導讀
ClickHouse是一款開源的列式資料庫管理系統,適用於線上分析處理(OLAP)場景,本文透過介紹ClickHouse, 幫助讀者今後 快速地處理大規模數據,並獲得即時的分析結果,為業務提供有力支持。
01
前言
在今年的敏捷團隊建設中,我透過Suite執行器實作了一鍵自動化單元測試。Juint除了Suite執行器還有哪些執行器呢?由此我的Runner探索之旅開始了!
架構,軟體開發中最熟悉不過的名詞,遍布在我們的日常開發工作中,大到計畫整體,小到功能元件,想要實作高效能、高擴充套件、高可用的目標都需要優秀架構理念輔助。所以作者嘗試剖析市面上那些經典優秀的開源計畫,學習優秀的架構理念來積累架構設計的經驗與思考,在後續日常工作中遇到相同問題時能有更深一層的認知。
本章以即時OLAP引擎ClickHouse(簡稱ck)為例,以其面向場景,架構設計,細節實作等方面來介紹,深度了解其如何成為了OLAP引擎中的效能之王。
02
ClickHouse簡介
理解,首先 MCube 會依據樣版緩存狀態判斷是否需要網路獲取最新樣版,當獲取到樣版後進行樣版載入,載入階段會將產物轉換為檢視樹的結構,轉換完成後將透過運算式引擎解析運算式並取得正確的值,透過事件解析引擎解析使用者自訂事件並完成事件的繫結,完成解析賦值以及事件繫結後進行檢視的渲染,最終將目標頁面展示到螢幕。
ClickHouse是俄羅斯Yandex(俄羅斯網路使用者最多的網站)於2016年開源的一個用於線上分析(OLAP)的列式資料庫管理系統,采用C++語言編寫,主要用於線上分析處理查詢,透過SQL查詢即時生成分析數據報告。
主要面向場景是 快速支持任意指標、任意維度並且可以在大數據量級下實作秒級反饋的Ad-hoc查詢(即席查詢) 。
03
ClickHouse架構原理
理解,首先 MCube 會依據樣版緩存狀態判斷是否需要網路獲取最新樣版,當獲取到樣版後進行樣版載入,載入階段會將產物轉換為檢視樹的結構,轉換完成後將透過運算式引擎解析運算式並取得正確的值,透過事件解析引擎解析使用者自訂事件並完成事件的繫結,完成解析賦值以及事件繫結後進行檢視的渲染,最終將目標頁面展示到螢幕。
ClickHouse以其卓越的效能著稱,在相關效能對比報告中,ck在單表SQL查詢的效能是presto的2.3倍、impala的3倍、greenplum的7倍、hive的48倍。可以看出ck在單表查詢是非常出色的,那麽ck究竟是如何實作高效查詢的呢?
