RocketMQ作為阿裏開源的訊息中介軟體,深受廣大開發者的喜愛
而這其中一個很重要原因就是,它處理訊息和拉取訊息的速度非常快
那麽,問題來了,RocketMQ為什麽這麽快呢?
接下來,我將從以下10個方面來探討一下RocketMQ這麽快的背後原因
如果你對RocketMQ還不了解,可以從公眾號後台選單欄中檢視我之前寫的關於RocketMQ的幾篇文章
如果你對RocketMQ源碼也感興趣,可以從下面這個倉庫fork一下源碼,我在源碼中加了中文註釋,並且後面我還會持續更新註釋
https://github.com/sanyou3/rocketmq.git
本文是基於RocketMQ 4.9.x版本講解
批次發送訊息
RocketMQ在發送訊息的時候支持一次性批次發送多條訊息,如下程式碼所示:
public classProducer{
publicstaticvoidmain(String[] args)throws Exception {
//建立一個生產者,指定生產者組為 sanyouProducer
DefaultMQProducer producer = new DefaultMQProducer("sanyouProducer");
// 指定NameServer的地址
producer.setNamesrvAddr("192.168.200.143:9876");
// 啟動生產者
producer.start();
//用以及集合保存多個訊息
List<Message> messages = new ArrayList<>();
messages.add(new Message("sanyouTopic", "三友的java日記 0".getBytes()));
messages.add(new Message("sanyouTopic", "三友的java日記 1".getBytes()));
messages.add(new Message("sanyouTopic", "三友的java日記 2".getBytes()));
// 發送訊息並得到訊息的發送結果,然後打印
SendResult sendResult = producer.send(messages);
System.out.printf("%s%n", sendResult);
// 關閉生產者
producer.shutdown();
}
}
透過批次發送訊息,減少了RocketMQ客戶端與伺服端,也就是Broker之間的網路通訊次數,提高傳輸效率
不過在使用批次訊息的時候,需要註意以下三點:
每條訊息的Topic必須都得是一樣的
不支持延遲訊息和事務訊息
不論是普通訊息還是批次訊息,總大小預設不能超過4m
訊息壓縮
RocketMQ在發送訊息的時候,當發現訊息的大小超過4k的時候,就會對訊息進行壓縮
這是因為如果訊息過大,會對網路頻寬造成壓力
不過需要註意的是,如果是批次訊息的話,就不會進行壓縮,如下所示:
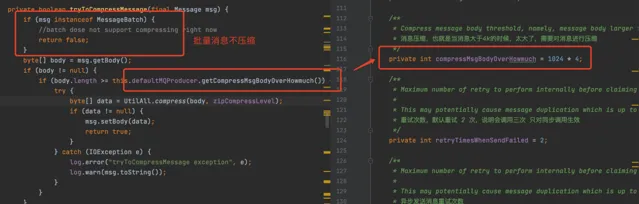
壓縮訊息除了能夠減少網路頻寬造成壓力之外,還能夠節省訊息儲存空間
RocketMQ在往磁盤存訊息的時候,並不會去解壓訊息,而是直接將壓縮後的訊息存到磁盤
消費者拉取到的訊息其實也是壓縮後的訊息
不過消費者在拿到訊息之後會對訊息進行解壓縮
當我們的業務系統拿到訊息的時候,其實就是解壓縮後的訊息

雖然壓縮訊息能夠減少頻寬壓力和磁盤儲存壓力
但是由於壓縮和解壓縮的過程都是在客戶端(生產者、消費者)完成的
所以就會導致客戶端消耗更多的CPU資源,對CPU造成一定的壓力
高效能網路通訊模型
當生產者處理好訊息之後,就會將訊息透過網路通訊發送給伺服端
而RocketMQ之所以快的一個非常重要原因就是它擁有高效能網路通訊模型
RocketMQ網路通訊這塊底層是基於Netty來實作的
Netty是一款非常強大、非常優秀的網路應用程式框架,主要有以下幾個優點:
異步和事件驅動:Netty基於事件驅動的架構,使用了異步I/O操作,避免了阻塞式I/O呼叫的缺陷,能夠更有效地利用系統資源,提高並行處理能力。
高效能:Netty針對效能進行了最佳化,比如使用直接記憶體進行緩沖,減少垃圾回收的壓力和記憶體拷貝的開銷,提供了高吞吐量、低延遲的網路通訊能力。
可延伸性:Netty的設計允許使用者自訂各種Handler來處理協定編碼、協定解碼和業務邏輯等。並且,它的模組可插拔性設計使得使用者可以根據需要輕松地添加或更換元件。
簡化API:與Java原生NIO庫相比,Netty提供了更加簡潔易用的API,大大降低了網路編程的復雜度。
安全:Netty內建了對SSL/TLS協定的支持,使得構建安全通訊套用變得容易。
豐富的協定支持:Netty提供了HTTP、HTTP/2、WebSocket、Google Protocol Buffers等多種協定的編解碼支持,滿足不同網路套用需求。
...
