今天給大家介紹的這個計畫真的太強了!
很新穎,還沒見過一樣的開源計畫。
跳舞視訊加一張人物照片,就讓這個人像原視訊一樣跳舞的開源計畫之前給大家推薦過。
一張人物照片,用音訊給照片驅動變成講話視訊的計畫之前也推薦很多了。
今天給大家推薦的 One Shot, One Talk 就很牛了,功能上有點像是這兩類計畫的結合體。 上傳一段說話人視訊,再上傳一張人物照片,就可以把視訊裏的說話人替換掉。
這。。。可用場景是不是太多。。。
不過很刑的事大家可不要去做!!!
One Shot, One Talk現在論文已經發了,程式碼也馬上開源。
這麽強的計畫,咱們必須得搶先看一下!
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

計畫簡介
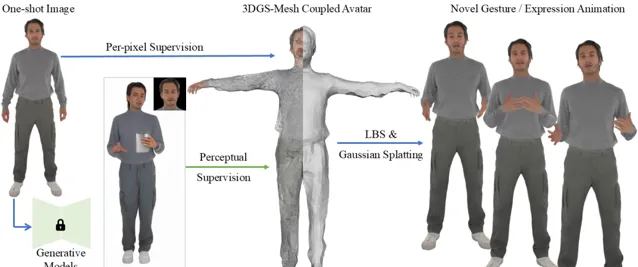
One Shot, One Talk 是一個創新的虛擬人物生成計畫,透過一張靜態影像生成生動的 3D 虛擬人物,並實作其面部與肢體的自然動畫。 該計畫結合了先進的 3D 高斯點雲和 SMPL-X 模型,采用了一種新穎的 3DGS-Mesh 結合表示,能夠在保證形態一致性的同時,提供出色的表達能力。 透過結合人類動作擴散模型和面部動畫技術,系統可以在僅有一張輸入圖片的情況下,生成高品質的虛擬人物動畫。透過最佳化偽標簽和加入感知指導,計畫在面部細節、肢體動態和高保真渲染方面實作了很好的效果。
DEMO
技術特點
1.3DGS-Mesh聯合表示
計畫采用了3DGS與SMPL-X相結合的創新方式。在該模型中,3DGS透過在網格的基礎上初始化並建模細致的面部和肢體特征,使得虛擬人物能夠表現出更加細膩的動態變化和面部表情細節。結合網格的幾何先驗資訊和高斯場的表達能力,避免了傳統3D網格對復雜細節的表現力不足,同時也不失真實感的渲染效果。
2. 無視訊輸入的單圖生成
與傳統的需要視訊輸入或多張影像的生成方法不同,本計畫實作了從單張圖片中生成動態虛擬人物。透過結合SMPL-X模型與3D高斯點雲,系統能夠捕捉到人物的面部和肢體表情,生成具有高保真度的虛擬動畫。這使得使用者可以透過提供一張圖片就能獲得一個生動、真實的虛擬人物,具有廣泛的套用潛力。
3. 高效的偽標簽生成與最佳化
本計畫采用了偽標簽生成技術,並透過基於擴散模型的生成網路(如MimicMotion)來生成多樣化的動作和表情幀。透過偽標簽的引導,結合SMPL-X參數的對映,能夠有效處理面部與肢體的動態變化。這種方法可以大大減少對大量訓練數據的依賴,使得單圖生成技術能夠在缺乏多樣數據的情況下仍然表現出色。
4. 高保真動畫與面部重建
本計畫不僅能夠生成全身的虛擬人物,還特別最佳化了面部表情與手部動作的重建。傳統的3D網格和高斯點雲方法通常難以處理這些細節,但本計畫透過引入面部重建最佳化模組,成功解決了復雜細節區域(如手部、面部等)的精準再現。這種細膩的面部與手部動畫生成能力,為虛擬主播、虛擬娛樂等套用提供了非常高的表現力。
5. 虛擬人物與偽標簽的感知一致性
在處理輸入影像與生成結果的匹配時,采用了LPIPS感知損失來確保生成的虛擬人物在感知層面上與原始輸入影像保持高度一致。該損失函式不僅幫助保留了輸入影像中的高階層特征,還能有效減少傳統像素對齊損失帶來的模糊和失真問題。透過深度學習感知損失,最終生成的虛擬人物在動態與靜態之間實作了平滑過渡,增強了使用者體驗。
6. 高效的最佳化策略
在訓練過程中,本計畫結合了Adam最佳化器和一系列的正則化方法,包括法線一致性損失、遮罩損失和拉普拉斯平滑損失,有效提高了生成模型的穩定性和魯棒性。此外,偽標簽回追蹤(Re-Tracking)技術的引入,有效解決了擴散模型帶來的誤對齊問題,從而減少了生成過程中的細節遺失和紋理錯誤,進一步提升了最終輸出的品質。
7. 端到端訓練與部署
計畫采用了端到端訓練流程,結合3D網格和高斯點雲的聯合表示,經過大量數據訓練後,能夠在沒有大量人工標註數據的情況下完成虛擬人物的生成與動畫演繹。最佳化後的模型能夠直接套用於多種平台,並實作高效的即時動畫生成,滿足不同領域如虛擬主播、遊戲角色、虛擬演藝等的需求。
計畫連結
https://ustc3dv.github.io/OneShotOneTalk/
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點
關註「 AGI光年 」公眾號
獲取每日最新資訊
關註「 向量光年 」公眾號
加速全行業向AI轉變











