前言
大家都知道 MySQL 的數據都是保存在磁盤的,那具體是保存在哪個檔呢?MySQL 儲存的行為是由儲存引擎實作的,MySQL 支持多種儲存引擎,不同的儲存引擎保存的檔自然也不同。InnoDB 是我們常用的儲存引擎,也是 MySQL 預設的儲存引擎。本文主要以 InnoDB 儲存引擎展開討論。
InnoDB簡介
InnoDB是一個將表中的數據儲存到磁盤上的儲存引擎。而真正處理數據的過程是發生在記憶體中的,所以需要把磁盤中的數據載入到記憶體中,如果是處理寫入或修改請求的話,還需要把記憶體中的內容重新整理到磁盤上。而我們知道讀寫磁盤的速度非常慢,和記憶體讀寫差了幾個數量級。所以當我們想從表中獲取某些記錄時,InnoDB儲存引擎需要一條一條的把記錄從磁盤上讀出來麽?想要了解這個問題,我們首先需要了解InnoDB的儲存結構是怎樣的。
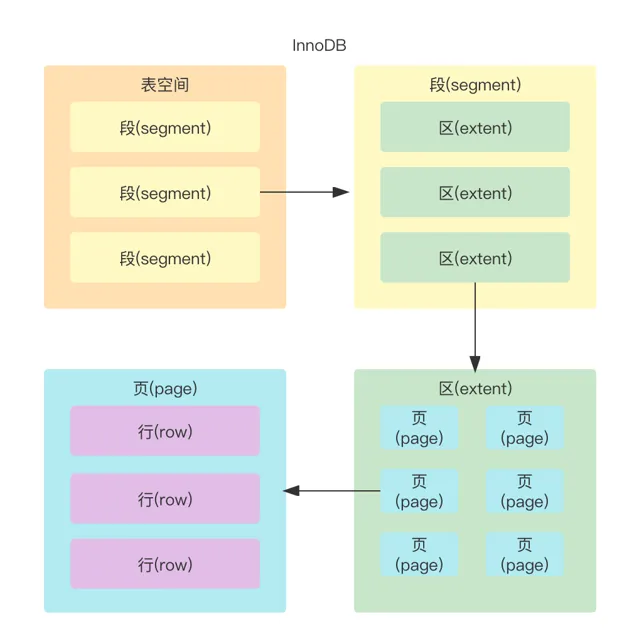
InnoDB采取的方式是:將數據劃分為若幹個頁,以頁作為磁盤和記憶體之間互動的基本單位innodb_page_size選項指定了MySQL例項的所有InnoDB表空間的頁面大小。這個值是在建立例項時設定的,之後保持不變。有效值為64KB,32KB,16KB(預設值 ),8kB和4kB。也就是在一般情況下,一次最少從磁盤中讀取16KB的內容到記憶體中,一次最少把記憶體中的16KB內容重新整理到磁盤中。
InnoDB行格式
我們平時是以記錄為單位來向表中插入數據的,這些記錄在磁盤上的存放方式也被稱為行格式或者記錄格式。一行記錄可以以不同的格式存在InnoDB中,行格式分別是compact、redundant、dynamic和compressed行格式。可以在建立或修改的語句中指定行格式:
-- 建立數據表時,顯示指定行格式CREATETABLE 表名 (列的資訊) ROW_FORMAT=行格式名稱;-- 建立數據表時,修改行格式ALTERTABLE 表名 ROW_FORMAT=行格式名稱;-- 檢視數據表的行格式showtablestatuslike'<數據表名>';
mysql5.0之前預設的行格式是redundant,mysql5.0之後的預設行格式為compact , 5.7之後的預設行格式為dynamic
compact格式

記錄的額外資訊
記錄的額外資訊:分別是變長欄位長度列表、NULL值列表和記錄頭資訊
1:變長欄位長度列表
mysql中支持一些變長數據型別(比如VARCHAR(M)、TEXT等),它們儲存數據占用的儲存空間不是固定的,而是會隨著儲存內容的變化而變化。在Compact行格式中,把所有變長欄位的真實數據占用的字節長度都存放在記錄的開頭部位,從而形成一個變長欄位長度列表,各變長欄位數據占用的字節數按照列的順序逆序存放
變長欄位長度列表中只儲存值為 非NULL 的列內容占用的長度,值為 NULL 的列的長度是不儲存的 。
並不是所有記錄都有這個 變長欄位長度列表 部份,比方說表中所有的列都不是變長的數據型別的話,這一部份就不需要有
2:NULL值列表
NULL值列表:Compact格式會把所有可以為NULL的列統一管理起來,存在一個NULL值列表,如果表中沒有允許為NULL的列,則NULL值列表也不復存在了。
為什麽要有NULL值列表?