就是因為Netty如此的強大,所以不僅僅RocketMQ是基於Netty實作網路通訊的
幾乎絕大多數只要涉及到網路通訊的Java類框架,底層都離不開Netty的身影
比如知名RPC框架Dubbo、Java gRPC實作、Redis的親兒子Redisson、分布式任務排程平台xxl-job等等
它們底層在實作網路通訊時,都是基於Netty框架
零拷貝技術
當訊息達到RocketMQ伺服端之後,為了能夠保證伺服端重新開機之後訊息也不遺失,此時就需要將訊息持久化到磁盤
由於涉及到訊息持久化操作,就涉及到磁盤檔的讀寫操作
RocketMQ為了保證磁盤檔的高效能讀寫,使用到了一個叫 零拷貝 的技術
1、傳統IO讀寫方式
說零拷貝之前,先說一下傳統的IO讀寫方式。
比如現在有一個需求, 將磁盤檔透過網路傳輸出去
那麽整個傳統的IO讀寫模型如下圖所示
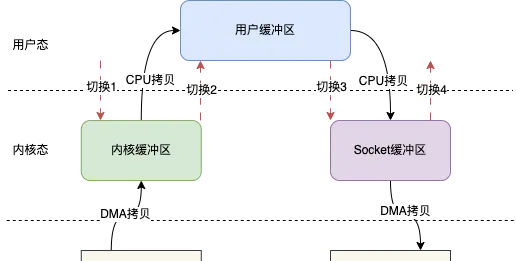
傳統的IO讀寫其實就是read + write的操作,整個過程會分為如下幾步
使用者呼叫read()方法,開始讀取數據,此時發生一次上下文從使用者態到內核態的切換,也就是圖示的切換1
將磁盤數據透過DMA拷貝到內核緩存區
將內核緩存區的數據拷貝到使用者緩沖區,這樣使用者,也就是我們寫的程式碼就能拿到檔的數據
read()方法返回,此時就會從內核態切換到使用者態,也就是圖示的切換2
當我們拿到數據之後,就可以呼叫write()方法,此時上下文會從使用者態切換到內核態,即圖示切換3
CPU將使用者緩沖區的數據拷貝到Socket緩沖區
將Socket緩沖區數據拷貝至網卡
write()方法返回,上下文重新從內核態切換到使用者態,即圖示切換4
整個過程發生了4次上下文切換和4次數據的拷貝,這在高並行場景下肯定會嚴重影響讀寫效能。
所以為了減少上下文切換次數和數據拷貝次數,就引入了零拷貝技術。
2、零拷貝
零拷貝技術是一個思想,指的是指電腦執行操作時,CPU不需要先將數據從某處記憶體復制到另一個特定區域。
實作零拷貝的有以下兩種方式:
mmap()
sendfile()
mmap()
mmap(memory map)是一種記憶體對映檔的方法,即將一個檔或者其它物件對映到行程的地址空間,實作檔磁盤地址和行程虛擬地址空間中一段虛擬地址的一一對映關系。
簡單地說就是 內核緩沖區和套用緩沖區 進行對映
使用者在操作套用緩沖區時就 好像 在操作內核緩沖區
比如你往套用緩沖區寫數據,就好像直接往內核緩沖區寫數據,這個過程不涉及到CPU拷貝
而傳統IO就需要將在寫完套用緩沖區之後需要將數據透過CPU拷貝到內核緩沖區
同樣地上述檔傳輸功能,如果使用mmap的話,由於我們可以直接操作內核緩沖區
此時我們就可以將內核緩沖區的數據直接CPU拷貝到Socket緩沖區
整個IO模型就會如下圖所示:
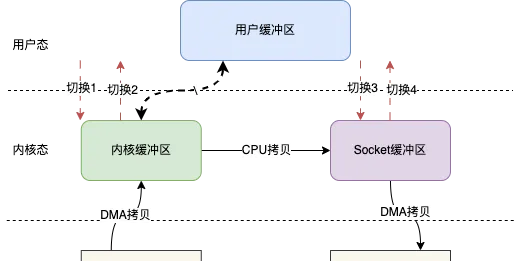
基於mmap IO讀寫其實就變成mmap + write的操作,也就是用mmap替代傳統IO中的read操作
當使用者發起mmap呼叫的時候會發生上下文切換1,進行記憶體對映,然後數據被拷貝到內核緩沖區,mmap返回,發生上下文切換2
