❝
目前大語言模型十分火爆,相信不少開發者都想上手體驗一番,但是對於我們這種技術有限的開發者,很難理清模型的推理過程以及輸出輸出處理,使得我們望塵莫及。那麽現在隨著OpenVINO™ 2024.2工具包的釋出,他帶來了最新的大語言模型部署工具OpenVINO.GenAI ,該工具包封裝了目前一些常用的大語言模型部署流程,能夠讓我們對大語言模型剛入門的開發者也能夠在自己電腦上跑起來。
本視訊中,我們將結合常見的大語言模型Qwen1.5-7B-Chat、Qwen1.5-7B-Chat-GPTQ-Int4,在本地電腦CPU上演示使用OpenVINO.GenAI 的執行效果。
1. 前言
英特爾發行版 OpenVINO™ 工具套件基於 oneAPI 而開發,可以加快高效能電腦視覺和深度學習視覺套用開發速度工具套件,適用於從邊緣到雲的各種英特爾平台上,幫助使用者更快地將更準確的真實世界結果部署到生產系統中。透過簡化的開發工作流程,OpenVINO™ 可賦能開發者在現實世界中部署高效能應用程式和演算法。
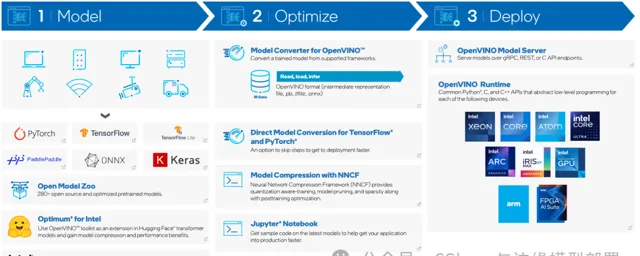
2024年6月17日,英特爾釋出了開源 OpenVINO™ 2024.2工具包:更多的 Gen AI 覆蓋範圍和框架整合,以最大限度地減少程式碼更改,並針對 CPU、內建 GPU 和獨立 GPU 的 Llama 3 最佳化,可提高效能和提高記憶體使用效率。同時支持更多大型語言模型 (LLM)模型壓縮技術,其中NNCF 中添加了用於 4 位權重壓縮的 GPTQ 方法,以提高推理效率並提高壓縮 LLM 的效能,同時提高了 LLM 效能,並降低了內建 GPU 和獨立 GPU 的延遲。
其中非常引人註目的是,在該版本中推出了 OpenVINO.GenAI 軟體包和 LLM特定 API。目前生成式 AI 正在被應用程式設計人員快速地使用著,這不僅體現在使用來自商業雲服務模型的傳統REST API形式上,而且還發生在客戶端和邊緣。所以目前最新的版本中引入了新的軟體包 openvino-genai,它基於OpenVINO™ 以及openvino_tokenizers,可以輕松實作執行 LLM。
因此,在本文中,我們將使用OpenVINO最新版提供的GenAI介面,演示如何快速構建一個簡單的Chat案例,此處我們將結合
TinyLlama-1.1B-Chat-v1.0
和
Qwen1.5-7B-Chat-GPTQ-Int4
這兩個大模型演示從模型下載到計畫實作的全部流程。
2. 計畫開發環境
下面簡單介紹一下計畫的開發環境,開發者可以根據自己的裝置情況進行配置:
系統平台:Windows 11
Intel Core i7-1165G7
開發平台:Visual Studio 2022
OpenVINO™ GenAI:2024.2.0
3. 模型下載與轉換
3.1 環境配置
模型下載與轉換需要使用的Python環境,因此此處我們采用Anaconda,然後用下面的命令建立並啟用名為optimum_intel的虛擬環境:
conda create -n optimum_intel python=3.11 #建立虛擬環境
conda activate optimum_intel #啟用虛擬環境
python -m pip install --upgrade pip #升級pip到最新版本
由於Optimum Intel程式碼叠代速度很快,所以選用從原始碼安裝的方式,安裝Optimum Intel和其依賴項OpenVINO與NNCF。
