轉載 | https://zhuanlan.zhihu.com/p/46216008
程式開發常見的ASCII、GB2312、GBK、GB18030、UTF8、ANSI、Latin1中文編碼到底有何不同?如果你在業務中也曾經被亂碼搞暈過,不妨一起探究一下。
字元編碼要做什麽事情?
在電腦眼裏讀到的所有文字都是由0和1組成的字串,為了能讓漢字正常顯示在螢幕上,我們需要做以下兩件事情:
給所有的漢字一個獨一無二的數位編號,做一個數位編號到漢字的mapping關系(即字元集)
把這個數位編號能用0和1表示出來
這裏需要說明的是,第2件事情並不是直接把數位編號用二進制表示出來那麽簡單,還要處理多個字連在一起的時候如何做分隔的問題。
例如如果我把」騰」編為1號(二進制00000001,占1byte),把「訊」編為5號(二進制00000101,占1byte),漢字這麽多,一定還有一個漢字被編為了133號(二進制00000001 00000101,占2bytes)。
那麽現在問題來了,當電腦讀到00000001 00000101這一串的時候,它應該顯示「騰訊」兩個字還是顯示那一個133號的文字?因此如何做分隔也是字元編碼需要考慮的事情。
第2件事情通常解決方案要麽就是規定好每個字長度(例如所有文字都是2bytes,不夠的前面用0補齊),要麽就是在用0和1表示的時候,不僅需要表示出數位編碼,還要暗示給電腦接下來多少個連續byte構成一個字,這個後面UTF8編碼中會提到。
我們通常所說的Unicode,其實只做了第1件事情,並且是給全世界所有語言的所有文字或字母一個獨一無二的數位編碼,這樣只要設計一種機制做第2件事情來表示Unicode,就可以顯示全球範圍內任何文字了。Unicode具體對所有語言的每個字母、文字的數位編號可以從其官方網站Unicode編碼表 查詢。該官網一大亮點是,中文編碼表的體量遠遠超過其他任何語言……
幾種常見中文編碼的關系如何?
幾種常見中文編碼之間存在相容性,一圖勝千言
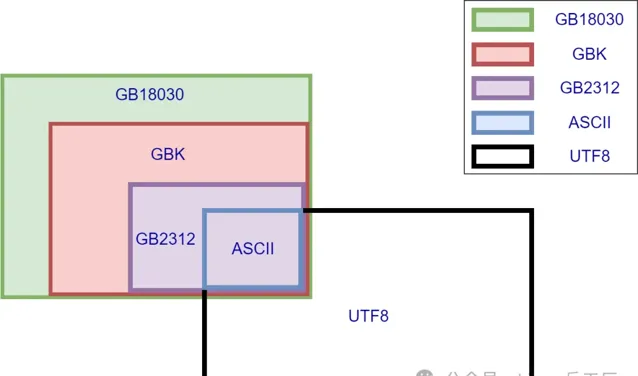
所謂相容性可以簡單理解為子集,同時存在也不沖突,不會出現上文所說的不知道是「騰訊」還是133號文字的情況。
圖中我們可以看出,ASCII被所有編碼相容,而最常見的UTF8與GBK之間除了ASCII部份之外沒有交集,這也是平時業務中最常見的導致亂碼場景,使用UTF8去讀取GBK編碼的文字,可能會看到各種亂碼。而GB系列的幾種編碼,GB18030相容GBK,GBK又相容GB2312,下文細講。
ASCII編碼
ASCII編碼每個字母或符號占1byte(8bits),並且8bits的最高位是0,因此ASCII能編碼的字母和符號只有128個。有一些編碼把8bits最高位為1的後128個值也編碼上,使得1byte可以表示256個值,但是這屬於擴充套件的ASCII,並非標準ASCII。通常所說的標準ASCII只有前128個值!