表中的某些列可能儲存NULL值,如果把這些NULL值都放到記錄的真實數據中儲存會很浪費空間,所以Compact行格式把這些值為NULL的列統一管理起來,儲存到NULL值列表中,它的處理過程是這樣的:
首先統計表中允許儲存NULL的列有哪些。
根據列的實際值,用0或者1填充NULL值列表,1代表該列的值為空,0代表該列的值不為空。
如果表中沒有允許儲存 NULL 的列,則 NULL值列表 也不存在了。
3:記錄頭資訊
名稱 | 大小(單位:bit) | 描述 |
預留位1 | 1 | 未使用 |
預留位2 | 1 | 未使用 |
delete_mask | 1 | 標記改記錄是否被刪除 |
min_rec_mask | 1 | B+樹非葉子節點中最小記錄都會添加該標記 |
n_owned | 4 | 當前記錄擁有的記錄數 |
heap_no | 13 | 當前記錄在記錄堆的位置資訊 |
record_type | 3 | 記錄型別 0:普通記錄 1:B+樹非葉子節點記錄 2:最小記錄 3:最大記錄 |
next_record | 16 | 下一條記錄的相對位置 |
redundant 格式
與compact 格式相比, 沒有了 變長欄位列表以及 NULL值列表, 取而代之的是 記錄了所有真實數據的偏移地址表 ,偏移地址表 是倒序排放的, 但是計算偏移量卻還是正序開始的從row_id作為第一個, 第一個從0開始累加欄位對應的字節數。在記錄頭資訊中, 大部份欄位和compact 中的相同,但是對比compact多了。
n_field(記錄列的數量)、1byte_offs_flag(欄位長度列表每一列占用的字節數),少了record_type欄位。
因為redundant是mysql 5.0 以前就在使用的一種格式, 已經非常古老, 使用頻率非常的低,這裏就不過多表述。
dynamic 格式
在現在 mysql 5.7 的版本中,使用的格式就是 dynamic。
dynamic 和 compact 基本是相同的,只有在溢位頁的處理上面,有所不同。
在compact行格式中,對於占用儲存空間非常大的列,在記錄的真實數據處只會儲存該列的前768個字節的數據,把剩余的數據分散儲存在幾個其他的頁中,然後記錄的真實數據處用20個字節儲存指向這些頁的地址,從而可以找到剩余數據所在的頁。
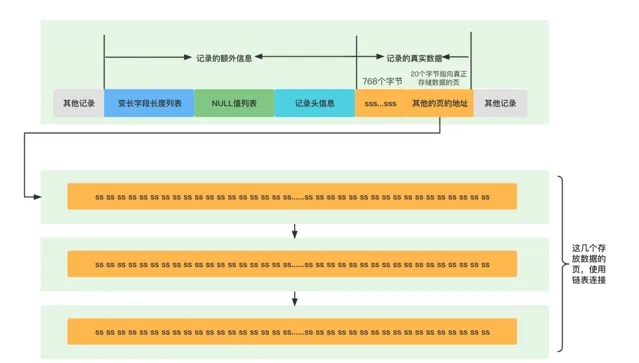
這種在本記錄的真實數據處只會儲存該列的前768個字節的數據和一個指向其他頁的地址,然後把剩下的數據存放到其他頁中的情況就叫做行溢位,儲存超出768字節的那些頁面也被稱為溢位頁(uncompresse blob page)。
dynamic中會直接在真實數據區記錄 20字節 的溢位頁地址, 而不再去額外記錄一部份的數據了。