隨後使用者呼叫write,發生上下文切換3,將內核緩沖區的數據拷貝到Socket緩沖區,write返回,發生上下文切換4。
上下文切換的次數仍然是4次,但是拷貝次數只有3次,少了一次CPU拷貝。
所以總的來說, 使用mmap就可以直接少一次CPU拷貝 。
說了這麽多,那麽在Java中,如何去實作mmap,也就是內核緩沖區和套用緩沖區對映呢?
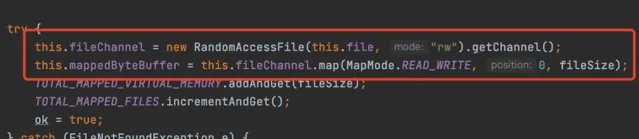
其實在Java NIO類別庫中就提供了相應的API,當然底層也還是呼叫Linux系統的mmap()實作的,程式碼如下所示
FileChannel fileChannel = new RandomAccessFile("test.txt", "rw").getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, fileChannel.size());
MappedByteBuffer,你可以認為操作這個物件就好像直接操作內核緩沖區
比如可以透過MappedByteBuffer讀寫磁盤檔,此時就好像直接從內核緩沖區讀寫數據
當然也可以直接透過MappedByteBuffer將檔的數據拷貝到Socket緩沖區,實作上述檔傳輸的模型
這裏我就不貼相應的程式碼了
RocketMQ在儲存檔時,就是透過mmap技術來實作高效的檔讀寫
雖然前面一直說mmap不涉及CPU拷貝,但在某些特定場景下,尤其是在寫操作或特定的系統最佳化策略下,還是可能涉及CPU拷貝。
sendfile()
sendfile()跟mmap()一樣,也會減少一次CPU拷貝,但是它同時也會減少兩次上下文切換。
sendfile()主要是用於檔傳輸,比如將檔傳輸到另一個檔,又或者是網路
當基於sendfile()時,一次檔傳輸的過程就如下圖所示:
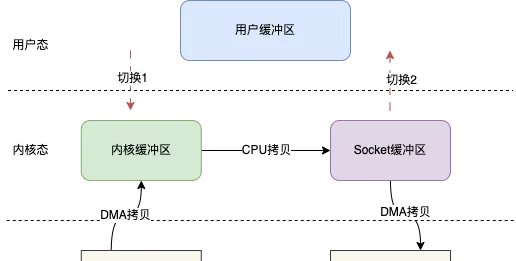
使用者發起sendfile()呼叫時會發生切換1,之後數據透過DMA拷貝到內核緩沖區,之後再將內核緩沖區的數據CPU拷貝到Socket緩沖區,最後拷貝到網卡,sendfile()返回,發生切換2。
同樣地,Java NIO類別庫中也提供了相應的API實作sendfile
當然底層還是作業系統的sendfile()
FileChannel channel = FileChannel.open(Paths.get("./test.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);
//呼叫transferTo方法向目標數據傳輸
channel.transferTo(position, len, target);
FileChannel的transferTo方法底層就是基於sendfile來的
在如上程式碼中,並沒有檔的讀寫操作,而是直接將檔的數據傳輸到target目標緩沖區
也就是說,sendfile傳輸檔時是無法知道檔的具體的數據的
但是mmap不一樣,mmap可以來直接修改內核緩沖區的數據
假設如果需要對檔的內容進行修改之後再傳輸,mmap可以滿足
小總結