python -m pip install "optimum-intel[openvino,nncf]"@git+https://github.com/huggingface/optimum-intel.git
3.2 下載模型
目前一些大語言模型釋出在Hugging Face上,但由於在國內我們很難存取,因此此處模型下載我們使用國內的魔塔社群進行模型下載:
首先下載
Qwen1.5-7B-Chat-GPTQ-Int4
大模型,輸入以下命令即可進行下載:
git clone https://www.modelscope.cn/qwen/Qwen1.5-7B-Chat-GPTQ-Int4.git
接著下載
TinyLlama-1.1B-Chat-v1.0
大模型,輸入以下命令即可進行下載:
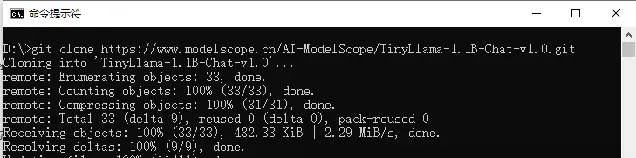
git clone https://www.modelscope.cn/AI-ModelScope/TinyLlama-1.1B-Chat-v1.0.git
輸入上面命令後,輸出如下面所示,則說明已經完成了模型下載:
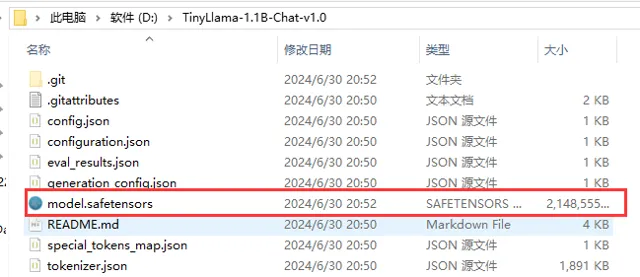
然後我們檢視一下下載後的資料夾,如下圖所示,檔中已經包含了下載的大模型以及一些配置檔:
3.3 模型轉換與量化
最後我們使用Optimum Intel工具,將模型轉為OpenVINO™ 的IR格式,同時為了提升模型推理速度,我們還將模型進行INT4量化,此處我們可以使用Optimum Intel工具一條指令便可完成。
首先進行
Qwen1.5-7B-Chat-GPTQ-Int4
模型的轉換與量化,在上文建立的環境下輸入以下命令即可:
optimum-cli export openvino --trust-remote-code --model D:\Qwen1.5-7B-Chat-GPTQ-Int4 --task text-generation-with-past --weight-format int4 --sym Qwen1.5-7B-Chat-GPTQ-Int4
❝
錯誤提醒:在轉換的時候如果出現
PackageNotFoundError: No package metadata was found for auto-gptq
的錯誤,請輸入以下指令安裝缺失的程式包:
pip install auto-gptq
然後進行
TinyLlama-1.1B-Chat-v1.0
模型的轉換與量化,在上文建立的環境下輸入以下命令即可:
optimum-cli export openvino --model D:\TinyLlama-1.1B-Chat-v1.0 --task text-generation-with-past --weight-format int4 --sym TinyLlama-1.1B-Chat-v1.0
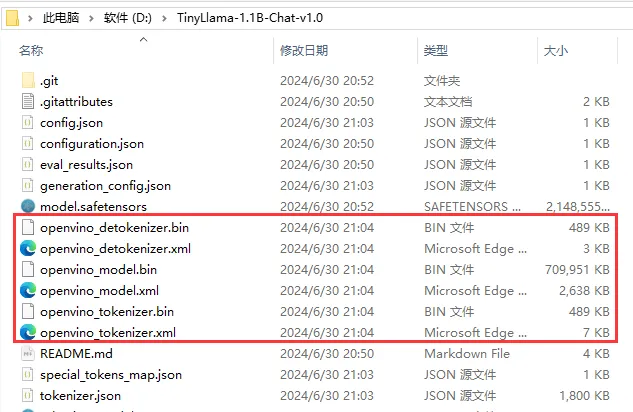
模型轉換完成後輸出如下所示:

轉換完成後,我們檢視一下模型路徑,可以看到模型路徑下多了三個轉換好的OpenVINO™ 的IR格式檔,如下圖所示:
到此為止我們已經完成了模型的準備與轉換環節。
4.OpenVINO™ GenAI 安裝與 C++計畫配置
OpenVINO™ GenAI C++計畫的安裝與配置與OpenVINO™基礎版本完全一致,如果你之前配置過OpenVINO™,那麽此處可以完全忽略。
4.1 OpenVINO™ GenAI 下載與安裝
首先存取下面連結,進入下載頁面:
https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/download.html