3.1 引子
介紹ck查詢原理之前先以最常見的mysql為例,一條簡單的查詢語句是如何執行的,然後再以ck架構師的角度去考慮ck應該如何最佳化。mysql查數據時會先從磁盤讀出數據所在 頁(innodb儲存單元) 到記憶體中,然後再從記憶體中返回查詢結果,所以在我們的認知中sql查詢(排除語法詞法解析,最佳化等步驟)總結起來可以為以下兩點:
1.磁盤讀取數據到記憶體
2.記憶體中解析數據匹配結果返回
在現代電腦中,CPU參與運算的時間遠小於磁盤IO的時間。所以現代OLAP引擎大部份也選擇透過降低磁盤IO的手段來提高查詢效能,舉例如下:
|
降低磁盤IO
|
原理
|
舉例
|
劣勢
|
|
分布式
|
並列讀取數據,降低單節點讀取數據量
| hive(texfile) | 數據傾斜,網路耗時,資源浪費 |
|
列式儲存
|
將每一列單獨儲存,按需讀取
| hbase | 適合列使用單一的業務 |
3.2 架構
透過以上推導分析,我們可以得出OLAP查詢瓶頸在於磁盤IO,那麽ck的最佳化手段也是借鑒了以上措施,采用了 MPP架構(大規模並列處理) +列式儲存, 擁有類似架構設計的其他資料庫產品也有很多,為什麽ck效能如此出眾?接下來我們具體分析ck的核心特性,進一步體會ck架構師的巧妙的架構理念。
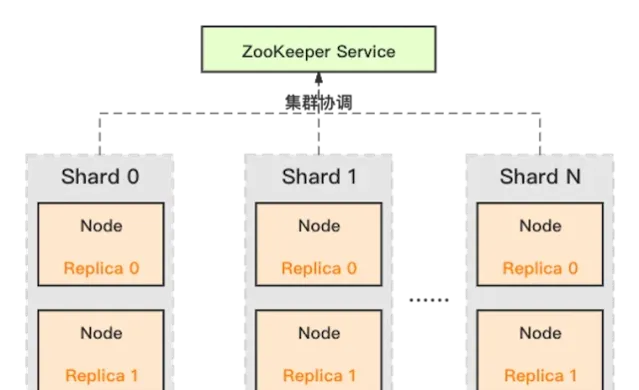

3.2.1 列式儲存
行式儲存:把同一行數據放到同一數據塊中,各個數據塊之間連續儲存。
列式儲存:把同一列數據放到同一數據塊中,不同列之間可以分開儲存。

如同上述所講,分析類查詢往往只需要一個表裏很少的幾個欄位,Column-Store只需要讀取使用者查詢的column,而Row-Store讀取每一條記錄的時候會把所有column的數據讀出來,在IO上Column-Store比Row-Store效率高得多,因此效能更好。
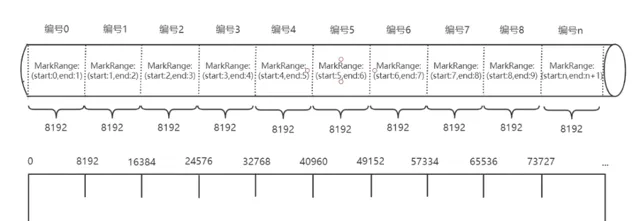
3.2.2 block
ClickHouse能處理的最小單位是block,block是一群行的集合,預設最大為8192行。因為每一列單獨儲存,因此每個數據檔相比於行式儲存更有規律,透過對block采用LZ4壓縮演算法,整體壓縮比大致可以8:1。可以看出, ClickHouse透過出色的壓縮比與block結構實作了批次處理功能, 對比海量數據儲存下每次處理1行數據的情況, 大幅減少了IO次數 , 從而達到了儲存引擎上的最佳化。
3.2.3 LSM
LSM的思想
: 對數據的修改增量保持在記憶體中,達到指定的限制後將這些修改操作批次寫入到磁盤中,相比較於寫入操作的高效能,讀取需要合並記憶體中最近修改的操作和磁盤中歷史的數據,即需要先看是否在記憶體中,若沒有命中,還要存取磁盤檔
LSM的原理 : 把一顆大樹拆分成N棵小樹,數據先寫入記憶體中,隨著小樹越來越大,記憶體的小樹會flush到磁盤中。磁盤中的樹定期做合並操作,合並成一棵大樹,以最佳化讀效能。
