計畫簡介
MOFA-Video是一款基於Pytorch的官方實作,專註於透過生成性運動場適應技術在凍結的影像到視訊擴散模型中實作可控制的影像動畫。該計畫的核心在於運用穩定視訊擴散模型,引入ControlNet靈感的MOFA介面卡,使得使用者能夠根據多種稀疏控制訊號將輸入影像動畫化。MOFA-Video具備在多個域之間調整動作的能力,使其成為在視訊生成和影像處理領域的一個創新工具。
掃碼加入AI交流群
獲得更多技術支持和交流
(請註明自己的職業)

DEMO
1. 軌跡控制 + 地標控制
2. 軌跡控制

3. 地標控制
技術
MOFA-Video是一種設計用來將不同領域中的動作適應到凍結的視訊擴散模型的方法。透過使用稀疏到密集(S2D)運動生成和基於流的運動適應,MOFA-Video能夠使用各種型別的控制訊號有效地對單個影像進行動畫處理,包括軌跡、關鍵點序列及其組合。
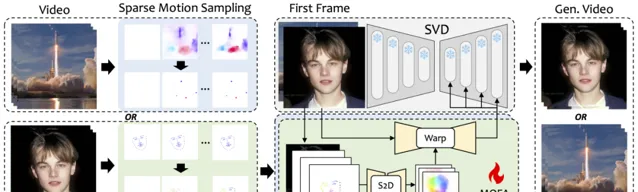
在訓練階段,透過稀疏運動采樣生成稀疏控制訊號,然後訓練不同的MOFA-介面卡透過預訓練的SVD生成視訊。在推理階段,不同的MOFA-介面卡可以組合在一起,共同控制凍結的SVD。
計畫連結
https://github.com/MyNiuuu/MOFA-Video
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點











