0 1
論文簡介
論文題目:【A Method for Parsing and Vectorization of Semi-structured Data used in Retrieval Augmented Generation】
論文連結:https://arxiv.org/abs/2405.03989
程式碼: https://github.com/linancn/TianGong-AI-Unstructure/tree/main
這篇論文提出了一種新方法,用於解析和向量化半結構化數據,以增強大型語言模型(LLMs)中的檢索增強生成(RAG)功能。但是讀下來感覺並不是很「新」,基本是常見文本解析的流程,不過透過論文效果圖看起來不同檔解析效果還可以,並且公開了源碼,大家可以借鑒下。
0 2
論文方案
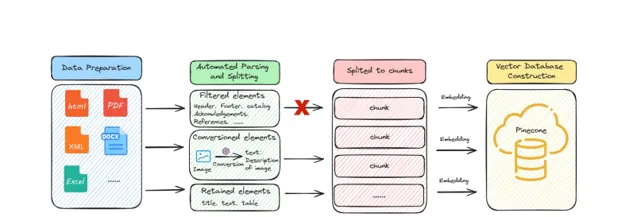
數據準備 :首先,將多種來源的數據(包括書籍、報告、學術文章和數據表)編譯成
.docx格式。.docx格式因其標準化、高品質的文本、易於編輯、廣泛的相容性和豐富的後設資料內容而被選為處理和提取結構化數據的首選格式。自動化解析和分割 :使用基於深度學習的物件檢測系統(如detectron2)將
.docx檔分割為多個元素,包括標題、文本、影像、表格、頁首和頁尾。然後,透過特定的數據清洗過程,進一步篩選和整理這些元素,以提高模型效率。塊化(Chunking) :利用「Unstructured Core Library」中的
chunk_by_title函式,將文件系統地分割成不同的子部份,將標題作為章節標記,同時保留文件的詳細結構。向量資料庫構建 :使用OpenAI的「text-embedding-ada-002」模型透過API生成與特定內容相對應的嵌入向量,並將這些向量儲存在Pinecone的向量資料庫中。這樣配置的資料庫能夠進行相似性搜尋,並且在數據儲存容量上有顯著優勢。
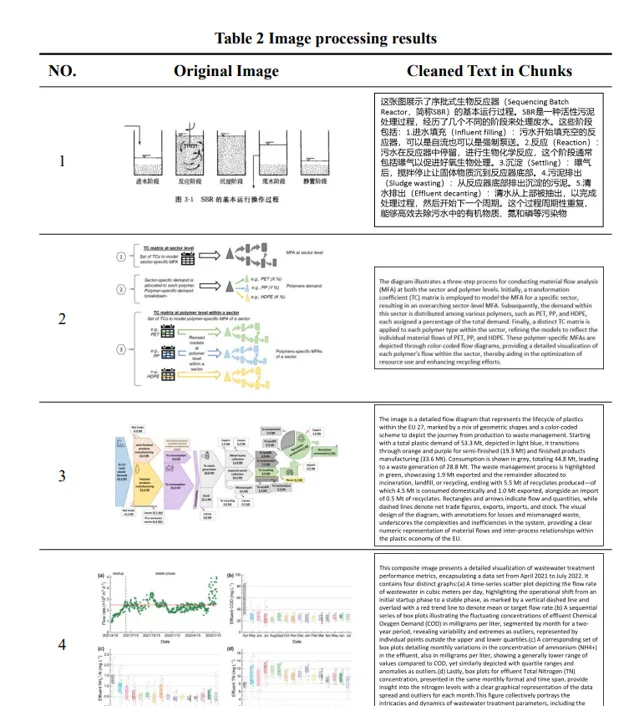
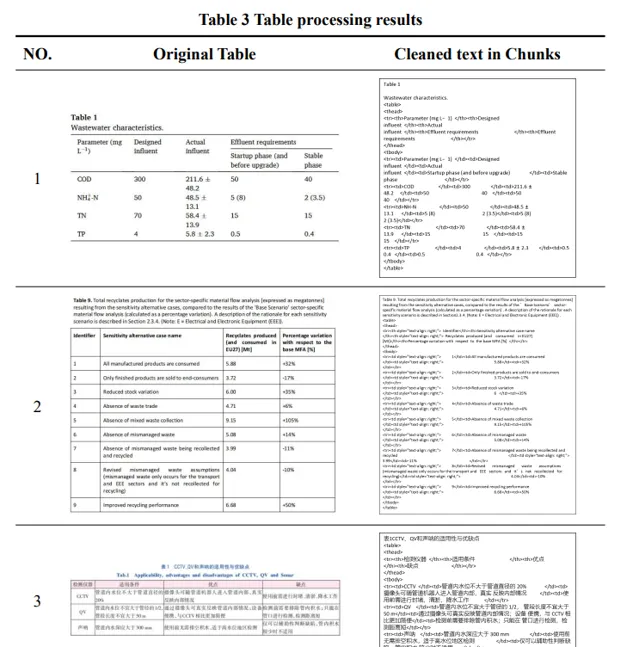
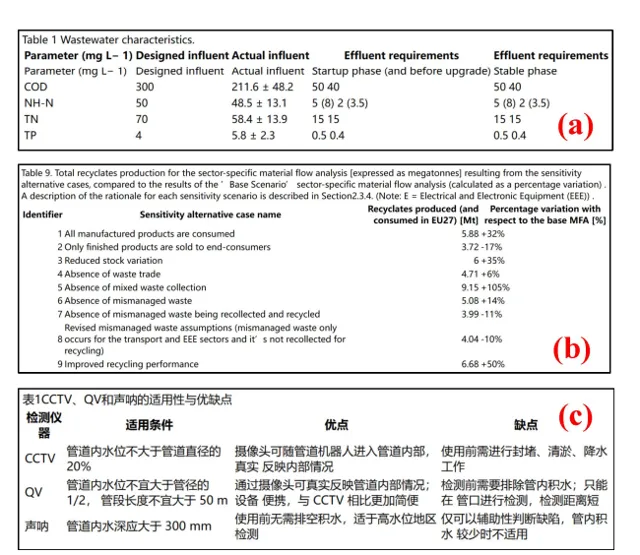
實驗和討論 :透過選取中英文的學術論文和書籍進行測試,展示了所使用方法和RAG技術的有效性。測試包括文本處理結果、影像處理結果和表格處理結果,以及在RAG環境下進行的零樣本問答(Zero-shot Question Answering)結果。
結果評估 :使用GPT 4.0處理選定的文件,並生成一系列問題,然後對這些問題進行評分,以客觀衡量向量知識庫在增強語言模型領域特定知識方面的有效性。
0 3
解析效果
論文

電子書

圖片
表格
html
0 4
問答效果




論文程式碼
對每個檔格式寫了不同的處理方式,可以借鑒下,但不是想象中的完全自動化或者智慧化