在傳統IO中,如果想將使用者緩存區的數據放到內核緩沖區,需要經過CPU拷貝
而基於零拷貝技術可以減少CPU拷貝次數,常見的有兩種:
mmap()
sendfile()
mmap()是將使用者緩沖區和內核緩沖區共享,操作使用者緩沖區就好像直接操作內核緩沖區,讀寫數據時不需要CPU拷貝
Java中可以使用MappedByteBuffer這個API來達到操作內核緩沖區的效果
sendfile()主要是用於檔傳輸,可以透過sendfile()將一個檔內容傳輸到另一個檔中或者是網路中
sendfile()在整個過程中是無法對檔內容進行修改的,如果想修改之後再傳輸,可以透過mmap來修改內容之後再傳輸
上面出現的API都是Java NIO標準類別庫中的
如果你看的還是很迷糊,那直接記住一個結論
之所以基於零拷貝技術能夠高效的實作檔的讀寫操作,主要因為是減少了CPU拷貝次數和上下文切換次數
在RocketMQ中,底層是基於mmap()來實作檔的高效讀寫的
順序寫
RocketMQ在儲存訊息時,除了使用零拷貝技術來實作檔的高效讀寫之外
還使用順序寫的方式提高數據寫入的速度
RocketMQ會將訊息按照順序一條一條地寫入檔中
這種順序寫的方式由於減少了磁頭的移動和尋道時間,在大規模數據寫入的場景下,使得數據寫入的速度更快
高效的數據儲存結構
Topic和佇列的關系
在RocketMQ中,預設會為每個Topic在每個伺服端Broker例項上建立4個佇列
如果有兩個Broker,那麽預設就會有8個佇列
每個Broker上的佇列上的編號(queueId)都是從0開始
CommitLog
前面一直說,當訊息到達RocektMQ伺服端時,需要將訊息存到磁盤檔
RocketMQ給這個存訊息的檔起了一個高大上的名字: CommitLog
由於訊息會很多,所以為了防止檔過大,CommitLog在物理磁盤檔上被分為多個磁盤檔,每個檔預設的固定大小是1G
訊息在寫入到檔時,除了包含訊息本身的內容數據,也還會包含其它資訊,比如
訊息的Topic
訊息所在佇列的id,生產者發送訊息時會攜帶這個佇列id
訊息生產者的ip和埠
...
這些數據會和訊息本身按照一定的順序同時寫到CommitLog檔中

上圖中黃色排列順序和實際的存的內容並非實際情況,我只是舉個例子
ConsumeQueue
除了CommitLog檔之外,RocketMQ還會為每個佇列建立一個磁盤檔
RocketMQ給這個檔也起了一個高大上的名字: ConsumeQueue
當訊息被存到CommitLog之後,其實還會往這條訊息所在佇列的ConsumeQueue檔中插一條數據
每個佇列的ConsumeQueue也是由多個檔組成,每個檔預設是存30萬條數據
插入ConsumeQueue中的 每條數據 由20個字節組成,包含3部份資訊
訊息在CommitLog的起始位置(8個字節),也被稱為偏移量
訊息在CommitLog儲存的長度(4個字節)
訊息tag的hashCode(8個字節)

每條數據也有自己的編號(offset),預設從0開始,依次遞增
所以,透過ConsumeQueue中存的數據可以從CommitLog中找到對應的訊息
那麽這個ConsumeQueue有什麽作用呢?
