👉 目錄
1 使用 class 代替 ProtoBuf 協定
2 使用 Cache Friendly 的數據結構
3 使用 jemalloc/tcmalloc 代替普通的 malloc 方式
4 使用無鎖數據結構
5 對於特定的場景采用特定的處理方式
6 善用效能測試工具
7 總結
效能最佳化是降本增效路上必不可少的手段之一,在合適的時機采用合理的手段進行效能最佳化,一方面可以實作系統效能提升的目標,另一方面也可以借機對腐化的程式碼進行清理。在程式設計師的面試環節中,效能最佳化的問題也幾乎是必考題。
然而效能最佳化並非一錘子買賣,需要一直監控,一直最佳化。過早的最佳化、過度的最佳化,以及最佳化 ROI 都是程式設計師們在工作中需要評估的關鍵點。本文作者總結了日常工作中常見的效能最佳化問題,圍繞數據結構展開推薦了常見的幾種效能最佳化方案——既有提升 3 倍效能的最佳化技巧,也有扛住26 億/s API 呼叫量的健壯方案。文末還推薦了三款好用的效能測試工具,值得點贊收藏!
01
使用 class 代替 ProtoBuf 協定
在大量呼叫的 API 程式碼中盡量不要用 ProtoBuf 協定,最好使用 C++的 class 來代替。因為 ProtoBuf 采用的是 Arena 記憶體分配器 策略,有些場景會比 C++的 class 記憶體管理復雜,當有大量記憶體分配和釋放的時候會比 class 的效能差很多。而且 Protobuf 會不斷分配和回收 小記憶體物件 ,持續地分配和刪除小記憶體物件導致產生 記憶體碎片 ,降低程式的記憶體使用率,尤其是當協定中包含 string 型別的時候,效能差距可能有幾倍。對於包含了很多小物件的 Protobuf message, 析構過程 會導致堆上分配了許多物件,從而會變得復雜,導致解構函式執行速度變慢。
下面給出一個實際開發中使用 class 代替 Protobuf 的例子:
ProtoBuf 協定:
message Param {
optional string name = 1;
optional string value = 2;
}
message ParamHit {
enum Type {
Unknown = 0;
WhiteList = 1;
LaunchLayer = 2;
BaseAB = 3;
DefaultParam = 4;
}
optional Param param = 1;
optional uint64 group_id = 2;
optional uint64 expt_id = 3;
optional uint64 launch_layer_id = 4;
optional string hash_key_used = 5;
optional string hash_key_val_used = 6;
optional Type type = 7;
optional bool is_hit_mbox = 8;
}
覆寫的 class :
classParamHitInfo {
public:
classParam {
public:
Param() = default;
~Param() = default;
conststd::string & name()const{
return name_;
}
voidset_name(conststd::string &name){
name_ = name;
}
voidclear_name(){
name_.clear();
}
conststd::string & value()const{
return value_;
}
voidset_value(conststd::string &value){
value_ = value;
}
voidclear_value(){
value_.clear();
}
voidClear(){
clear_name();
clear_value();
}
private:
std::string name_, value_;
};
ParamHitInfo() {
expt_id_ = group_id_ = launch_layer_id_ = 0u;
is_hit_mbox_ = false;
type_ = ParamHit::Unknown;
}
~ParamHitInfo() = default;
voidClear(){
clear_group_id();
clear_expt_id();
clear_launch_layer_id();
clear_is_hit_mbox();
clear_hash_key_used();
clear_hash_key_val_used();
clear_type();
param_.Clear();
}
const ParamHit ToProtobuf()const{
ParamHit ans;
ans.set_expt_id(expt_id_);
ans.set_group_id(group_id_);
ans.set_launch_layer_id(launch_layer_id_);
ans.set_is_hit_mbox(is_hit_mbox_);
ans.set_hash_key_used(hash_key_used_);
ans.set_hash_key_val_used(hash_key_val_used_);
ans.set_type(type_);
ans.mutable_param()->set_name(param_.name());
ans.mutable_param()->set_value(param_.value());
return ans;
}
uint64_t group_id() const {
return group_id_;
}
voidset_group_id(constuint64_t group_id){
group_id_ = group_id;
}
voidclear_group_id(){
group_id_ = 0u;
}
uint64_t expt_id() const {
return expt_id_;
}
voidset_expt_id(constuint64_t expt_id){
expt_id_ = expt_id;
}
voidclear_expt_id(){
expt_id_ = 0u;
}
uint64_t launch_layer_id() const {