行溢位臨界點
MySQL中規定一個頁中至少存放兩行記錄。簡單理解:因為B+樹的特性,如果不儲存至少2條記錄,則這個B+樹是沒有意義的,形不成一個有效的索引。
每個頁除了存放我們的記錄以外,也需要儲存一些額外的資訊,大概132個字節。
每個記錄需要的額外資訊是27字節。假設一個列中儲存的數據字節數為n,如要要保證該列不發生溢位,則需要滿足:132 + 2×(27 + n) < 16384 結果是n < 8099。也就是說如果一個列中儲存的數據小於8099個字節,那麽該列就不會成為溢位列。如果表中有多個列,那麽這個值更小。
compressed 格式
compressed 格式將會在Dynamic 的基礎上面進行壓縮處理特別是對溢位頁的壓縮處理,儲存在其中的行數據會以zlib的演算法進行壓縮,因此對於blob、text這類大長度型別的數據能夠進行非常有效的儲存。但compressed格式其實也是以時間換空間,效能並不友好,並不推薦在常見的業務中使用。
InnoDB數據頁結構
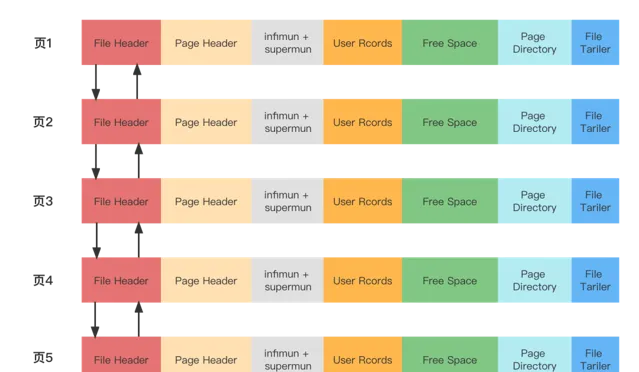
數據頁代表的這塊16KB大小的儲存空間可以被劃分為多個部份,不同部份有不同的功能
名稱 | 中文名 | 大小 | 描述 |
File Header | 檔頭部 | 38字節 | 頁通用資訊 |
Page Header | 頁面頭部 | 56字節 | 頁專有資訊 |
infimun + supermun | 最小記錄和最大記錄 | 26字節 | 虛擬的行記錄 |
User Rcords | 使用者記錄 | 不確定 | 實際儲存的行記錄內容 |
Free Space | 空閑空間 | 不確定 | 頁中未使用的空間 |
Page Directory | 頁面目錄 | 不確定 | 頁中一些記錄的相對位置 |
File Tariler | 檔尾部 | 8字節 | 校驗頁的完整性 |
每當我們插入一條記錄,都會從Free Space部份,也就是尚未使用的儲存空間中申請一個記錄大小的空間劃分到User Records部份,當Free Space部份的空間全部被User Records部份替代掉之後,也就意味著這個頁使用完了,如果還有新的記錄插入的話,就需要去申請新的頁了,這個過程的圖示如下:
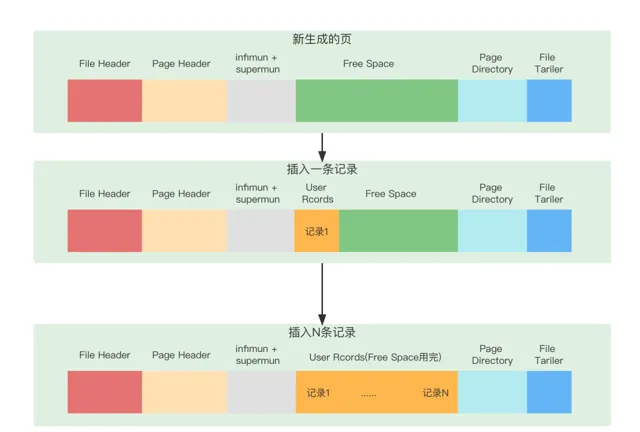
為了方便講述
先建立一個表:CREATETABLEtest( a1 INT, a2 INT, a3 VARCHAR(100), PRIMARY KEY (a1) ) CHARSET=ascii ROW_FORMAT=Compact;test表中插入幾條記錄:INSERTINTOtestVALUES(1, 10, 'aaa'); INSERTINTOtestVALUES(2, 20, 'bbb'); INSERTINTOtestVALUES(3, 30, 'ccc'); INSERTINTOtestVALUES(4, 40, 'ddd');