ClickHouse透過LSM實作數據的預排序,從而減少磁盤的讀取量。 原理就是將亂序數據透過LSM在記憶體中排序,然後寫入磁盤保存,並定期合並有重合的磁盤檔。ClickHouse的寫入步驟可以總結為以下幾點:
1.每一批次數據寫入,先記錄日誌, 保證高可用機制
2.記錄日誌之後存入記憶體排序,後將有序結果寫入磁盤,記錄合並次數Level=0
3.定期將磁盤上Level=0或1的檔合並,並標記刪除,後續物理刪除
3.2.4 索引
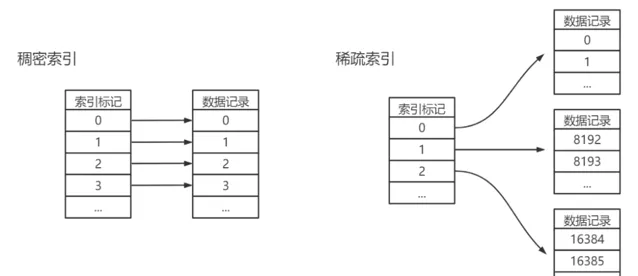
ClickHouse的采用 一級索引(稀疏索引) +二級索引(跳數索引)來實作索引數據定位與查詢。一級索引記錄每個block塊的第一個,每次基於索引欄位查詢只需要確定查詢第幾個block塊即可,避免一個查詢遍歷所有數據。如上述介紹,一個block塊為8192行,那麽1億條數據只需要1萬行索引,所以一級索引占用儲存較小,可常駐記憶體,加速查詢。 二級索引由數據的聚合資訊構建而成,根據索引型別的不同,其聚合資訊的內容也不同,跳數索引的目的與一級索引一樣,也是幫助查詢時減少數據掃描的範圍,原則都是「排除法」,即盡可能的排除那些一定不滿足條件的索引粒度。
另一方面可以發現,因ck儲存引擎按有序集合儲存,所以在索引結構上,並不需要再利用B+樹排序特性來定位。所以在實際使用過程中,也不需要滿足最左原則匹配,只要過濾條件中包含索引列即可。
3.2.5 向量化執行
向量化計算(vectorization) ,也叫vectorized operation,也叫array programming,說的是一個事情:將多次for迴圈計算變成一次計算。為了實作向量化執行,需要利用CPU的SIMD指令。SIMD的全稱是Single Instruction Multiple Data,即用 單條指令操作多條數據 。現代電腦系統概念中,它是透過 數據並列以提高效能 的一種實作方式 ( 其他的還有指令級並列和執行緒級並列 ),它的 原理是在CPU寄存器層面實作數據的並列操作。
在電腦系統的體系結構中,儲存系統是一種階層。典型伺服器電腦的儲存階層如圖6所示。一個實用的經驗告訴我們,儲存媒介距離CPU越近,則存取數據的速度越快。

從左至右,距離CPU越遠,則數據的存取速度越慢。從寄存器中存取數據的速度,是從記憶體存取數據速度的300倍,是從磁盤中存取數據速度的3000萬倍。所以利用CPU向量化執行的特性,對於程式的效能提升意義非凡。ClickHouse目前利用SSE4.2指令集實作向量化執行。
04
ClickHouse
總結理解,首先 MCube 會依據樣版緩存狀態判斷是否需要網路獲取最新樣版,當獲取到樣版後進行樣版載入,載入階段會將產物轉換為檢視樹的結構,轉換完成後將透過運算式引擎解析運算式並取得正確的值,透過事件解析引擎解析使用者自訂事件並完成事件的繫結,完成解析賦值以及事件繫結後進行檢視的渲染,最終將目
4.1 ClickHouse的舍與得