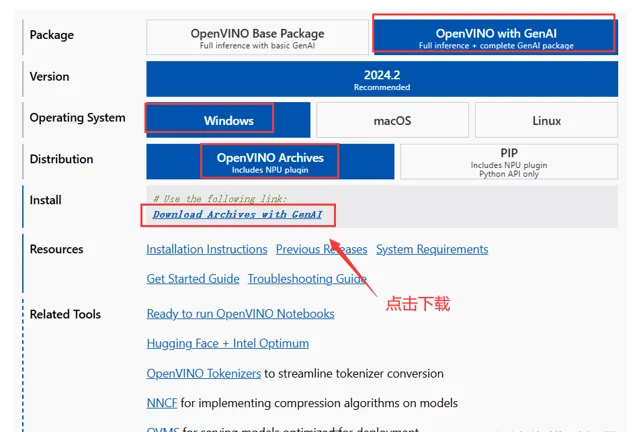
然後再下載頁面選擇相應的包以及環境,然後點選下載連結進行下載,如下圖所示:
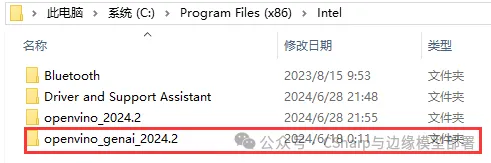
檔下載完成後,將其解壓到任意目錄,此處建議解壓到
C:\Program Files (x86)\Intel
目錄下,並將資料夾名修改為較為簡潔表述,如下圖所示:
最後在環境變量PATH中添加以下路徑:
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\bin\intel64\Debug
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\bin\intel64\Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\3rdparty\tbb\bin
至此為止,我們便完成了OpenVINO™ GenAI 下載與安裝。
4.2 OpenVINO™ GenAI C++計畫配置
C++計畫主要是需要配置包含目錄、庫目錄以及附加依賴項,分別在C++計畫中依次進行配置就可以:
包含目錄:
# Debug和Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include\openvino\genai
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\include\openvino
庫目錄:
# Debug
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\lib\intel64\Debug
# Release
C:\Program Files (x86)\Intel\openvino_genai_2024.2\runtime\lib\intel64\Release
附加依賴項
# Debug
openvinod.lib
openvino_genaid.lib
# Release
openvino.lib
openvino_genai.lib
5. 模型推理程式碼
下面是模型推理的程式碼,由於OpenVINO™ GenAI已經將模型的前後處理流程進行了封裝,因此在使用時程式碼十分簡潔,如下所示:
#include"openvino/genai/llm_pipeline.hpp"
#include<iostream>
intmain(int argc, char* argv[])
{
std::string model_path = "D:\\model\\TinyLlama-1.1B-Chat-v1.0";
std::string prompt;
ov::genai::LLMPipeline pipe(model_path, "CPU");
ov::genai::GenerationConfig config;
config.max_new_tokens = 1000;
std::function<bool(std::string)> streamer = [](std::string word) {
std::cout << word << std::flush;
returnfalse;
};
pipe.start_chat();
for (;;) {
std::cout << "question:\n";
std::getline(std::cin, prompt);
if (prompt == "Stop!")