這些記錄,就如下圖所示,儲存在User Rcords裏

delete_mask這個內容標記著當前記錄是否被刪除。這些被刪除的記錄之所以不立即從磁盤上移除,是因為移除它們之後把其他的記錄在磁盤上重新排列需要效能消耗,所以只是打一個刪除標記而已。所有被刪除掉的記錄都會組成一個所謂的垃圾連結串列,在這個連結串列中的記錄占用的空間稱之為所謂的可重用空間,之後如果有新記錄插入到表中的話,可能把這些被刪除的記錄占用的儲存空間覆蓋掉。
min_rec_maskB+樹的每層非葉子節點中的最小記錄都會添加該標記,min_rec_mask值都是0,意味著它們都不是B+樹的非葉子節點中的最小記錄。
n_owned在頁目錄分組時使用,每個組的最後一條記錄(也就是組內最大的那條記錄)的頭資訊中的n_owned內容表示該記錄擁有多少條記錄,也就是該組內共有幾條記錄。
heap_no這個內容表示當前記錄在本頁中的位置,從圖中可以看出來,我們插入的4條記錄在本頁中的位置分別是:2、3、4、5。heap_no值為0和1的記錄,稱為偽記錄或者虛擬記錄。這兩個偽記錄一個代表最小記錄,一個代表最大記錄。
record_type這個內容表示當前記錄的型別,一共有4種型別的記錄,0表示普通記錄,1表示B+樹非葉節點記錄,2表示最小記錄,3表示最大記錄。
next_record它表示從當前記錄的真實數據到下一條記錄的真實數據的地址偏移量。比方說第一條記錄的next_record值為32,意味著從第一條記錄的真實數據的地址處向後找32個字節便是下一條記錄的真實數據。下一條記錄指得並不是按照我們插入順序的下一條記錄,而是按照主鍵值由小到大的順序的下一條記錄。而且規定Infimum記錄(也就是最小記錄) 的下一條記錄就是本頁中主鍵值最小的使用者記錄,而本頁中主鍵值最大的使用者記錄的下一條記錄就是 Supremum記錄(也就是最大記錄)。
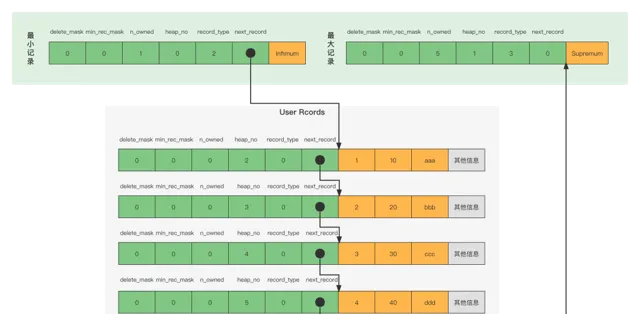
從圖中可以看出來,我們的記錄按照主鍵從小到大的順序形成了一個單連結串列。
Page Directory(頁目錄)
現在我們了解了記錄在頁中按照主鍵值由小到大順序串聯成一個單連結串列,單向連結串列的特點就是插入、刪除非常方便,但是檢索效率不高,最差的情況下需要遍歷連結串列上的所有節點才能完成檢索。因此在頁結構中專門設計了頁目錄這個模組,專門給記錄做一個目錄,透過二分尋找法的方式進行檢索,提升效率。