return launch_layer_id_;
}
voidset_launch_layer_id(constuint64_t launch_layer_id){
launch_layer_id_ = launch_layer_id;
}
voidclear_launch_layer_id(){
launch_layer_id_ = 0u;
}
boolis_hit_mbox()const{
return is_hit_mbox_;
}
voidset_is_hit_mbox(constbool is_hit_mbox){
is_hit_mbox_ = is_hit_mbox;
}
voidclear_is_hit_mbox(){
is_hit_mbox_ = false;
}
conststd::string & hash_key_used()const{
return hash_key_used_;
}
voidset_hash_key_used(conststd::string &hash_key_used){
hash_key_used_ = hash_key_used;
}
voidclear_hash_key_used(){
hash_key_used_.clear();
}
conststd::string & hash_key_val_used()const{
return hash_key_val_used_;
}
voidset_hash_key_val_used(conststd::string &hash_key_val_used){
hash_key_val_used_ = hash_key_val_used;
}
voidclear_hash_key_val_used(){
hash_key_val_used_.clear();
}
ParamHit_Type type()const{
return type_;
}
voidset_type(const ParamHit_Type type){
type_ = type;
}
voidclear_type(){
type_ = ParamHit::Unknown;
}
const Param & param()const{
return param_;
}
Param * mutable_param(){
return ¶m_;
}
std::stringShortDebugString()const{
std::string ans = "type: " + std::to_string(type_);
ans.append(", group_id: ").append(std::to_string(group_id_));
ans.append(", expt_id: ").append(std::to_string(expt_id_));
ans.append(", launch_layer_id: ").append(std::to_string(launch_layer_id_));
ans.append(", hash_key_used: ").append(hash_key_used_);
ans.append(", hash_key_val_used: ").append(hash_key_val_used_);
ans.append(", param_name: ").append(param_.name());
ans.append(", param_val: ").append(param_.value());
ans.append(", is_hit_mbox: ").append(std::to_string(is_hit_mbox_));
return ans;
}
intByteSize(){
int ans = 0;
ans += sizeof(uint64_t) * 3 + sizeof(bool) + sizeof(ParamHit_Type);
ans += hash_key_used_.size() + hash_key_val_used_.size() + param_.name().size() + param_.value().size();
return ans;
}
private:
ParamHit_Type type_;
uint64_t group_id_, expt_id_, launch_layer_id_;
std::string hash_key_used_, hash_key_val_used_;
bool is_hit_mbox_;
Param param_;
};
效能測試程式碼:
TEST(ParamHitDestructorPerf, test) {
vector<ParamHit> hits;
vector<ParamHitInfo> hit_infos;
constint hit_cnts = 1000;
vector<pair<string, string>> params;
for (int i=0; i<hit_cnts; ++i) {
string name = "name: " + to_string(i);
string val;
int n = 200;
val.resize(n);
for (int i=0; i<n; ++i) val[i] = (i%10 + 'a');
params.push_back(make_pair(name, val));
}
int uin_start = 12345645;
for (int i=0; i<hit_cnts; ++i) {
ParamHit hit;
hit.set_expt_id(i + uin_start);
hit.set_group_id(i + 1 + uin_start);
hit.set_type(ParamHit::BaseAB);
hit.set_is_hit_mbox(false);
hit.set_hash_key_used("uin_bytes");
hit.set_hash_key_val_used(BusinessUtil::UInt64ToLittleEndianBytes(i));
auto p = hit.mutable_param();
p->set_name(params[i].first);
p->set_value(params[i].second);
hits.emplace_back(std::move(hit));
