整理 | 王启隆
出品 | CSDN
「 XX 公司发布的大模型突破十亿/百亿/数百亿/千亿 ... 参数! 」
近年来,像这样的新闻标题层出不穷,因为人工智能大模型领域的竞争焦点之一便是模型规模的不断扩张,参数量高达数百亿乃至数千亿的大模型引发了媒体和行业的广泛关注。
部分公司也注意到了这点,开始换个方向「卷」,试图用更小的参数实现同样的效果,比如来自法国的 Mixtral-7B 在这段时间就成为了圈内的明星产品。新闻标题也逐渐变成了:
「
XX 公司发布的模型只用 10B/7B/2B ... 就打赢了知名的 YY 大模型!
」
然而,微软和中国科学院大学提出了一项最新研究—— BitNet b1.58 大模型 ,直接从根源上「弯道超车」,让 1-bit 大模型彻底颠覆我们对大模型的传统认知。
原来「三进制」才是「版本答案」?
论文地址:https://arxiv.org/abs/2402.17764
这篇论文名为【 The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits 】,其前作【 BitNet: Scaling 1-bit Transformers for Large Language Models 】发布于去年 10 月。
当时,微软研究院、中国科学院大学和清华大学的研究者提出了一种名为 BitNet 的可扩展且稳定的 1-bit Transformer 架构,专为大型语言模型而设计。
传统的大语言模型通常采用的是高精度浮点数表示,比如 FP16 或 BF16 格式。这些格式可以理解为二进制系统下的小数表示法,它们能够存储从非常接近 0 到较大的数值范围内的连续值。
而在本次论文提出的 BitNet b1.58 大模型中, 参数不再是传统的浮点数,而是被量化为三元值 {-1, 0, 1} ,这意味着每个参数仅能取这三个离散的整数值。这种转变实际上是从二进制连续数值系统跨越到了一个「准三进制」的离散系统。
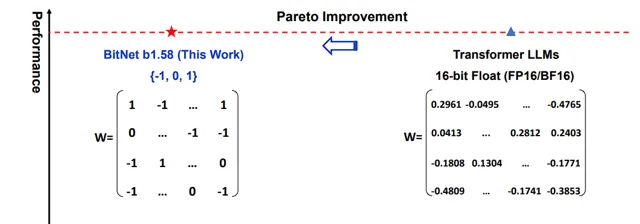
尽管计算机硬件的核心仍然是基于二进制进行运算,但通过将模型参数量化为三元状态,在训练和推理阶段就能够巧妙地 用加法操作取代传统的矩阵乘法 ,从而大幅削减计算复杂度。并且,在配合针对这类低精度模型优化的硬件技术后,还能进一步提升执行速度。
如此一来,在确保模型性能基本不变的前提下,显著降低了计算所需的资源、存储空间以及数据在内存与处理器间传输的成本。
用网友的话来说, 我们未来或许能用一张 24G 显存的显卡——甚至用消费级的 GPU 来运行 120B 的大模型。

更有甚者,直接剑指老黄,寄希望于 1-bit 大模型推翻 NVIDIA 王朝。
当前这篇论文可谓是备受瞩目,在 X 上的点赞有 2.4k,阅读量也逼近了 40 万大关。

接下来,让我们深入技术细节,看看所谓的「1-bit 大模型」到底是怎么回事。
1-bit 大模型的创新秘诀
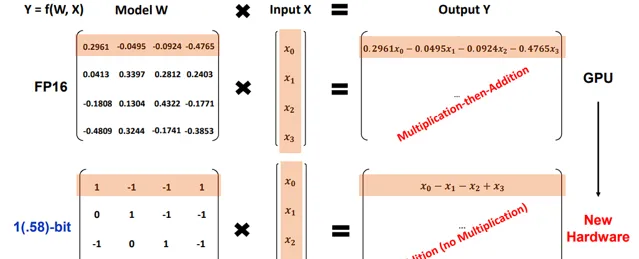
论文的前面就有提到, BitNet b1.58 依旧基于去年提出的 BitNet 架构构建,该架构是一种对传统 Transformer 模型进行了特定改造的变体。在 Transformer 中通常会使用 nn.Linear 层来实现线性变换,而在 BitNet 架构中,则将这部分替换为 BitLinear 层。这意味着 BitNet 设计了一种新的权重表示和计算机制,可能是为了适应低 bit 量化的特性。
想理解这个 BitNet b1.58 大模型首先要从其架构入手,该架构建立在三大基础之上:时空视频标记器( spatiotemporal video tokenizer )、自回归动态模型( autoregressive dynamics model )和潜在动作模型( latent action model )。每个组件都经过微调以适应前文提到的 {-1, 0, 1} 三元参数,使得模型能够在没有直接动作标签( direct action labels )的情况下从互联网上的无标注视频中学习。
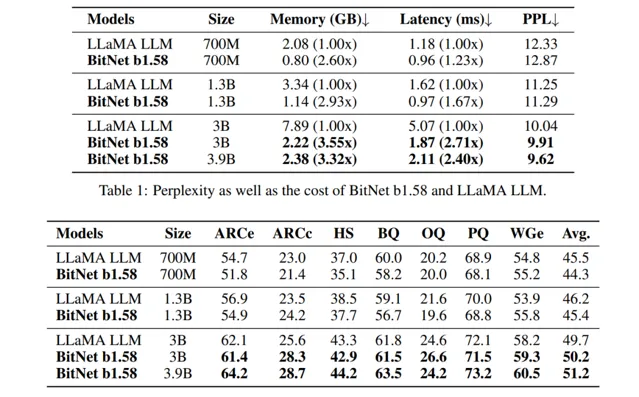
