi服务在两台服务器上启动不同租户的多个Spark Yarn Client模式的实例用于支持公司所有用户的Spark SQL Adhoc查询。我们将Kyuubi启动的Spark作业Shuffle也迁移到了Celeborn。
在一次Celeborn服务从500节点扩容到700节点后,每当用户查询高峰时间段,所有Spark Driver日
志中都会有
OutOfMemoryError: unable to create new native thread
线
程创建异常的报错,导致大量用户查询失败,此时机器及Jvm内存都远没有达到上限。
通过跟Celeborn社区的交流,以及统计分析Spark Driver的线程栈,发现Celeborn针对每个Shuffle Stage都会启动新的线程池用于向分配给当前 Stage Shuffle资源的节点创建连接、预留Slot、提交Commit数据,而在我们的Kyuubi Spark Adhoc场景,每个Spark作业中可能同时运行大量SQL,大量的Shuffle Stage,单个Driver进程线程数高峰可能达到接近1w+个,其中Celeborn InitWorker、ReserveSlot、CommitFiles相关的线程累计8k+,当Worker节点是500时,因为需要连接的Worker相对少,扩容到700后,需要创建更多线程连接更多的Worker节点,怀疑线程数达到了上限。
在该问题发生时,我们检查了机器操作系统配置的线程数、进程数上限,分别是400w+、30w+,机器上实际启动的线程数并没有达到这个上限。在知乎,Kyuubi服务是通过Systemd启动的,Spark Driver进程都是Kyuubi的子进程,我们最终发现达到的上限是Systemd的DefaultTasksMax限制的,该配置会限制Systemd启动的服务以及该服务所有子进程可以使用的线程数上限(所有子进程累加),因为问题发生时,机器内存、CPU等资源还很富裕,所以我们增加了Systemd DefaultTasksMax的配置暂时解决了这个问题。
后续Celeborn社区对线程池创建相关逻辑进行了优化,不同Shuffle复用同一个InitWorker、ReserveSlot、CommitFiles线程池,目前该优化也已在知乎上线,大幅优化了创建的线程数。
Spark 作业设置 Celeborn 参数后不生效
对于迁移到Celeborn的作业,我们关闭了ESS,灰度迁移过程中,我们发现有个别作业执行更不稳定了,排查日志发现作业实际Shuffle的时候,并没有使用Celeborn,而是用了Spark原生Shuffle,Executor多次被驱逐导致作业不稳定。之所以开启了Celeborn Shuffle,最终却没有使用Celeborn Shuffle的原因是我们通过--jars参数配置的Celeborn客户端Jar,同时用户作业设置了参数 spark.executor.user classPathFirst=true 。同时设置该参数以及开启Celeborn Shuffle后,完整的Shuffle处理流程是:
1. Spark Executor启动的时候,检查到spark.executor.user classPathFirst配置为True,则初始化ChildFirstURL classLoader并在创建Task执行线程的时候设置线程 Context classLoader 为 ChildFirstURL classLoader 。
2. Executor使用Context classLoader中的ChildFirstURL classLoader反序列化接收到的Spark Task信息,其中就包括Task相关的RDD、ShuffleDependency等,ShuffleDependency中包含了ShuffleHandle实例
3. ChildFirstURL classLoader的实现截断了Java classLoader的双亲委托模型,优先使用ChildFirstURL classLoader自身去加载类,加载不到的情况下,才通过父加载器去加载,所以ChildFirstURL classLoader反序列化Task信息的时候,加载了CelebornShuffleHandle,并反序列化了ShuffleHandle实例。