}
for (int i=0; i<hit_cnts; ++i) {
ParamHitInfo hit;
hit.set_expt_id(i + uin_start);
hit.set_group_id(i + 1 + uin_start);
hit.set_type(ParamHit::BaseAB);
hit.set_is_hit_mbox(false);
hit.set_hash_key_used("uin_bytes");
hit.set_hash_key_val_used(BusinessUtil::UInt64ToLittleEndianBytes(i));
auto p = hit.mutable_param();
p->set_name(params[i].first);
p->set_value(params[i].second);
hit_infos.emplace_back(std::move(hit));
}
int kRuns = 1000;
chrono::high_resolution_clock::time_point t1 = chrono::high_resolution_clock::now();
{
for (int i=0; i<kRuns; ++i) {
for (auto &&hit: hits) {
auto tmp = hit;
}
}
}
chrono::high_resolution_clock::time_point t2 = chrono::high_resolution_clock::now();
auto time_span = chrono::duration_cast<chrono::milliseconds>(t2 - t1);
std::cerr << "ParamHit_PB Destructor kRuns: " << kRuns << " hit_cnts: " << hit_cnts << " cost: " << time_span.count() << "ms\n";
t1 = chrono::high_resolution_clock::now();
{
for (int i=0; i<kRuns; ++i) {
for (auto &&hit: hit_infos) {
auto tmp = hit;
}
}
}
t2 = chrono::high_resolution_clock::now();
time_span = chrono::duration_cast<chrono::milliseconds>(t2 - t1);
std::cerr << "ParamHitInfo_ class Destructor kRuns: " << kRuns << " hit_cnts: " << hit_cnts << " cost: " << time_span.count() << "ms\n";
}
效能對比結果:
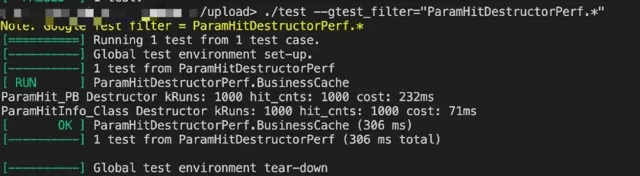
可以看到使用 C++的 class 相比於 ProtoBuf 可以提升3倍的效能。
02
使用 Cache Friendly 的數據結構
這裏想先丟擲一個問題:使用哈希表的尋找一定比使用陣列的尋找快嗎?
Q:理論上來說哈希表的尋找復雜度是 O(1),陣列的尋找復雜度是 O(n),那麽是不是可以得到一個結論就是說哈希表的尋找速度一定比陣列快呢?
A:其實是不一定的,由於陣列具有較高的緩存局部性,可提高 CPU 緩存的命中率,所以在有些場景下陣列的尋找效率要遠遠高於哈希表。
這裏給出一個常見操作耗時的數據(2020年):

下面也給出一個計畫中的使用 Cache Friendly 最佳化的例子:
最佳化前的數據結構:
classHitContext {
public:
inlinevoidupdate_hash_key(conststd::string &key, conststd::string &val){
hash_keys_[key] = val;
}
inlineconststd::string * search_hash_key(conststd::string &key)const{
auto it = hash_keys_.find(key);
return it != hash_keys_.end() ? &(it->second) : nullptr;
}
private:
Context context_;
std::unordered_map<std::string, std::string> hash_keys_;
};
最佳化後的數據結構:
classHitContext {
public:
inlinevoidupdate_hash_key(conststd::string &key, conststd::string &val){
if (Misc::IsSnsHashKey(key)) {
auto sns_id = Misc::FastAtoi(key.c_str()+Misc::SnsHashKeyPrefix().size());
sns_hash_keys_.emplace_back(sns_id, Misc::LittleEndianBytesToUInt32(val));
return;
}
hash_keys_[key] = val;
}
inlinevoidupdate_hash_key(conststd::string &key, constuint32_t val){
if (Misc::IsSnsHashKey(key)) {
auto sns_id = Misc::FastAtoi(key.c_str()+Misc::SnsHashKeyPrefix().size());
sns_hash_keys_.emplace_back(sns_id, val);
return;
}
hash_keys_[key] = Misc::UInt32ToLittleEndianBytes(val);
}
inlineconststd::stringsearch_hash_key(conststd::string &key, bool &find)const{
if (Misc::IsSnsHashKey(key)) {
auto sns_id = Misc::FastAtoi(key.c_str()+Misc::SnsHashKeyPrefix().size());