ClickHouse在追求極致效能的路上,采取了很多優秀的設計。如上述講的列存、批次處理、預排序等等。但是架構都有兩面性,從一另方面也帶來了一些缺點。
• 高頻次即時寫入方面 ,因ck會將批次數據直接落盤成小檔,高頻寫入會造成大量小檔生成與合並,影響查詢效能。所以ck官方也是建議大批低頻的寫入,提高寫入效能。實際場景中建議在業務與資料庫之間引入一層數據緩存層,來實作批次寫入。
• 查詢並行問題 ,ClickHouse是采用並列處理機制,即一個查詢也會使用一半cpu去執行,在安裝時會自動辨識cpu核數,所以在發揮查詢快的優勢下,也帶來了並行能力的不足。如果過多的查詢數堆積達到max_concurrent_queries閾值,則會報出too many simultaneous queries異常,這也是ck的一種限流保護機制。所以日常使用過程中註意慢sql的排查,並行請求的控制是保證ck高可用的關鍵。
了解其原理之後,能夠對ClickHouse有更深的認知,也能夠解釋生產工作中曾經遇到的問題,站在ClickHouse架構師的角度去合理使用,規避劣勢,發揮其特性。
4.2 ClickHouse在實際生產中遇到的問題
4.2.1 zookeeper高負載影響
目前ClickHouse開源版本ReplicatedMergeTree引擎強依賴zookeeper完成多副本選主,數據同步,故障恢復等功能,zookeeper在負載較高的情況下,效能表現不佳,甚至會出現副本無法寫入,數據無法同步問題。分析ClickHouse對zookeeper相關的使用,以副本復制流程為例,ck對zookeeper頻繁的分發日誌、數據交換是引起瓶頸原因之一。
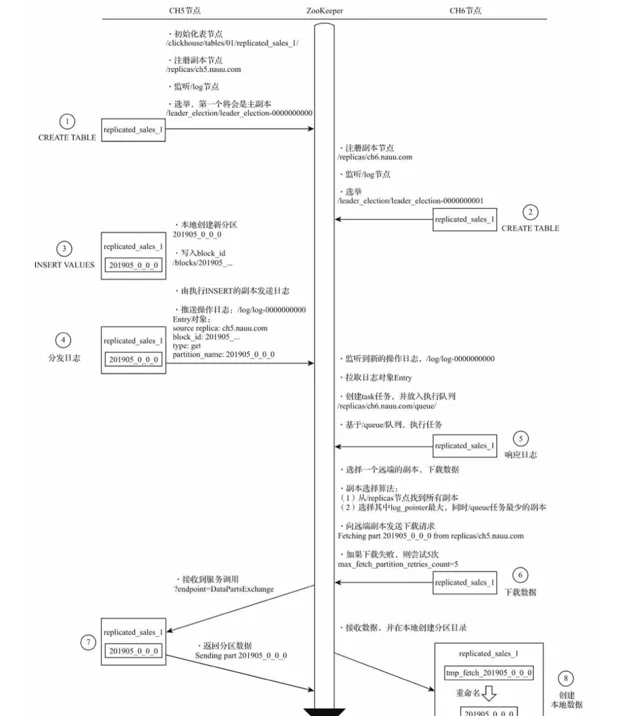
外界解決通用方案:
重新實作HaMergeTree引擎,降低對zookeeper日誌的請求次數並減少儲存的數據量,來達到降低對zookeeper的負載。
京東零售:自研基於Raft分布式共識演算法的zookeeper替代方案。
4.2.2 資源管控問題
ClickHouse的資源管控能力不夠完善,在 insert、select 並行高的場景下會導致執行失敗,影響使用者體驗。這是因為社群版ClickHouse目前僅提供依據不同使用者的最大記憶體控制,在超過閾值時會殺死執行的 query。
外界解決通用方案: 開發資源管理元件,將並行、記憶體、CPU等資源拆分給不同的資源組,同時透過資源組的父子關系實作不同資源組共享部份資源的能力。
求在看
打造SAAS化服務的會員徽章體系,可以作為標準的產品化方案統一對外輸出。結合現有平台的通用能力,實作會員行為全路徑覆蓋,並能結合企業自身業務特點,規劃相應的會員精準行銷活動,提升會員忠誠度和業務的持續增長。
▪
底層能力:維護使用者基礎數據、行為數據建模、使用者畫像分析、精準行銷策略的制定
▪ 功能支撐:會員成長體系、等級計算策略、權益體系、行銷底層能力支持
▪使用者活躍:會員關懷、使用者觸達、活躍活動、業務線交叉獲客、拉新促