4. Spark Executor默认的类加载器还是java默认的App classLoader,所以当直接引用CelebornShuffleHandle类时(
instanceof
检查时),会使用App classLoader加载CelebornShuffleHandle类。
5. Celeborn SparkShuffleManager 在创建 ShuffleWriter、ShuffleReader 时,会检查当前 ShuffleHandle 实例是否是 CelebornShuffleHandle 类型,然而因为当前 ShuffleHandle 实例是通过 ChildFirstURL classLoader 加载创建的,而 SparkShufflleManager 内部的 CelebornShuffleHandle 类是使用 App classLoader 加载的,两边 CelebornShuffleHandle 是使用的不同类加载器加载的,检查结果是 False ,最终使用了 Spark 原生的 Shuffle。
跟业务沟通后,发现业务作业可以去掉spark.executor.user classPathFirst=true参数配置,最终该问题通过修改作业参数解决。
Spark 作业中包含 GlobalLimit 算子时使用 RSS 问题
Spark Adhoc查询Shuffle切换到RSS后,业务反馈有个Spark SQL查询执行多次,总是失败。通过查看作业执行计划以及作业执行日志,发现因SQL语句中包含了Insert Hdfs Directory以及Limit逻辑,生成的作业执行计划中包含了GlobalLimit算子,而GlobalLimit算子会触发Shuffle,并且Shuffle下游并行度是1,同时该SQL作业结果在Limit之前的数据规模很大,TB级别。
在切换到RSS之前,GlobalLimit算子在进行Shuffle的时候,每个上游Task数据都是写本地,下游Task在Shuffle Read到Limit限制的数据后就结束了;切换到RSS之后,上游Task数据是写到RSS节点,并且属于同一个Reduce Task的数据会写到同一个RSS节点,也就是TB级别的数据会写同一个RSS节点,直接导致该RSS节点因数据写入太快,内存使用过高被Exclude,SQL执行失败。
GlobalLimit算子问题在我们这边是普遍存在的,在知乎Spark是Adhoc的底层查询引擎之一,每天会有大量的Spark SQL Adhoc查询,大量的Spark SQL查询复用一批Spark执行环境,节约启动耗时。为了减少复用的Spark环境的Driver内存压力,我们会自动修改用户的SQL,添加查询结果Insert Hdfs Directory的逻辑,查询平台再从Hdfs上读取结果给用户展示,同时在用户没有主动添加Limit的情况下,我们会自动给用户添加Limit限制。
这个问题不能通过修改单个SQL进行解决,我们调研发现Spark中有一个LocalLimit算子,该算子可以限制每个Spark RDD Partition的结果数据行数,于是我们的解决思路,就是给Spark添加一个执行计划优化规则,当执行计划中包含GlobalLimit算子,并且GlobalLimit算子的上游是一个Project算子(即Select)的情况下,自动在GlobalLimit算子前添加一个LocalLimit算子。
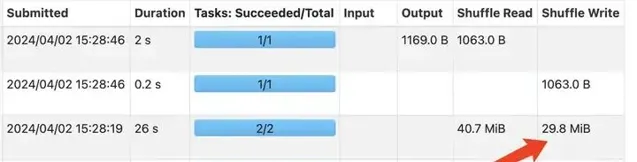
增加LocalLimit之前GlobalLimit算子Shuffle数据量
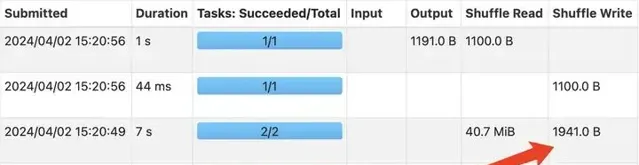
增加LocalLimit之后GlobalLimit算子Shuffle数据量
上面两张图是使用测试查询验证规则上线前后的效果对比情况,该规则上线后,GLobalLimit算子触发的Shuffle中,每个上游Task只需要Shuffle Write Limit限制的条数数据到RSS节点,不会再导致RSS节点Exclude,Limit前TB级数据规模的查询也可以正常执行,这种Case查询性能和稳定性都明显优化。