1:將所有正常的記錄(包括最大和最小記錄,不包括標記為已刪除的記錄)劃分為幾個組。
2:每個組的最後一條記錄(也就是組內最大的那條記錄)的頭資訊中的n_owned內容表示該記錄擁有多少條記錄,也就是該組內共有幾條記錄。
3:將每個組的最後一條記錄的地址偏移量單獨提取出來,用作尋找。
註意:這個頁目錄是為主鍵服務的。

需要註意的是:
第一:第一個小組,也就是最小記錄所在的分組只能有1個記錄;
第二:最後一個小組,就是最大記錄所在的分組,只能有1-8條記錄;
第三:剩下的分組中記錄的條數範圍只能在是 4-8 條之間;
分組是按照下邊的步驟進行:
初始情況下一個數據頁裏只有最小記錄和最大記錄兩條記錄,它們分屬於兩個分組。
之後每插入一條記錄,都會從頁目錄中找到主鍵值比本記錄的主鍵值大並且差值最小的槽,然後把該槽對應的記錄的n_owned值加1,表示本組內又添加了一條記錄,直到該組中的記錄數等於8個。
在一個組中的記錄數等於8個後再插入一條記錄時,會將組中的記錄拆分成兩個組,一個組中4條記錄,另一個5條記錄。這個過程會在頁目錄中新增一個槽來記錄這個新增分組中最大的那條記錄的偏移量。
我們再添加8條記錄看看效果:
INSERTINTOtestVALUES(5, 50, 'eee'); INSERTINTOtestVALUES(6, 60, 'fff'); INSERTINTOtestVALUES(7, 70, 'ggg'); INSERTINTOtestVALUES(8, 80, 'hhh'); INSERTINTOtestVALUES(9, 90, 'iii');INSERTINTOtestVALUES(10, 100, 'jjj');INSERTINTOtestVALUES(11, 110, 'kkk');INSERTINTOtestVALUES(12, 120, 'lll');
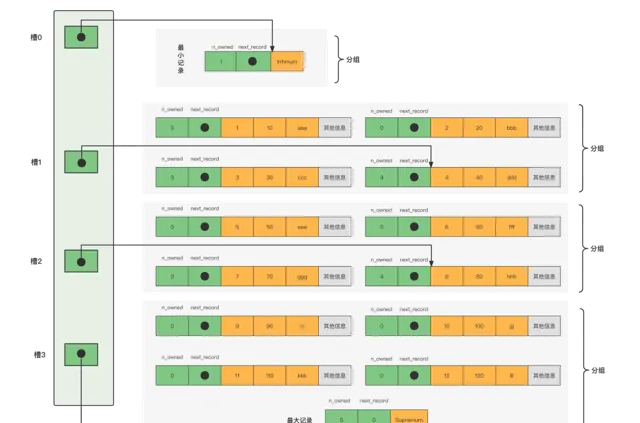
這裏為了便於理解,圖中只保留了使用者記錄頭資訊中的n_owned和next_record內容。
因為各個槽代表的記錄的主鍵值都是從小到大排序的,所以我們可以使用二分法來進行快速尋找。
所以在一個數據頁中尋找指定主鍵值的記錄的過程分為兩步:
1.透過二分法確定該記錄所在的槽,並找到該槽所在分組中主鍵值最大的那條記錄。
2.透過記錄的next_record內容遍歷該槽所在的組中的各個記錄。
比方說我們尋找主鍵值為x的記錄,計算中間槽的位置(min+max)/2 =mid,檢視mid槽對應的主鍵值y,若x<y,則min不變,max=mid,若x>y,則max不變,min=mid。依此類推。
