今天这个题目比较有意思。
在核查产品时,为了不遗漏,我们往往需要把产品名称中的代码和规格型号拆分出来方便统计核对。
下表我截取了一份公司的【标准件规格统计表】给大家。在遵循一定规则的前提下,标准件的规格型号的表达形式有千种万种:
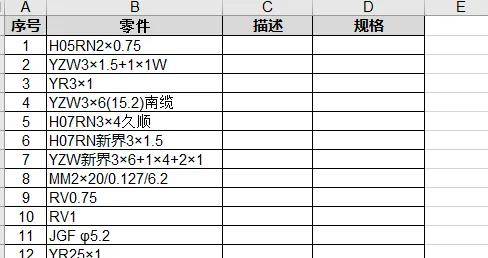
现在我们需要将标准件的名称拆分为两部分: 代码( 描述 )部分及具体的规格型号,如下表。
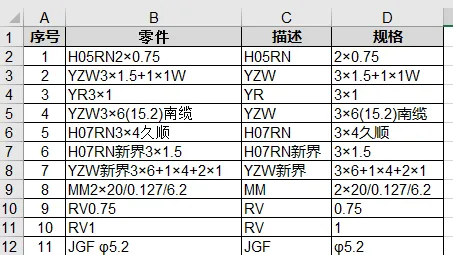
这就牵扯到数据拆分,而凡是这种操作都离不开查找、引用等函数。 所以,这里的思路是: 找到代码(描述)部分和规格部分的界限,再利用提取函数进行提取和拆分。
但是观察一下这份源数据中产品的代码和规格型号很杂乱,没有规律可言。那如何才能将两者精确拆分开呢?
真的没有规律吗?其实还是有一定规律的:
(1)凡是有「×」符号的规格型号都是从第一个「×」前的数字开始的
(2)有一个产品的规格型号是从空格后开始的(JGF φ 5.2 → φ 5.2 )
(3)没有「×」符号和空格的两个零件的规格型号可以虚拟添加「×」,然后也是从第一个「×」前的数字开始的
RV0.75 →RV0.75 × →0.75 ×
RV1 → RV1 × → 1 ×
如何运用这里的规律呢?当然还得继续整合或者创造规律:
(1)和(3)均是从第一个「×」前的最后一个非数字(字母、汉字)后开始规格型号的
(2)也可以认为是从第一个空格前的最后一个非数字(字母、汉字)后开始规格型号的
到了这里,我们可以得出一个思路 (尽管还不知道用什么函数实现):
将产品信息看作是一串数字、非数字组成的信息,然后从左向右提取到第一个分界标志「×」或空格前的最后一个非数字处,即可得到代码(描述)部分;剩下的就是规格型号部分。
这个思路的关键: 将信息的每个字符判断成一串代表数字和非数字的序列;用「×」或空格作为参考位置,然后向前寻找最后一个非数字的字符位置。
思考十秒钟,让我们一起来烧脑吧!
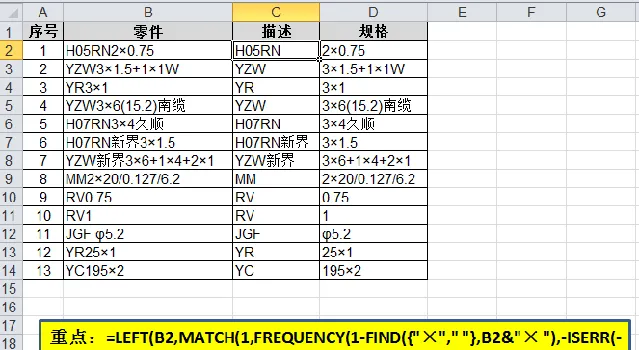
在单元格C2中输入公式「=LEFT(B2,MATCH(1,FREQUENCY(1-FIND({"×"," "},B2&"× "),-ISERR(-(0&MID(B2&"× ",ROW($1:$99),1)))*ROW($1:$99)),))」并向下拖曳即可。
函数解析:
a) FIND({"×"," "},B2&"× ") 部分用于获得参考位置,1-FIND(),其结果为{-6,-12},将参考位置变成负数并向前移一位。
为什么B2要添加后缀"× " (×和空格)?我们用第一个「×」和" " 的位置作为参考,添加后缀"× "可以令FIND函数不论如何都能查找到"×"和" ",避免FIND函数报错。
b) -ISERR(-(0&MID(B2&"× ",ROW($1:$99),1)))*ROW($1:$99)) 部分返回一个序列数组,每个负数对应一个非数字字符(字母或者汉字、符号),每个0对应一个数字字符。得到的序列如下:
{-1;0;0;-4;-5;0;-7;0;0;0;0;-12;0;0;0;0;0;……}( 此处只截取了序列前方部分)
字符串B2后添加"× "是为了让字符串与上面查找的字符串保持一致,避免后续出现计算错误。
c) FREQUENCY() 部分,计算 参考位置前移后数组{-6,-12} 在序列中各值段的出现频率。根据FREQUENCY函数的特性,分别在-5和-12的位置上各计频1,得到如下序列:
{0;0;0;0; 1 ;0;0;0;0;0;0; 1 ;0;0;0;0;0;……}( 此处只截取了序列前方部分)
d) 再利用MATCH函数查找1,返回上述序列值中第一个1的位置5。至此得到了「×」和空格前的最后一个非数字字符的位置。
e) 最后用LEFT函数提取5个字符得到描述部分H05RN。
代码部分完成后,规格型号部分就非常简单了,使用SUBSTITUTE函数配合TRIM函数就可以完成。
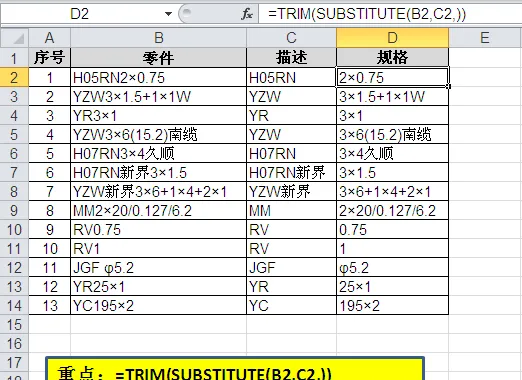
1. SUBSTITUTE (B2,C2,)部分显示的是用空白替换在B2字符中,与C2相同的字符内容,即留下除去C2字符内容的B2的剩下字符。
2. =TRIM() 即除了单词之间的单个空格外,清除字符中所有的空格。
这个题目思路整体上比较复杂,小伙伴们一时不能理解也没有关系,在实际工作中如果遇到类似的问题会套用即可。
最后,欢迎加入Excel函数训练营,学习68个函数、配套练习课件、辅导答疑。