其實透過名字也能猜到,這其實跟訊息消費有關
當消費者拉取訊息的時候,會告訴伺服端四個比較重要的資訊
自己需要拉取哪個Topic的訊息
從Topic中的哪個佇列(queueId)拉取
從佇列的哪個位置(offset)拉取訊息
拉取多少條訊息(預設32條)

伺服端接收到訊息之後,總共分為四步處理:
首先會找到對應的Topic
之後根據queueId找到對應的ConsumeQueue檔
然後根據offset位置,從ConsumeQueue中讀取跟拉取訊息條數一樣條數的數據
由於ConsumeQueue每條數據都是20個字節,所以根據offset的位置可以很快定位到應該從檔的哪個位置開始讀取數據
最後解析每條數據,根據偏移量和訊息的長度到CommitLog檔尋找真正的訊息內容
整個過程如下圖所示:
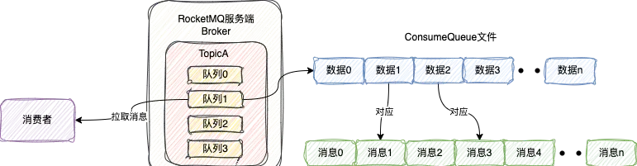
所以,從這可以看出,當消費者在拉取訊息時,ConsumeQueue其實就相當於是一個索引檔,方便快速尋找在CommitLog中的訊息
並且無論CommitLog存多少訊息,整個尋找訊息的時間復雜度都是O(1)
由於ConsumeQueue每條數據都是20個字節,所以如果需要找第n條數據,只需要從第 n * 20 個字節的位置開始讀20個字節的數據即可,這個過程是O(1)的
當從ConsumeQueue找到數據之後,解析出訊息在CommitLog儲存的起始位置和大小,之後就直接根據這兩個資訊就可以從CommitLog中找到這條訊息了,這個過程也是O(1)的
所以整個尋找訊息的過程就是O(1)的
所以從這就可以看出,ConsumeQueue和CommitLog相互配合,就能保證快速尋找到訊息,消費者從而就可以快速拉取訊息
異步處理
RocketMQ在處理訊息時,有很多異步操作,這裏我舉兩個例子:
異步刷盤
異步主從復制
異步刷盤
前面說到,檔的內容都是先寫到內核緩沖區,也可以說是PageCache
而寫到PageCache並不能保證訊息一定不遺失
因為如果伺服器掛了,這部份數據還是可能會遺失的
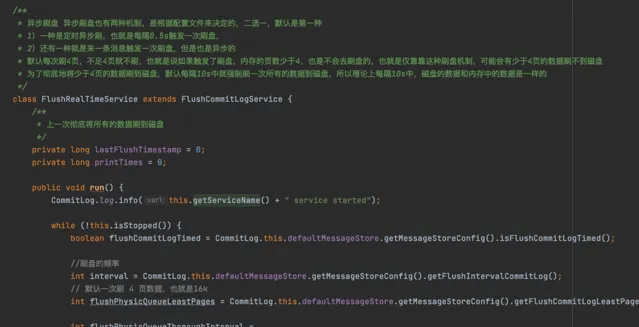
所以為了解決這個問題,RocketMQ會開啟一個後台執行緒
這個後台執行緒預設每隔0.5s會將訊息從PageCache刷到磁盤中
這樣就能保證訊息真正的持久化到磁盤中
異步主從復制
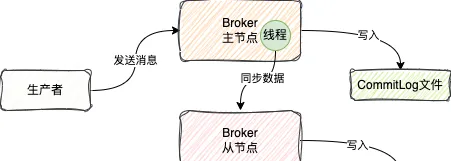
在RocketMQ中,支持主從復制的集群模式
這種模式下,寫訊息都是寫入到主節點,讀訊息一般也是從主節點讀,但是有些情況下可能會從從節點讀
從節點在啟動的時候會跟主節點建立網路連線
當主節點將訊息儲存的CommitLog檔之後,會透過後台一個異步執行緒,不停地將訊息發送給從節點
從節點接收到訊息之後,就直接將訊息存到CommitLog檔
小總結
就是因為有這些異步操作,大大提高了訊息儲存的效率
不過值得註意的,盡管異步可以提高效率,但是也增加了不確定性,比如丟訊息等等
當然RocketMQ也支持同步等待訊息刷盤和主從復制成功,但這肯定會導致效能降低
所以在計畫中可以根據自己的業務需要選擇對應的刷盤和主從復制的策略
批次處理
除了異步之外,RocketMQ還大量使用了批次處理機制
比如前面說過,消費者拉取訊息的時候,可以指定拉取拉取訊息的條數,批次拉取訊息
這種批次拉取機制可以減少消費者跟RocketMQ伺服端的網路通訊次數,提高效率
除了批次拉取訊息之外,RocketMQ在送出消費進度的時候也使用了批次處理機制