舉例:我們想找主鍵值為6的記錄,過程是這樣的計算中間槽的位置:(0+3)/2=1,所以檢視槽1對應記錄的主鍵值為4,因為4 < 6,所以設定low=1,high保持不變。因為high - low的值為1,所以確定主鍵值為6的記錄在槽2對應的組中。我們可以很輕易的拿到槽1對應的記錄(主鍵值為4),該條記錄的下一條記錄就是槽2中主鍵值最小的記錄,該記錄的主鍵值為5。所以我們可以從這條主鍵值為5的記錄出發,遍歷槽2中的各條記錄找到主鍵為6 的數據。
註意:若查到數據在槽2的分組中,由於槽2是指向最後一個記錄,所以需要向上找一個槽位,定位到上一個槽位最後一行,然後再向下找。
File Header(檔頭部)
File Header針對各種型別的頁都通用,也就是說不同型別的頁都會以File Header作為第一個組成部份,它描述了一些針對各種頁都通用的一些資訊,比方說這個頁的編號是多少,它的上一個頁、下一個頁是誰等。
FIL_PAGE_OFFSET每一個頁都有一個單獨的頁號,就跟你的身份證號碼一樣,InnoDB透過頁號來可以唯一定位一個頁。
FIL_PAGE_PREV和FIL_PAGE_NEXTFIL_PAGE_PREV和FIL_PAGE_NEXT就分別代表本頁的上一個和下一個頁的頁號。這樣透過建立一個雙向連結串列把許許多多的頁就都串聯起來了。
B+樹索引
InnoDB 數據頁 的主要組成部份。各個數據頁可以組成一個雙向連結串列,而每個數據頁中的記錄會按照主鍵值從小到大的順序組成一個單向連結串列,每個數據頁都會為儲存在它裏邊兒的記錄生成一個 頁目錄 。再透過主鍵尋找某條記錄的時候可以在頁目錄中使用二分法快速定位到對應的槽。
在一個頁中的尋找:
以主鍵為搜尋條件這個尋找過程我們已經很熟悉了,可以在頁目錄中使用二分法快速定位到對應的槽,然後再遍歷該槽對應分組中的記錄即可快速找到指定的記錄。
以其他列作為搜尋條件對非主鍵列的尋找的過程可就不這麽幸運了,因為在數據頁中並沒有對非主鍵列建立所謂的頁目錄,所以我們無法透過二分法快速定位相應的槽。這種情況下只能從最小記錄開始依次遍歷單連結串列中的每條記錄,然後對比每條記錄是不是符合搜尋條件。
在很多頁中尋找:
1:定位到記錄所在的頁。
2:從所在的頁內中尋找相應的記錄。
在沒有索引的情況下,不論是根據主鍵列或者其他列的值進行尋找,由於我們並不能快速的定位到記錄所在的頁,所以只能從第一個頁沿著雙向連結串列一直往下找,在每一個頁中根據我們上面聊過的尋找方式去尋找指定的記錄。
索引
同樣的,我們以上面建的表test為例,清空插入的數據,此時test表為一張空數據的表,為了便於講述,我們可以簡單的把test表的行格式理解如下:
一個簡單的索引方案:我們為根據主鍵值快速定位一條記錄在頁中的位置而設立的頁目錄,目錄中記錄的數據頁需要滿足下一個數據頁中使用者記錄的主鍵值必須大於上一個頁中使用者記錄的主鍵值。
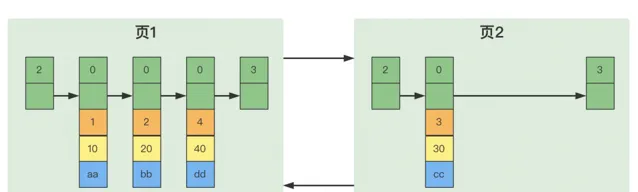