ASCII編碼幾乎被世界上所有編碼所相容(UTF16和UTF32是個例外),因此如果一個文本文件裏面的內容全都由ASCII裏面的字母或符號構成,那麽不管你如何展示該文件的內容,都不可能出現亂碼的情況。
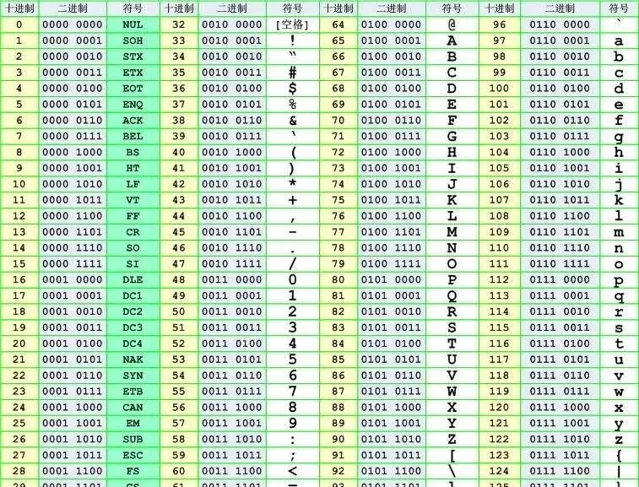
GB2312、GBK、GB18030編碼
GB全稱GuoBiao國標,GBK全稱GuoBiaoKuozhan國標擴充套件。GB18030編碼相容GBK,GBK相容GB2312,其實這三種編碼有著非常深厚的淵源,我們放在一起進行比較。
【GB2312】
最早一版的中文編碼,每個字占據2bytes。由於要和ASCII相容,那這2bytes最高位不可以為0了(否則和ASCII會有沖突)。在GB2312中收錄了6763個漢字以及682個特殊符號,已經囊括了生活中最常用的所有漢字。(GB2312編碼全表:連結)
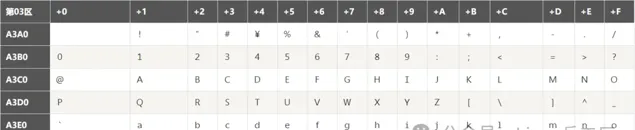
GB2312編碼表有個值得註意的點,這個表中也有一些數位和字母,與ASCII裏面的字母非常像。例如A3B2對應的是數位2(如下圖),但是ASCII裏面50(十進制)對應的也是數位2。他們的區別就是輸入法中所說的「半形」和「全形」。全形的數位2占兩個字節。
通常,我們在打字或編程中都使用半形,即ASCII來編寫數位或英文字母。特別是編程中,如果寫全形的數位或字母,編譯器很有可能不認識……
【GBK】
由於GB2312只有6763個漢字,我漢語博大精深,只有6763個字怎麽夠?於是GBK中在保證不和GB2312、ASCII沖突(即相容GB2312和ASCII)的前提下,也用每個字占據2bytes的方式又編碼了許多漢字。經過GBK編碼後,可以表示的漢字達到了20902個,另有984個漢語標點符號、部首等。值得註意的是這20902個漢字還包含了繁體字,但是該繁體字與台灣Big5編碼不相容,因為同一個繁體字很可能在GBK和Big5中數位編碼是不一樣的。(GBK編碼全表:連結)
【GB18030】
然而,GBK的兩萬多字也已經無法滿足我們的需求了,還有更多可能你自己從來沒見過的漢字需要編碼。
這時候顯然只用2bytes表示一個字已經不夠用了(2bytes最多只有65536種組合,然而為了和ASCII相容,最高位不能為0就已經直接淘汰了一半的組合,只剩下3萬多種組合無法滿足全部漢字要求)。因此GB18030多出來的漢字使用4bytes編碼。當然,為了相容GBK,這個四字節的前兩位顯然不能與GBK沖突(實操中發現後兩位也並沒有和GBK沖突)。
中國在2000年和2005年分別頒布的兩次GB18030編碼,其中2005年的是在2000年基礎上進一步補充。至此,GB18030編碼的中文檔已經有七萬多個漢字了,甚至包含了少數民族文字。有興趣的可以到國家標準委官網了解詳情,連結
GB2312,GBK,GB18030都是采取了固定長度的辦法來解決字元分隔(即前文所提的第2件事情)問題。GBK和GB2312比ASCII多出來的字都是2bytes,GB18030比GBK多出來的字都是4bytes。至於他們具體是如何做到相容的,可以參考下圖:
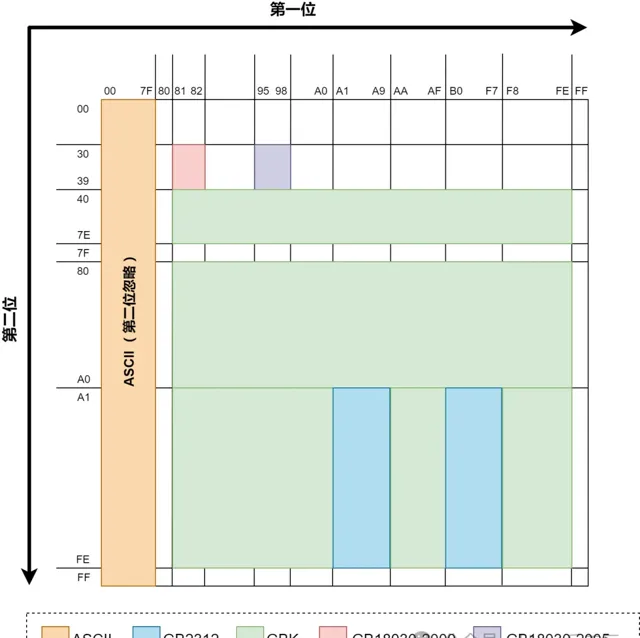
這圖中展示了前文所述的幾種編碼在編碼完成後,前2個byte的值域(用16進制表示)。每個byte可以表示00到FF(即0至255)。ASCII編碼由於是單字節,所以沒有第2位。因為GBK相容GB2312,所以理論上上圖中GB2312的領土面積也可以算在GBK的範圍內,GB18030也同理。
上圖只是展示出了比之前編碼「多」出來的面積。GB18030由於是4bytes編碼,上圖只是展示了前2bytes的值域,雖然面積最小,但是如果後2bytes也算上,GB18030新編碼的字數實際上遠遠多於GBK。ChatGPT中文網站:https://aigc.cxyquan.com
可以看出為了做到相容性,以上所有編碼的前2bytes做到了相互值域不沖突,這樣就可以允許幾種不同編碼中的文字同時出現在同一個文字檔案中。只要全都按照GB18030編碼的規則去解析並展示檔,就不會有亂碼出現。實際業務中GB18030很少提到,通常GBK見得比較多,這是因為如果你去看一下GB18030裏面所編碼的文字,你會發現自己一個字也不認識……
UTF8編碼(Unicode Transformation Format)
99%的前端寫網頁時都會加上,99%的後端工程師新建資料庫表時都會加上DEFAULT CHARSET=utf8(剩下的1%應該是忘了寫)。
之所以我們想讓UTF8一統天下,就是因為UTF8可以表示出世界上所有的文字!UTF8與前面說的GB系列編碼不相容,所以如果一個檔中即有UTF8編碼的文字,又有GB18030編碼的文字,那絕對會有亂碼。
Unicode賦予了全世界所有文字和符號一個獨一無二的數位編號,UTF8所做的事情就是把這個數位編號表示出來(即解決前文提到的第2件事情)。UTF8解決字元間分隔的方式是數二進制中最高位連續1的個數來決定這個字是幾字節編碼。0開頭的屬於單字節,和ASCII碼重合,做到了相容。
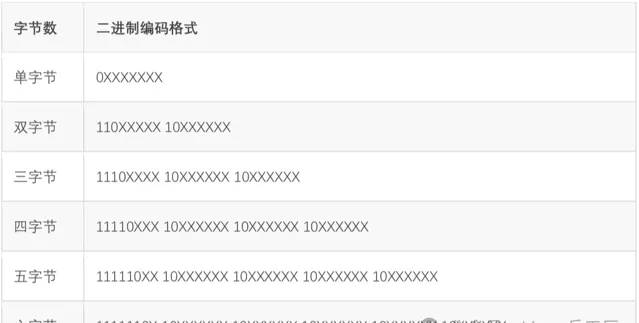
以三字節為例,開頭第一個字節的」1110」,有連續三個1,說明包括本字節在內,接下來三個字節一起構成了一個文字。凡是不屬於文字首字節的byte都以「10」開頭,上表中標註X的位置才是真正用來表示Unicode數值的。
這種巧妙設計,把Unicode的數值和每個字的字節數融合在一起,最壞情況是6個字節表示一個字,已經足夠表示世界上所有語言的所有文字了。不過從這種表示方式也可以很顯然地看出來,UTF8和GBK沒有任何關系,除了都相容ASCII以外。

舉例說明,中文「鵝」字,Unicode十進制值為40517(16進制為9E45,2進制為1001 1110 0100 0101)。這個2進制值長度為12位元,查詢上面表格發現,二字節不夠表示,四字節太長,三字節剛好,因此可以表示為 11101001 10111001 10000101,換算為16進制即E9B985,這就是「鵝」字的UTF8編碼,占3字節。另外,經查詢,「鵝」的GBK編碼為B6EC,和UTF8的值完全不相幹。