节点负载高导致 Shuffle 不稳定
知乎Celeborn是跟Hadoop部署到同一批机器上的,在作业灰度迁移的过程中,偶尔会发生个别机器负载很高,导致Commit超时或者Spark跟Celeborn通信超时,触发Shuffle异常,影响了作业执行稳定性,针对该问题,我们做了几个调整
增加Celeborn Shuffle RPC、Commit超时时间;
增加Worker Flush Buffer Size,从256K调整到1M,优化Commit耗时;
上线Celeborn基于磁盘负载的调度,所有磁盘分5组,每组之间Slot分配比例差距1.1倍,计算磁盘负载时Fetch、Flush耗时系数都是0.5;
打Celeborn社区Stage重试的补丁,当发生Shuffle 异常时,触发Stage重试,而不是App重试。
Celeborn Worker 连接数过高
灰度上线过程中,我们发现每个Worker节点的连接数很高,高峰时有的Worker 连接数达到1w个左右,跟社区沟通后,我们限制了每个作业最大使用的Worker节点数为500个,在后续我们持续扩容Worker节点数、迁移作业过程中,连接数基本稳定,没有持续增长。
celeborn.master.slot.assign.maxWorkers 500
收益
目前RSS使用1/6的集群磁盘资源,接入集群1/3+的Shuffle流量,作业迁移到RSS Shuffle后,作业执行性能明显优化,每天所有作业99分位数耗时提升30%以上;在持续有新作业上线的情况下,作业资源占用呈现下降的趋势。
作业性能优化
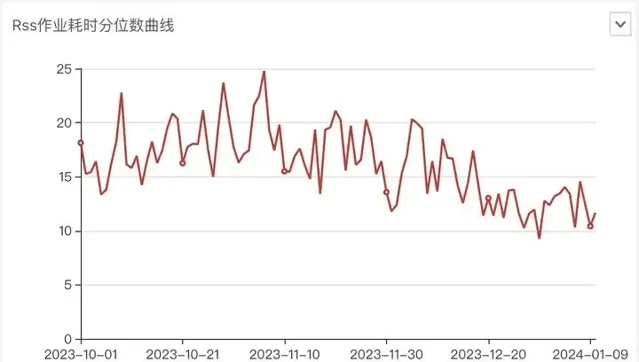
迁移RSS过程中 Spark作业耗时均值变化

迁移RSS过程中 Spark作业耗时99分位数变化
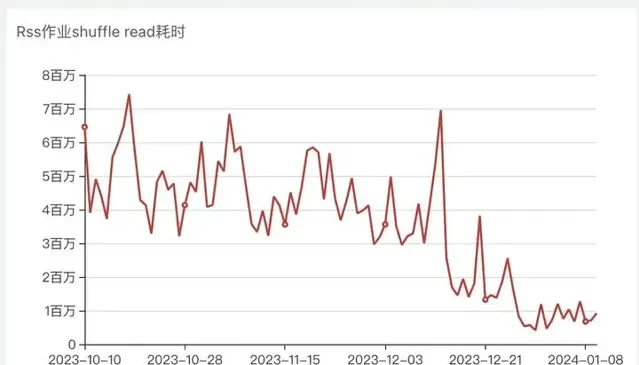
迁移RSS过程中 Spark作业Shuffle Read耗时变化
从作业整体分位数耗时、Shuffle耗时曲线看优化明显,大作业提速明显,所有作业99分位数耗时优化30%以上。
从用户反馈看,已经接入RSS Shuffle的作业,在性能和稳定性上都有了明显优化,业务方主动反馈作业变快了,近期我们也已经基本没有再收到用户反馈的shuffle耗时不稳定、shuffle连接异常等问题。
因为1/3以上的Shuffle流量切到了RSS,但是给RSS的磁盘只有整个集群的1/6,所以对于没有接入RSS的作业,也有明显的优化,公司核心例行作业结束时间提前了一个小时以上。
资源使用优化
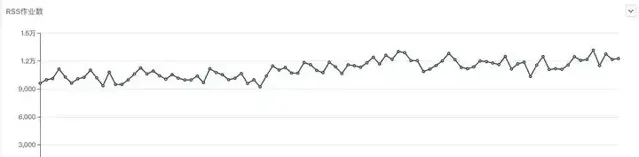
迁移RSS过程中 Spark作业每日作业数变化
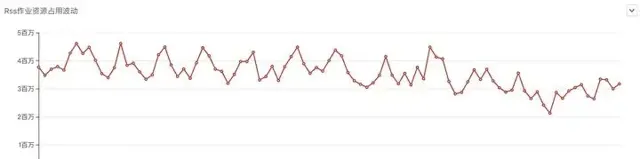
迁移RSS过程中 Spark作业每日内存资源占用变化
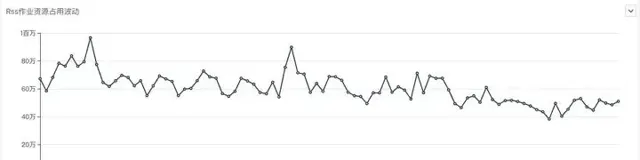
迁移RSS过程中 Spark作业每日CPU资源占用变化
从作业资源占用的角度看,也是有一些优化的,从截图中,可以看出,在RSS上线迁移过程中,公司一直有新作业上线,及时新增作业的情况下,所有作业CPU、内存占用有明显的下降趋势。
总结与展望
目前所有Spark Jar包、Spark SQL Adhoc作业均已接入RSS,并且取得了不错的效果,后续我们想在RSS方向继续做的事情包括:
Spark SQL ETL作业接入Celeborn
MR作业接入Celeborn
下线ESS服务,降低NodeManager内存占用
Celeborn更好的兼容高负载节点
参考
2. 知乎k8s在离线混部-离线篇
https://zhuanlan.zhihu.com/p/636970123
3. Magnet: Push-based Shuffle Service for Large-scale Data Processing
https://www.vldb.org/pvldb/vol13/p3382-shen.pdf











