點選上方↑↑↑「OpenCV學堂」關註我
來源:公眾號 機器之心授權
美圖影像研究院(MT Lab)與中國科學院資訊工程研究所、北京航空航天大學、中山大學共同提出了 3D 場景編輯方法 ——CustomNeRF,同時支持文本描述和參考影像作為 3D 場景的編輯提示,該研究成果已被 CVPR 2024 接收。
自 2020 年神經放射線場 (Neural Radiance Field, NeRF) 提出以來,將隱式表達推上了一個新的高度。作為當前最前沿的技術之一,NeRF 快速泛化套用在電腦視覺、電腦圖形學、增強現實、虛擬現實等領域,並持續受到廣泛關註。
有賴於易於最佳化和連續表示的特點,NeRF 在 3D 場景重建中有著大量套用,也帶動了 3D 場景編輯領域的研究,如 3D 物件或場景的紋理重繪、風格化等。為了進一步提高 3D 場景編輯的靈活性,近期基於預訓練擴散模型進行 3D 場景編輯的方法也正在被大量探索,但由於 NeRF 的隱式表征以及 3D 場景的幾何特性,獲得符合文本提示的編輯結果並非易事。
為了讓文本驅動的 3D 場景編輯也能夠實作精準控制,美圖影像研究院(MT Lab)與中國科學院資訊工程研究所、北京航空航天大學、中山大學,共同提出了一種將文本描述和參考影像統一為編輯提示的 CustomNeRF 框架,可以透過微調預訓練的擴散模型將參考影像中包含的特定視覺主體 V∗嵌入到混合提示中,從而滿足一般化和客製化的 3D 場景編輯要求。該研究成果目前已被 CVPR 2024 收錄,程式碼已開源。

論文連結:https://arxiv.org/abs/2312.01663
程式碼連結:https://github.com/hrz2000/CustomNeRF