break;
pipe.generate(prompt, config, streamer);
std::cout << "\n----------\n";
}
pipe.finish_chat();
}
6. 效果演示
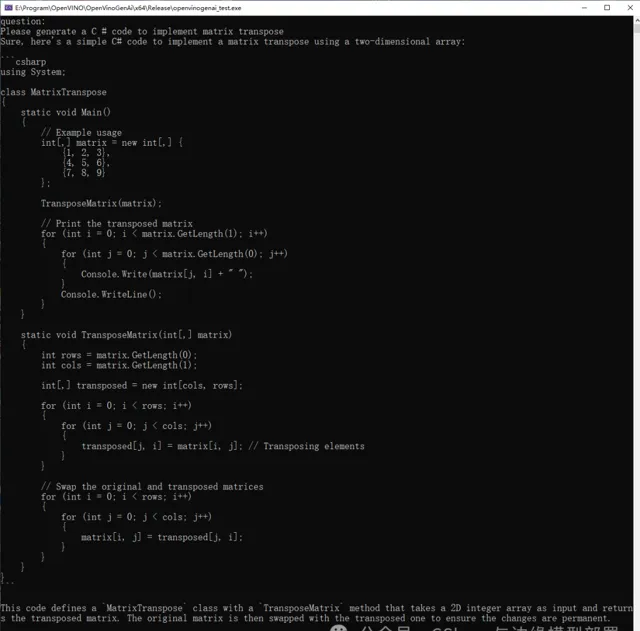
在執行程式碼後,我們想起進行提問「Please generate a C # code to implement matrix transpose」,主要是讓其生成一段C #程式碼,實作矩陣的轉置,輸出如下所示:
同時我們檢視一下執行過程中CPU以及記憶體情況,下圖是CPU以及記憶體占用情況:
| CPU占用 | 記憶體占用 |
|---|---|
|
|
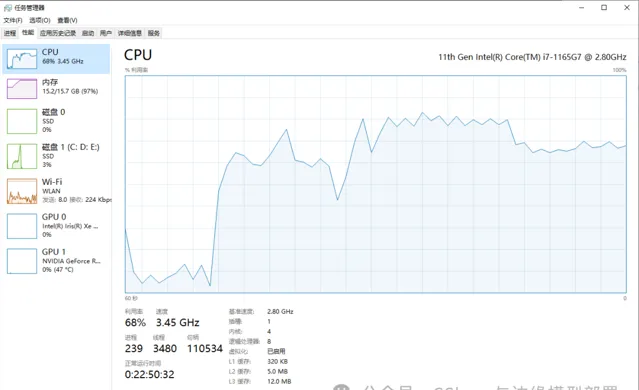
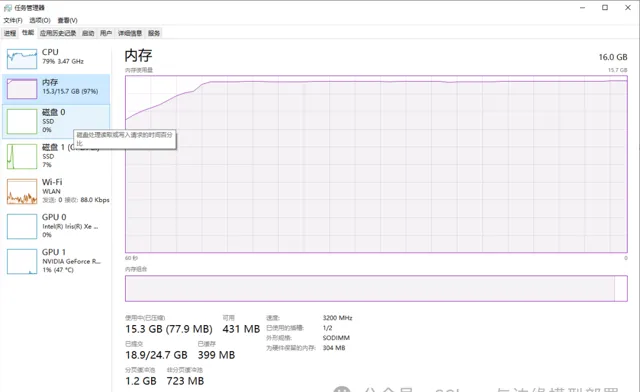
本機電腦使用的是一塊16GB的記憶體,可以看出在OpenVINO的加持下,依然可以很流暢的使用大語言模型進行推理。
7. 總結
在本文中,我們演示了常見的大語言模型Qwen1.5-7B-Chat、Qwen1.5-7B-Chat-GPTQ-Int4,在本地電腦CPU上演示使用OpenVINO.GenAI 的執行效果。最後如果各位開發者在使用中有任何問題,歡迎大家與我聯系。

猜你喜歡的文章
▶
▶
▶
▶
▶