auto it = std::find_if(sns_hash_keys_.rbegin(), sns_hash_keys_.rend(), [sns_id](conststd::pair<uint32_t, uint32_t> &v) { return v.first == sns_id; });
find = it != sns_hash_keys_.rend();
return find ? Misc::UInt32ToLittleEndianBytes(it->second) : "";
}
auto it = hash_keys_.find(key);
find = it != hash_keys_.end();
return find ? it->second : "";
}
private:
Context context_;
std::unordered_map<std::string, std::string> hash_keys_;
std::vector<std::pair<uint32_t, uint32_t>> sns_hash_keys_;
};
效能測試程式碼:
TEST(HitContext, test) {
constint keycnt = 264;
std::vector<std::string> keys, vals;
for (int j = 0; j < keycnt; ++j) {
auto key = j+21324;
auto val = j+94512454;
keys.push_back("sns"+std::to_string(key));
vals.push_back(std::to_string(val));
}
constint kRuns = 1000;
std::unordered_map<uint32_t, uint64_t> hash_keys;
chrono::high_resolution_clock::time_point t1 = chrono::high_resolution_clock::now();
for (int i = 0; i < kRuns; ++i) {
HitContext1 ctx;
for (int j = 0; j < keycnt; ++j) {
ctx.update_hash_key(keys[j], vals[j]);
}
for (int j=0; j<keycnt; ++j) {
auto val = ctx.search_hash_key(keys[j]);
if (!val) assert(0);
}
}
chrono::high_resolution_clock::time_point t2 = chrono::high_resolution_clock::now();
auto time_span = chrono::duration_cast<chrono::microseconds>(t2 - t1);
std::cerr << "HashTable Hitcontext cost: " << time_span.count() << "us" << std::endl;
hash_keys.clear();
t1 = chrono::high_resolution_clock::now();
for (int i = 0; i < kRuns; ++i) {
HitContext2 ctx;
for (int j = 0; j < keycnt; ++j) {
ctx.update_hash_key(keys[j], vals[j]);
}
for (int j=0; j<keycnt; ++j) {
bool find = false;
auto val = ctx.search_hash_key(keys[j], find);
if (!find) assert(0);
}
}
t2 = chrono::high_resolution_clock::now();
time_span = chrono::duration_cast<chrono::microseconds>(t2 - t1);
std::cerr << "Vector HitContext cost: " << time_span.count() << "us" << std::endl;
}
效能對比結果:
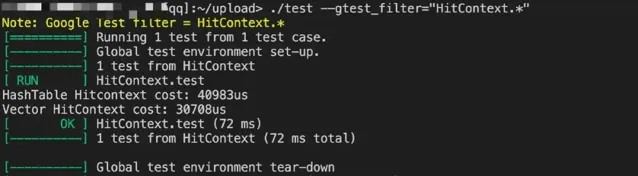
03
使用 jemalloc/tcmalloc 代替普通的 malloc 方式
由於程式碼中大量使用了 C++的 STL,所以會出現以下幾種缺點:
記憶體碎片: 頻繁分配和釋放不同大小的物件,可能導致記憶體碎片,降低記憶體的使用效率。 Cache 不友好: 而且 STL 的普通記憶體分配器分散了物件的記憶體地址,降低了數據的緩存命中率。 並行差: STL 的預設記憶體分配器可能使用全域鎖,相當於給加了一把大鎖,在多執行緒環境下效能表現很差。 |
目前在我們的程式碼中加 jemalloc 還是很方便的,就是在所編譯的 target 中加下依賴就好了,比如:
cc_library(
name = "mmexpt_dye_api",
srcs = [
"mmexpt_dye_api.cc",
],
hdrs = [
"mmexpt_dye_api.h",
],
includes = ['.'],
deps = [
"//mm3rd/jemalloc:jemalloc",
],
copts = [
"-O3",
"-std=c++11",
],
linkopts = [
],
visibility = ["//visibility:public"],
)
使用 jemalloc 與不使用 jemalloc 前後效能對比 (這裏的測試場景是在 loadbusiness 的時候,具體涉及到了一些業務程式碼)
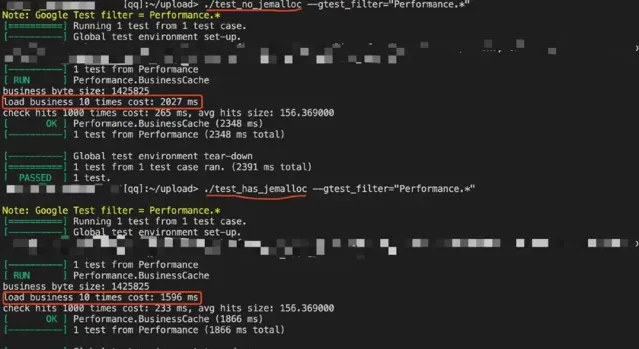
可以發現使用 jemalloc 可以提升20%多的效能,還是最佳化了很大的,很小的開發成本 (只需要加一個編譯依賴) 帶來不錯的收益。
04
使用無鎖數據結構
在過去計畫開發的時候使用過一種雙 buffer 的無鎖數據結構,之所以使用雙 buffer 是因為 API 有大約 26億/s 的呼叫量,這麽高的呼叫量對效能的要求是很高的。數據結構的定義:
structexpt_api_new_shm {
void *p_shm_data;
// header
volatileint *p_mem_switch; // 0:uninit. 1:mem 1 on server. 2:mem 2 on server
uint32_t *p_crc_sum;
// data
expt_new_context* p_new_context;
parameter2business* p_param2business;
char* p_business_cache;
HashTableWithCache hash_table; //多級哈希表
};
常用的幾個函式:
intInitExptNewShmData(expt_api_new_shm *pstShmData, void *pData){
int ptr_offset = EXPT_NEW_SHM_HEADER_SIZE;
pstShmData->p_shm_data = pData;
pstShmData->p_mem_switch = MAKE_PTR(volatileint *, pData, 0);
pstShmData->p_crc_sum = MAKE_PTR(uint32_t *, pData, 4);
pstShmData->p_new_context =
(expt_new_context *)((uint8_t *)pstShmData->p_shm_data + ptr_offset);
pstShmData->p_param2business =
(parameter2business *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_0);
pstShmData->p_business_cache =
(char *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_1);
size_t node_size = sizeof(APICacheItem), row_cnt = sizeof(auModsInCache)/sizeof(size_t);
size_t hash_tbl_size = CalHashTableWithCacheSize(node_size, row_cnt, auModsInCache);
pstShmData->hash_table.pTable = (void *)((uint8_t *)pstShmData->p_shm_data + EXPT_NEW_SHM_SIZE - hash_tbl_size);
int ret = HashTableWithCacheInit(&pstShmData->hash_table, hash_tbl_size, node_size, row_cnt, auModsInCache);
return ret;
}
intResetExptNewShmData(expt_api_new_shm *pstShmData){
int iOffset = 0;
if (*pstShmData->p_mem_switch <= 1) {
iOffset = 0;
} elseif (*pstShmData->p_mem_switch > 1) {
iOffset = EXPT_NEW_SHM_DATA_SIZE;
}
void *ptrData = MAKE_PTR(void *, pstShmData->p_shm_data,
EXPT_NEW_SHM_HEADER_SIZE + iOffset);
memset(ptrData, 0, EXPT_NEW_SHM_DATA_SIZE);
return0;
}
intResetExptNewShmHeader(expt_api_new_shm *pstShmData){
memset(pstShmData->p_shm_data, 0, EXPT_NEW_SHM_HEADER_SIZE);
return0;
}
voidSwitchNewShmMemToWrite(expt_api_new_shm *pstShmData){
int iSwitchOffset =
EXPT_NEW_SHM_DATA_SIZE * ((*pstShmData->p_mem_switch <= 1 ? 0 : 1));
int ptr_offset = EXPT_NEW_SHM_HEADER_SIZE + iSwitchOffset;
pstShmData->p_new_context =
(expt_new_context *)((uint8_t *)pstShmData->p_shm_data + ptr_offset);
pstShmData->p_param2business =
(parameter2business *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_0);
pstShmData->p_business_cache =
(char *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_1);
}
voidSwitchNewShmMemToWriteDone(expt_api_new_shm *pstShmData){
if (*pstShmData->p_mem_switch <= 1)
*pstShmData->p_mem_switch = 2;
else
*pstShmData->p_mem_switch = 1;
}
voidSwitchNewShmMemToRead(expt_api_new_shm *pstShmData){
int iSwitchOffset =
EXPT_NEW_SHM_DATA_SIZE * ((*pstShmData->p_mem_switch <= 1 ? 1 : 0));
int ptr_offset = EXPT_NEW_SHM_HEADER_SIZE + iSwitchOffset;
pstShmData->p_new_context =
(expt_new_context *)((uint8_t *)pstShmData->p_shm_data + ptr_offset);
pstShmData->p_param2business =