假設我們的每個數據頁最多能存放3條記錄(實際上一個數據頁非常大,可以存放下很多記錄),這時候我們向test表插入三條記錄,那麽數據頁就如圖所示:
test表中插入幾條記錄:INSERTINTOtestVALUES(1, 10, 'aa'); INSERTINTOtestVALUES(2, 20, 'bb'); INSERTINTOtestVALUES(4, 40, 'dd');

此時我們再來插入一條記錄:
INSERTINTOtestVALUES(3, 30, 'cc');
因為上面定義了,一個頁最多只能放3條記錄,所以我們不得不再分配一個新頁:
頁1中使用者記錄最大的主鍵值是4,而頁2中有一條記錄的主鍵值是3,因為4 > 3,所以這就不符合下一個數據頁中使用者記錄的主鍵值必須大於上一個頁中使用者記錄的主鍵值的要求,所以在插入主鍵值為3的記錄的時候需要伴隨著一次記錄移動,也就是把主鍵值為4的記錄移動到頁2中,然後再把主鍵值為3的記錄插入到頁1中。最後形成如圖所示。
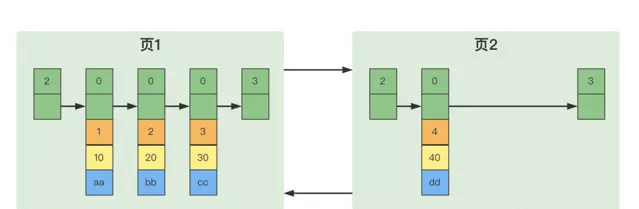
這個過程叫做頁分裂。
真實數據儲存中,數據頁的編號並不是連續的,當我們在test表中插入多條記錄後,可能是這樣的效果:

因為這些16KB的頁在物理儲存上可能並不挨著,所以如果想從這麽多頁中根據主鍵值快速定位某些記錄所在的頁,我們需要給它們做個目錄,每個頁對應一個目錄項,每個目錄項由頁中記錄的最小主鍵值和頁號組成。我們為上面幾個頁做目錄,則如圖:

比方說我們想找主鍵值為5的記錄,具體尋找過程分兩步:
1:先從目錄項中根據二分法快速確定出主鍵值為5的記錄在目錄2中(因為 4 < 5 < 7),它對應的數據頁是頁23。
2:再根據前邊說的在頁中尋找記錄的方式去頁23中定位具體的記錄。
這個目錄有一個別名,稱為 索引 。
InnoDB中的索引方案
在InnoDB中復用了之前儲存使用者記錄的數據頁來儲存目錄項,為了和使用者記錄做一下區分,我們把這些用來表示目錄項的記錄稱為目錄項記錄。
用record_type來區分普通的使用者記錄還是目錄項記錄。
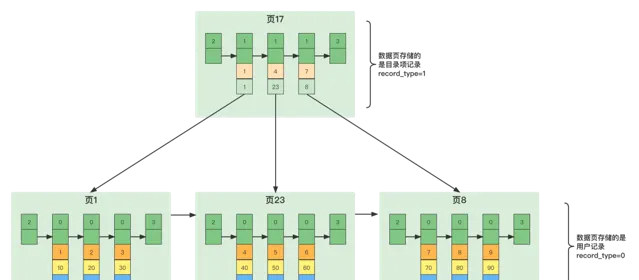
如果表中的數據太多,以至於一個數據頁不足以存放所有的目錄項記錄,會再多整一個儲存目錄項記錄的頁。所以如果此時我們再向上圖中插入一條主鍵值為10的使用者記錄的話:
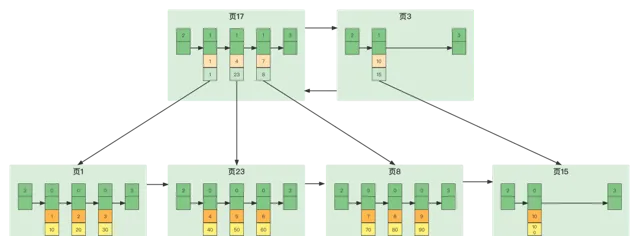
在查詢時我們需要定位儲存目錄項記錄的頁,但是這些頁在儲存空間中也可能不挨著,如果我們表中的數據非常多則會產生很多儲存目錄項記錄的頁,那我們怎麽根據主鍵值快速定位一個儲存目錄項記錄的頁呢?其實也簡單,為這些儲存目錄項記錄的頁再生成一個更高級的目錄,就像是一個多級目錄一樣,大目錄裏巢狀小目錄,小目錄裏才是實際的數據,所以現在各個頁的示意圖就是這樣子:
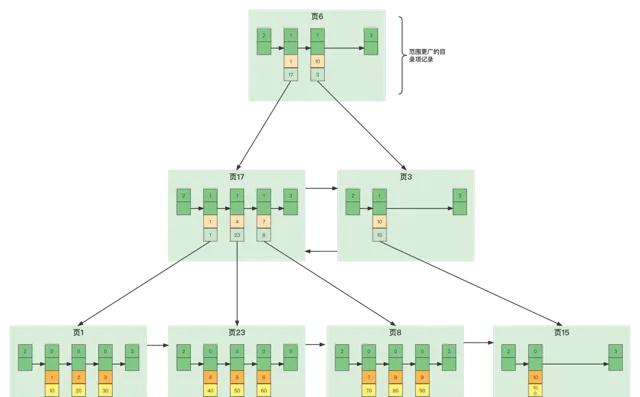
使用者記錄其實都存放在B+樹的最底層的節點上,這些節點也被稱為葉子節點或葉節點,其余用來存放目錄項的節點稱為非葉子節點或者內節點,其中B+樹最上邊的那個節點也稱為根節點。
聚簇索引
我們上邊介紹的B+樹本身就是一個目錄,或者說本身就是一個索引。它有兩個特點:
1:使用記錄主鍵值的大小進行記錄和頁的排序
2:B+樹的葉子節點儲存的是完整的使用者記錄。
我們把具有這兩種特性的B+樹稱為聚簇索引,所有完整的使用者記錄都存放在這個聚簇索引的葉子節點處。這種聚簇索引並不需要我們在MySQL語句中顯式的使用INDEX語句去建立,InnoDB儲存引擎會自動的為我們建立聚簇索引。另外有趣的一點是,在InnoDB儲存引擎中,聚簇索引就是數據的儲存方式(所有的使用者記錄都儲存在了葉子節點),也就是所謂的索引即數據,數據即索引。
二級索引

這個B+樹與上邊介紹的聚簇索引有幾處不同:
使用記錄a2列的大小進行記錄和頁的排序
頁內的記錄是按照a2列的大小順序排成一個單向連結串列。
各個存放使用者記錄的頁也是根據頁中記錄的a2列大小順序排成一個雙向連結串列。
存放目錄項記錄的頁分為不同的層次,在同一層次中的頁也是根據頁中目錄項記錄的a2列大小順序排成一個雙向連結串列。
B+樹的葉子節點儲存的並不是完整的使用者記錄,而只是a2列+主鍵這兩個列的值。
目錄項記錄中不再是主鍵+頁號的搭配,而變成了a2列+頁號的搭配。
索引的代價
1:空間上的代價每建立一個索引都要為它建立一棵B+樹,每一棵B+樹的每一個節點都是一個數據頁,一個頁預設會占用16KB的儲存空間。
2:時間上的代價每次對表中的數據進行增、刪、改操作時,都需要去修改各個B+樹索引。
B+樹每層節點都是按照索引列的值從小到大的順序排序而組成了雙向連結串列。不論是葉子節點中的記錄,還是內節點中的記錄(也就是不論是使用者記錄還是目錄項記錄)都是按照索引列的值從小到大的順序而形成了一個單向連結串列。而增、刪、改操作可能會對節點和記錄的排序造成破壞,所以儲存引擎需要額外的時間進行一些記錄移位,頁面分裂、頁面回收等操作來維護好節點和記錄的排序。
總結
透過對InnoDB儲存邏輯分析 ,我們可以清楚的了解到mysql中是怎樣對數據進行儲存的。並且對索引樹的結構進行分析,幫助我們在工作中更加合理的使用索引。
作者丨孔宇(梓軒)
來源丨公眾號:阿裏開發者(ID:ali_tech)
dbaplus社群歡迎廣大技術人員投稿,投稿信箱:[email protected]