圖 1:CustomNeRF 在文本驅動(左)和影像驅動(右)的編輯效果
CustomNeRF 解決的兩大挑戰
目前,基於預訓練擴散模型進行 3D 場景編輯的主流方法主要分為兩類。
其一,是使用影像編輯模型叠代地更新數據集中的影像,但是受限於影像編輯模型的能力,會在部份編輯情形下失效。其二,則是利用分數蒸餾采樣(SDS)損失對場景進行編輯,但由於文本和場景之間的對齊問題,這類方法在真實場景中無法直接適配,會對非編輯區域造成不必要的修改,往往需要 mesh 或 voxel 等顯式中間表達。
此外,當前的這兩類方法主要集中在由文本驅動的 3D 場景編輯任務中,文本描述往往難以準確表達使用者的編輯需求,無法將影像中的具體概念客製化到 3D 場景中,只能對原始 3D 場景進行一般化編輯,因此難以獲得使用者預期中的編輯結果。
事實上,獲得預期編輯結果的關鍵在於精確辨識影像前景區域,這樣能夠在保持影像背景的同時促進幾何一致的影像前景編輯。
因此,為了實作僅對影像前景區域進行準確編輯,該論文提出了一種局部 - 全域叠代編輯(LGIE)的訓練方案,在影像前景區域編輯和全影像編輯之間交替進行。該方案能夠準確定位影像前景區域,並在保留影像背景的同時僅對影像前景進行操作。
此外,在由影像驅動的 3D 場景編輯中,存在因微調的擴散模型過擬合到參考影像視角,所造成的編輯結果幾何不一致問題。對此,該論文設計了一種類引導的正則化,在局部編輯階段僅使用類詞來表示參考影像的主體,並利用預訓練擴散模型中的一般類先驗來促進幾何一致的編輯。
CustomNeRF 的整體流程
如圖 2 所示,CustomNeRF 透過 3 個步驟,來實作在文本提示或參考影像的指導下精確編輯重建 3D 場景這一目標。
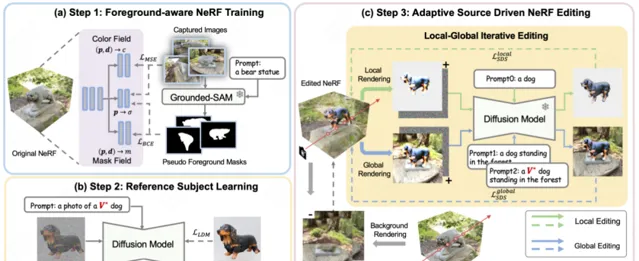
圖 2 CustomNeRF 的整體流程圖
首先,在重建原始的 3D 場景時,CustomNeRF 引入了額外的 mask field 來估計除常規顏色和密度之外的編輯機率。如圖 2(a) 所示,對於一組需要重建 3D 場景的影像,該論文先使用 Grouded SAM 從自然語言描述中提取影像編輯區域的掩碼,結合原始影像集訓練 foreground-aware NeRF。在 NeRF 重建後,編輯機率用於區分要編輯的影像區域(即影像前景區域)和不相關的影像區域(即影像背景區域),以便於在影像編輯訓練過程中進行解耦合的渲染。
其次,為了統一影像驅動和文本驅動的 3D 場景編輯任務,如圖 2(b)所示,該論文采用了 Custom Diffusion 的方法在影像驅動條件下針對參考圖進行微調,以學習特定主體的關鍵特征。經過訓練後,特殊詞 V∗可以作為常規的單詞標記用於表達參考影像中的主體概念,從而形成一個混合提示,例如 「a photo of a V∗ dog」。透過這種方式,CustomNeRF 能夠對自適應型別的數據(包括影像或文本)進行一致且有效的編輯。
在最終的編輯階段,由於 NeRF 的隱式表達,如果使用 SDS 損失對整個 3D 區域進行最佳化會導致背景區域發生顯著變化,而這些區域在編輯後理應與原始場景保持一致。如圖 2(c)所示,該論文提出了局部 - 全域叠代編輯(LGIE)方案進行解耦合的 SDS 訓練,使其能夠在編輯布局區域的同時保留背景內容。
具體而言,該論文將 NeRF 的編輯訓練過程進行了更精細的劃分。借助 foreground-aware NeRF,CustomNeRF 可以在訓練中靈活地控制 NeRF 的渲染過程,即在固定相機視角下,可以選擇渲染前景、背景、以及包含前景和背景的常規影像。在訓練過程中,透過叠代渲染前景和背景,並結合相應的前景或背景提示,可以利用 SDS 損失在不同層面編輯當前的 NeRF 場景。其中,局部的前景訓練使得在編輯過程中能夠只關註需編輯的區域,簡化復雜場景中編輯任務的難度;而全域的訓練將整個場景考慮在內,能夠保持前景和背景的協調性。為了進一步保持非編輯區域不發生改變,該論文還利用編輯訓練前的背景監督訓練過程中所新渲染的背景,來保持背景像素的一致性。
此外,影像驅動 3D 場景編輯中存在著加劇的幾何不一致問題。因為經過參考影像微調過的擴散模型,在推理過程中傾向於產生和參考影像視角相近的影像,造成編輯後 3D 場景的多個視角均是前檢視的幾何問題。為此,該論文設計了一種類引導的正則化策略,在全域提示中使用特殊描述符 V*,在局部提示中僅使用類詞,以利用預訓練擴散模型中包含的類先驗,使用更幾何一致的方式將新概念註入場景中。
實驗結果
如圖 3 和圖 4 展示了 CustomNeRF 與基線方法的 3D 場景重建結果對比,在參考影像和文本驅動的 3D 場景編輯任務中,CustomNeRF 均取得了不錯的編輯結果,不僅與編輯提示達成了良好的對齊,且背景區域和原場景保持一致。此外,表 1、表 2 展示了 CustomNeRF 在影像、文本驅動下與基線方法的量化比較,結果顯示在文本對齊指標、影像對齊指標和人類評估中,CustomNeRF 均超越了基線方法。

圖 3 影像驅動編輯下與基線方法的視覺化比較

圖 4 文本驅動編輯下與基線的視覺化比較
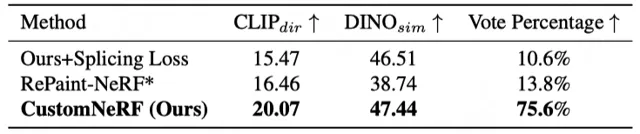
表 1 影像驅動編輯下與基線的定量比較

表 2 文本驅動編輯下與基線的定量比較
總結
本論文創新性地提出了 CustomNeRF 模型,同時支持文本描述或參考影像的編輯提示,並解決了兩個關鍵性挑戰 —— 精確的僅前景編輯以及在使用單檢視參考影像時多個檢視的一致性。該方案包括局部 - 全域叠代編輯(LGIE)訓練方案,使得編輯操作能夠在專註於前景的同時保持背景不變;以及類引導正則化,減輕影像驅動編輯中的檢視不一致,透過大量實驗,也驗證了 CustomNeRF 在各種真實場景中,能夠準確編輯由文本描述和參考影像提示的 3D 場景。