(parameter2business *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_0);
pstShmData->p_business_cache =
(char *)((uint8_t *)pstShmData->p_shm_data + ptr_offset +
EXPT_NEW_SHM_OFFSET_1);
}
雙 buffer 的工作原理就是:設定兩個 buffer,一個用於讀,另一個用於寫。
初始化這兩個 buffer 為空,呼叫 InitExptNewShmData 函式。 對於寫操作,先準備數據,即呼叫 SwitchNewShmMemToWrite 函式,等數據準備完 (即寫完相應的數據) ,然後呼叫 SwitchNewShmMemToWriteDone 函式,完成指標的切換。 對於讀操作,執行緒從讀 buffer 讀取數據,呼叫 SwitchNewShmMemToRead 函式。 |
我們平台的場景主要是讀,而且由於拉取實驗配置采用的都是增量的拉取方式,所以配置的改變也不是很頻繁,也就很少有寫操作的出現。采用雙 buffer 無鎖數據結構的優勢在於可以提高並行效能,由於讀寫操作在不同的 buffer 上同時進行,所以不需要額外加鎖,減少了數據競爭和鎖沖突的可能性。當然這種數據結構也有相應的缺點,就是會多用了一倍的記憶體,用空間換時間。
05
對於特定的場景采用特定的處理方式
這其實也很容易理解,有很多場景是需要客製化最佳化的,所以不能從主體程式碼的層面去最佳化了,那換個思路,是不是可以從返回的數據格式進行最佳化呢?舉個我們過去遇到的一個例子:我們平台有一個染色場景,就是需要對當天登入的所有微信使用者計算命中情況,舊的數據格式其實返回了一堆本身染色場景不需要的欄位,所以這裏其實是可以最佳化的。
最佳化前的數據格式:
structexpt_param_item {
int experiment_id;
int expt_group_id;
int layer_id;
int domain_id;
uint32_t seq;
uint32_t start_time;
uint32_t end_time;
uint8_t expt_type;
uint16_t expt_client_expand;
int parameter_id;
uint8_t value[MAX_PARAMETER_VLEN];
char param_name[MAX_PARAMETER_NLEN];
int value_len;
uint8_t is_pkg = 0;
uint8_t is_white_list = 0;
uint8_t is_launch = 0;
uint64_t bucket_src = 0;
uint8_t is_control = 0;
};
其實染色場景下不需要參數的資訊,只保留實驗 ID、組 ID 以及分桶的資訊就好了。最佳化後的數據格式:
structDyeHitInfo {
int expt_id, group_id;
uint64_t bucket_src;
DyeHitInfo(){}
DyeHitInfo(int expt_id_, int group_id_, uint64_t bucket_src_) :expt_id(expt_id_), group_id(group_id_), bucket_src(bucket_src_){}
booloperator <(const DyeHitInfo &hit) const {
if (expt_id == hit.expt_id) {
if (group_id == hit.group_id) return bucket_src < hit.bucket_src;
return group_id < hit.group_id;
}
return expt_id < hit.expt_id;
}
booloperator==(const DyeHitInfo &hit) {
return hit.expt_id == expt_id && hit.group_id == group_id && hit.bucket_src == bucket_src;
}
std::stringToString()const{
char buf[1024];
sprintf(buf, "expt_id: %u, group_id: %u, bucket_src: %lu", expt_id, group_id, bucket_src);
returnstd::string(buf);
}
};
最佳化前後效能對比:

所以其實針對某些特殊場景做一些客製化的開發成本也沒有很高,但是帶來的收益卻是巨大的。
06
善用效能測試工具
這裏列舉一些常見的效能測試工具:linux 提供的 perf、GNU 編譯器提供的 gprof、Valgrind、strace 等等。
這裏推薦幾個覺得好用的工具:
perf ( linux 內建效能測試工具)
https://godbolt.org/ (可以檢視程式碼對應的組譯程式碼)
微信運維提供的效能測試工具:
https://github.com/brendangregg/FlameGraph (生成火焰圖的工具)
07
總結
其實還有一些效能最佳化的地方,比如使用合適的數據結構和演算法,減少大物件的拷貝,減少無效的計算,IO 與計算分離,分支預測等等,後續如果有時間的話可以再更新一篇新的文章。效能最佳化不是一錘子買賣,所以需要一直監控,一直最佳化。需要註意的一點是不要過度最佳化,在提升程式效能的時候不要丟掉程式碼的可維護性,而且還要評估下效能提升帶來的收益是否與花費的時間成正比。總之,效能最佳化,長路漫漫。 如果覺得本篇文章的內容對你有幫助, 歡迎轉發分享。
如喜歡本文,請點選右上角,把文章分享到朋友圈
如有想了解學習的技術點,請留言給若飛安排分享
因公眾號更改推播規則,請點「在看」並加「星標」 第一時間獲取精彩技術分享
·END·
相關閱讀:
作者:張江濤
來源:騰訊雲開發者
版權申明:內容來源網路,僅供學習研究,版權歸原創者所有。如有侵權煩請告知,我們會立即刪除並表示歉意。謝謝!
架構師
我們都是架構師!

關註 架構師(JiaGouX),添加「星標」
獲取每天技術幹貨,一起成為牛逼架構師
技術群請 加若飛: 1321113940 進架構師群
投稿、合作、版權等信箱: [email protected]











