點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 量子位授權
一張人像、一段音訊參考,就能讓黴黴在你面前唱碧昂絲的【Halo】。
一種名為 Hallo 的研究火了,GitHub已攬星1k+。
話不多說,來看更多效果:
不論是說話還是唱歌,都能和各種風格的人像相匹配。從口型到眉毛眼睛動作,各種五官細節都很自然。
單獨拎出不同動作強度的比較,動作振幅大也能駕馭:
單獨調整嘴唇運動振幅,表現是這樣嬸兒的:
有不少網友看過效果後,直呼這是目前最好的開源口型同步視訊生成:
這項工作由來自復旦大學、百度、蘇黎世聯邦理工學院和南京大學的研究人員共同完成。
團隊提出了 分層的音訊驅動視覺合成模組 ,將人臉劃分為嘴唇、表情和姿態三個區域,分別學習它們與音訊的對齊關系,再透過自適應加權將這三個註意力模組的輸出融合在一起,由此可以更精細地建模音視訊同步。

Hallo長啥樣?
如前文所述,Hallo透過使用參考影像、音訊序列以及可選的視覺合成權重,結合基於分層音訊驅動視覺合成方法的擴散模型來實作。
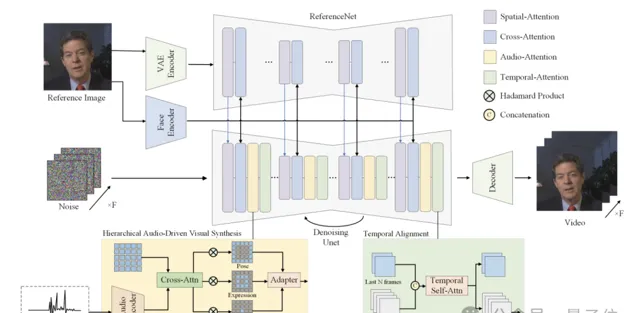
整體架構是這樣嬸兒的:
參考影像經過一個ReferenceNet編碼全域視覺特征;人臉編碼器提取身份相關的特征;音訊編碼器將輸入語音轉換為與運動相關的特征表示;分層音訊驅動視覺合成模組用於在唇部、表情、姿態三個層次建立音視訊的關聯;最後透過擴散模型中的UNet完成去噪,生成視訊幀。
擴 散模型主幹網路 (Diffusion Backbone)
采用Stable Diffusion 1.5作為基礎架構,包括三個主要部份:VQ-VAE編碼器、基於UNet的去噪模型、條件編碼模組。與傳統的文本驅動擴散模型不同,Hallo去掉了文本條件,轉而使用音訊特征作為主要的運動控制條件。
參考影像編碼器 (ReferenceNet)
ReferenceNet用於從參考影像中提取全域視覺特征,指導視訊生成過程的外觀和紋理。結構與擴散模型的UNet解碼器共享相同的層數和特征圖尺度,便於在去噪過程中融合參考影像特征。在模型訓練階段,視訊片段的第一幀作為參考影像。
時序對齊模組 (Temporal Alignment)
Temporal Alignment用於建模連續視訊幀之間的時間依賴關系,保證生成視訊的時序連貫性。從前一推理步驟中選取一個子集 (例如2幀) 作為運動參考幀,將其與當前步驟的latent noise在時間維度上拼接,透過自註意力機制建模幀間的關聯和變化。
此外, 分層音訊驅動視覺合成 方法是整個網路架構的核心部份。
其中人臉編碼器,使用預訓練的人臉辨識模型,直接從參考影像提取高維人臉特征向量;音訊編碼器使用wav2vec模型提取音訊特征,並透過多層感知機對映到運動特征空間,由此可以將語音轉換為與面部運動相關的特征表示,作為視訊生成的條件。
之後再將音訊特征分別與唇部、表情、姿態區域的視覺特征做交叉註意力,得到三個對齊後的特征表示,再透過自適應加權融合為最終的條件表示。
該方法還可以透過調節不同區域註意力模組的權重,來控制生成視訊在表情和姿態上的豐富程度,可適應不同的人物面部特征。
Hallo表現如何?
之後研究團隊將Hallo與SadTalker、DreamTalk、Audio2Head、AniPortrait等SOTA方法進行定量和定性比較。
用HDTF和Bilibili、Youtube等來源的數據構建了一個大規模人像視訊數據集,經過清洗後用於訓練。
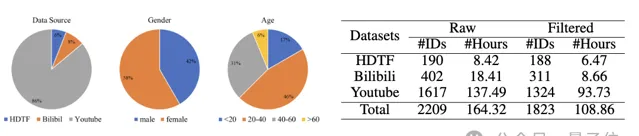
評估指標方面, 采用FID、FVD評估生成視訊的真實性,Sync-C、Sync-D評估唇形同步性,E-FID評估生成人臉的保真度 。
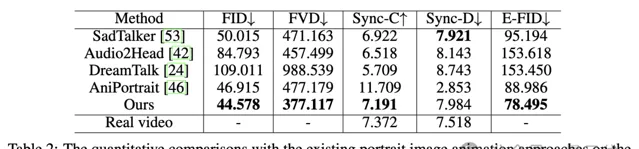
定量評估方面,在HDTF數據集上,Hallo在多個指標上表現最優:

在增強唇部同步的同時,Hallo保持了高保真視覺生成和時間一致性:

在CelebV數據集上,Hallo展示了最低的FID和FVD以及最高Sync-C:
視覺化比較如下:

在自建Wild數據集上,Hallo同樣表現突出:
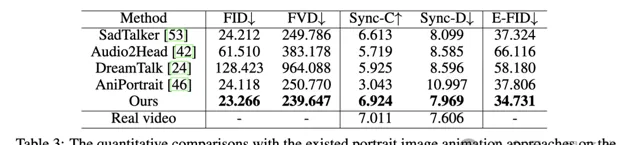
針對不同數據集的定性比較結果如下。
Hallo展示了對不同風格人像的驅動生成能力,體現了該方法的泛化和魯棒性:

同時展示了對不同音訊的響應能力,能夠生成與音訊內容契合的高保真視訊:

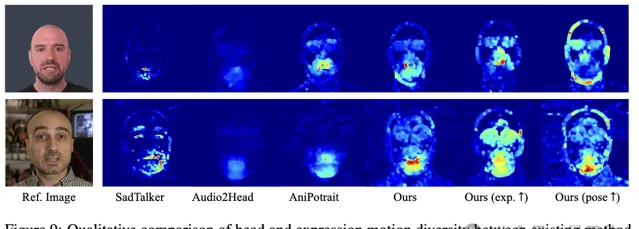
與其它方法對比,Hallo展示了更豐富自然的表情和頭部運動:
透過特定人物數據微調,展示了該方法捕獲人物特征、個人化生成的能力:

最後研究人員還進行了消融實驗,並總結了該方法的局限性,比如在快速運動場景下時序一致性還有待提高,推理過程計算效率有待最佳化等。
此外,經作者介紹,目前Hallo僅支持固定尺寸的人像輸入。
且該方法目前也不能實作即時生成。

針對這項研究,也有網友提出Deepfake隱患,對此你怎麽看?

參考連結:
[1]https://fudan-generative-vision.github.io/hallo/#/
[2]https://github.com/fudan-generative-vision/hallo
[3]https://x.com/JoeSiyuZhu/status/1801780534022181057
[4]https://x.com/HalimAlrasihi/status/1802152918432334028