所謂的送出消費進度就是指
當消費者在成功消費訊息之後,需要將所消費訊息的offset(ConsumeQueue中的offset)送出給RocketMQ伺服端
告訴RocketMQ,這個Queue的訊息我已經消費到了這個位置了
這樣一旦消費者重新開機了或者其它啥的要從這個Queue重新開始拉取訊息的時候
此時他只需要問問RocketMQ伺服端上次這個Queue訊息消費到哪個位置了
之後消費者只需要從這個位置開始消費訊息就行了,這樣就解決了接著消費的問題
RocketMQ在送出消費進度的時候並不是說每消費一條訊息就送出一下這條訊息對應的offset
而是預設每隔5s定時去批次送出一次這5s鐘消費訊息的offset
鎖最佳化
由於RocketMQ內部采用了很多執行緒異步處理機制
這就一定會產生並行情況下的執行緒安全問題
在這種情況下,RocketMQ進行了多方面的鎖最佳化以提高效能和並行能力
就比如拿訊息儲存來說
為了保證訊息是按照順序一條一條地寫入到CommitLog檔中,就需要對這個寫訊息的操作進行加鎖
而RocketMQ預設使用ReentrantLock來加鎖,並不是synchronized

當然除了預設情況外,RocketMQ還提供了一種基於CAS加鎖的實作
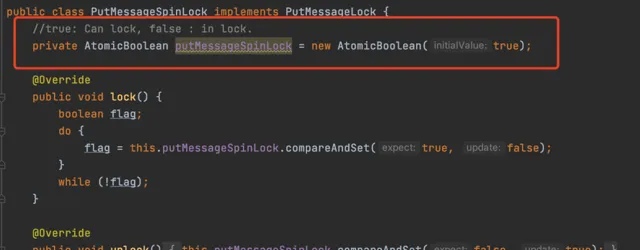
這種實作可以在寫訊息壓力較低的情況下使用
當然除了寫訊息之外,在一些其它的地方,RocketMQ也使用了基於CAS的原子操作來代替傳統的鎖機制
例如使用大量使用了AtomicInteger、AtomicLong等原子類別來實作並行控制,避免了顯式的鎖競爭,提高了效能
執行緒池隔離
RocketMQ在處理請求的時候,會為不同的請求分配不同的執行緒池進行處理
比如對於訊息儲存請求和拉取訊息請求來說
Broker會有專門為它們分配兩個不同的執行緒池去分別處理這些請求

這種讓不同的業務由不同的執行緒池去處理的方式,能夠有效地隔離不同業務邏輯之間的執行緒資源的影響
比如訊息儲存請求處理過慢並不會影響處理拉取訊息請求
所以RocketMQ透過執行緒隔離及時可以有效地提高系統的並行效能和穩定性
總結
到這我就從10個方面講完了RocketMQ為什麽這麽快背後的原因
不知道你讀完文章之後有什麽感受
其實實際上RocketMQ快的原因遠遠不止我上面說的這幾點
RocketMQ本身還做了很多其它的最佳化,比如拉取訊息的長輪詢機制、檔預熱機制等等
正是因為有各種各樣設計細節上的最佳化,才最終決定了RocketMQ出色的效能表現
好了,本文就講到這裏,如果覺得本文對你有點幫助,歡迎點贊、在看、收藏、轉發分享給其他需要的人
你的支持就是我更新的最大動力,感謝感謝!
讓我們下期再見,拜拜!
參考:
1、https://mp.weixin.qq.com/s/mOD9Z6pxSxBQuNx3YaUw3A
·················END·················
用官方一半價格的錢,用跟官方 ChatGPT4.0 一模一樣功能的工具。
國內直接使用ChatGPT4o:
谷歌瀏覽器直接使用:https://www.nezhasoft.cn
無需魔法,同時支持手機、電腦
個人獨享
ChatGPT4o mini永久免費
支持Copilot、DALLE AI繪畫、上傳檔等
長按辨識下方二維碼,備註ai,發給你
回復gpt,獲取ChatGPT4o直接使用地址
點選閱讀原文,國內直接使用ChatGpt4o