對於中文漢字來說,所有常用漢字的Unicode值都可以用3字節的UTF8表示出來,而GBK編碼的漢字基本是2字節(GB18030雖4字節但是日常沒人會寫那些字)。這也就導致了,如果把GBK編碼的中文文本另存為UTF8編碼,體積會大50%左右。這也是UTF8的一點小瑕疵,儲存同樣的漢字,體積比GBK要大50%。
不過在「可表示世界上所有文字」這一巨大優勢面前,UTF8的這點小瑕疵可以忽略了,所以日常開發中最常使用UTF8。
其他經常遇到的編碼
【ANSI編碼】
準確說,並不存在哪種具體的編碼方式叫做ANSI,它只是一個Windows作業系統上的別稱而已。在中文簡體Windows作業系統上,ANSI就是GBK;在泰語作業系統上,ANSI就是TIS-620(一種泰語編碼);在韓語作業系統上,ANSI就是EUC-KR(一種韓語編碼)。並且所謂的ANSI只存在於Windows作業系統上。
【Latin1編碼(又名ISO-8859-1編碼)】
相信99%的人第一次聽到Latin1都是在使用Mysql資料庫的時候接觸到的。Latin1是Mysql資料庫表的預設編碼方式。Latin1也是單字節編碼方式,也就是說最多只能表示256個字母或符號,並且前128個和ASCII完全吻合。
Latin1在ASCII基礎上又充分利用了後面那128個值,賦予他們一些泰語、希臘語等字母或符號,將1個字節的256個值全部占滿了。因為計畫中用不到,我對這種編碼的細節沒興趣了解,唯一感興趣的是為什麽Mysql選它做預設編碼(為什麽預設編碼不是UTF8)?以及如果忘了設定Mysql表的編碼方式時,用Latin1儲存中文會不會出問題?
為什麽預設編碼是Latin1而不是UTF8?原因之一是Mysql最開始是某瑞典公司搞的計畫,故預設collate都是latin1_swedish_ci。swedish可以理解為其私心,不過latin1不管是否出於私心目的,單字節編碼作為預設值肯定是比多字節做預設值更不容易在插入數據時報錯。
既然Latin1為單字節編碼,並且將1個字節的所有256個值全部占滿,因此理論上把任何編碼的值塞到Latin1欄位都是可以存的(無非就是顯示亂碼而已)。
假設預設為UTF8這一多字節編碼,在使用者誤把一個不使用UTF8編碼的字串存進去時,很有可能因為該字串不符合UTF8的編碼要求導致Mysql根本沒法處理。這也是單字節編碼的一大好處:顯示可以亂碼,但是裏面的數據值永遠正確。
用Latin1儲存中文有沒有問題?答案是沒有問題,但是並不建議。例如你把UTF8編碼的「訊」字(UTF8編碼為0xE8AEAF,占三個字節)存入了Latin1編碼的Mysql表,那麽在Mysql眼裏,你存入的並不是一個「訊」字,而是三個Latin1的字母(0xE8,0xAE,0xAF)。本質上,你存的數據值依然是0xE8AEAF,這種「欺騙」Mysql的行為並沒有導致數據遺失,只不過你需要註意讀取出來該值的時候,自己要以UTF8編碼的方式顯示出來,要不然就是亂碼。
因此,用Latin1存任何文字技術上都可以,但是經常會導致數據顯示亂碼。通常的解決方案,就是讓UTF8一統天下,建表的時候就聲明charset為utf8。
<END>
點這裏👇關註我,記得標星呀~
感謝你的分享,點贊,在看三連