接下来再看一看 BitNet 的「PK 结果」,参照对象当然是 常被拉出来对比的「国际靶场」 LLaMA; 为了公正地比较 BitNet b1.58 与基于 FP16 的 LLaMA 大模型在不同规模下的性能,研究者首先对这些模型进行了重新训练。具体来说,所有模型都在 RedPajama 数据集上进行了预训练,训练量达到了 1000 亿个 tokens,确保了对比基准的一致性。
评估中重点关注了模型每输出一个 token 所需的时间,因为这在推断过程中占据主要成本。 结果显示,在模型规模达到 30 亿参数时,BitNet b1.58 开始能与全精度的 LLaMA 大模型相匹敌, 同时在速度上快了约 2.71 倍 ,且使用的 GPU 内存减少了 3.55 倍 。
具体而言,当 BitNet b1.58 模型大小提升至 39 亿参数时,其速度比 LLaMA-30b 快了约 2.4 倍 ,占用的内存 减少了约 3.32 倍 ,但性能表现却显著优于 LLaMA-30b。
如此震撼的结果,使得江湖上就此流传起 BitNet 的名字……
实际上,为了更好地融入开源社区, BitNet b1.58 还采用了类似于 LLaMA 的设计元素。 这样的设计使得 BitNet b1.58 能够轻松地集成到各种流行的开源软件平台中,如 Huggingface、vLLM 以及 llama.cpp 等项目,可以轻松完成整合。
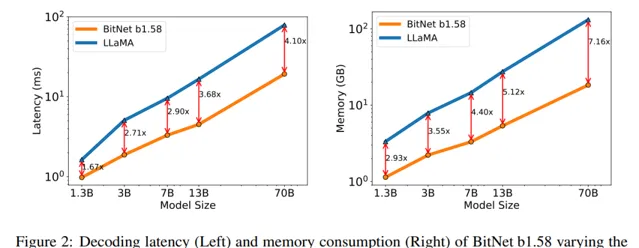
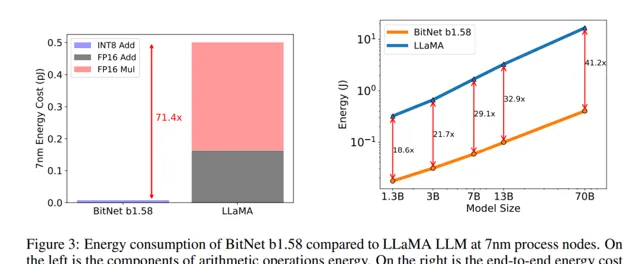
通过减少对高精度计算的依赖,BitNet b1.58 为在资源受限环境下部署先进的大模型开辟了新可能,其中也包括移动设备和边缘计算平台。作为参考,我们可以 基于如上两张图片的实验结果,将不同规模的 BitNet b1.58 模型与 16-bit( 即 F P16 )大模型进行对比:
对于拥有 130 亿参数的 BitNet b1.58 模型,在延迟、内存使用以及能源消耗这三个关键指标上,其效率优于同等大小为 30 亿参数的 FP16 大模型。
同样地,300 亿参数规模的 BitNet b1.58 模型在上述三个方面表现出来的效率要高于 70 亿参数的 FP16 大模型。
更进一步,当模型参数量扩大到 700 亿时,1.58-bit 的 BitNet b1.58 依然能够在延迟、内存占用及能耗方面,比具有 130 亿参数的 FP16 大模型更加高效。
随着模型参数数量的增长,BitNet b1.58 在保持甚至提高计算性能的同时,相较于相同或更大规模的全精度浮点数大模型,显著降低了运行时所需的时间(延迟)、内存资源和能源消耗,从而展现出了更强的扩展性和更优的成本效益。
论文地址: https://arxiv.org/abs/2402.17764
AI 赋能物联网?
站在人工智能新时代的门槛上,BitNet b1.58 不仅代表了向可持续 AI 发展迈出的重要一步,也为未来的创新奠定了基础。它的出现或许在呼吁开发者转向低成本+环保的 AI 模型,促使开发者重新评估如何设计、训练和部署大模型。
随着这类高效能模型的发展, 原本只能在云端运行的大规模语言模型有望实现在终端设备上的本地化部署 ,它们在资源有限的边缘计算设备上具有广阔的应用前景。这将推动智能家电、可穿戴设备以及各类嵌入式系统实现更高性能的自然语言交互功能。
此外,1-bit 大模型所采用的架构在硬件成本方面具有显著优势:正 如前文所述,通过在某些计算阶段以加法操作替代传统的矩阵乘法,有效地减少了对晶体管数量的需求。
无论是电子游戏图形渲染还是神经网络深度学习,都需要大量并行执行浮点数运算,这份高性能需求为英伟达等公司赢得了当前市场主导地位。然而,1-bit 架构的创新则为其他硬件制造商提供了赶超和颠覆现有格局的可能性。
可以预见,1-bit 大模型很有可能成为驱动 AI 硬件领域变革的关键力量,引领一场新的技术革命。
4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「 全球机器学习技术大会 」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。 欢迎所有开发者朋友访问官网 http://ml-summit.org、点击「阅读原文」或扫描下方海报中的二维码 ,进一步了解详情。












