計畫簡介
MedicalGPT 是一個基於ChatGPT訓練流程的醫療行業語言模型計畫,主要包括增量預訓練、有監督微調和強化學習。計畫旨在透過不同的訓練階段,最佳化模型以更好地適應醫療數據,提高問答和文本生成的準確性和品質。此外,該計畫還引入了直接偏好最佳化(DPO)和無參考模型的最佳化(ORPO)技術,使得模型在無需復雜的強化學習框架下,能夠有效學習並適應人類偏好。計畫透過多種數據集和訓練策略,實作了模型的持續前進演化和功能擴充套件。
掃碼加入交流群
獲得更多技術支持和交流
(請註明自己的職業)


特點
基於ChatGPT訓練流程,本計畫實作了一個專註於醫療行業的語言大模型訓練:
第一階段:PT(Continue PreTraining,持續預訓練)在海量領域文件數據上進行增量預訓練,以使GPT模型適應領域數據分布。
第二階段:SFT(Supervised Fine-tuning,有監督微調)構建有指令的微調數據集,在已預訓練的模型基礎上進行指令精調,以匹配指令意圖並融入領域知識。
第三階段包括兩部份:
· RM(Reward Model,獎勵模型)透過構建人類偏好排序的數據集訓練獎勵模型,用以模擬人類偏好,主要遵循「有益、誠實、無害」(HHH)的原則。
· RL(Reinforcement Learning,強化學習)利用獎勵模型訓練SFT模型,使得生成模型透過獎勵或懲罰更新其策略,從而生成更高品質、更符合人類偏好的文本。
DPO(Direct Preference Optimization,直接偏好最佳化)方法透過直接最佳化語言模型的行為,無需復雜的強化學習流程,有效地學習人類偏好,相較於RLHF,DPO更易實作且訓練效果更優。
ORPO(無需參考模型的最佳化方法)使語言大模型能夠同時學習遵循指令和滿足人類偏好。
DEMO
開發了一個基於Gradio的簡潔互動式Web界面。服務啟動後,可以透過瀏覽器存取,輸入問題,隨後模型將提供答案。
啟動服務的命令如下:
CUDA_VISIBLE_DEVICES=0 python gradio_demo.py --model_type base_model_type --base_model path_to_llama_hf_dir --lora_model path_to_lora_dir
參數詳情如下:
--model_type {base_model_type}:指定預訓練模型的型別,支持的型別包括llama、bloom、chatglm等。
--base_model {base_model}:指定儲存LLaMA模型權重和配置檔的目錄,也可以使用來自HF Model Hub的模型呼叫名稱。
--lora_model {lora_model}:指定LoRA檔的儲存目錄,也可以使用HF Model Hub的模型呼叫名稱。如果LoRA權重已經整合到預訓練模型中,可省略此參數。
--tokenizer_path {tokenizer_path}:指定tokenizer檔的儲存目錄。如果未指定此參數,其預設值與--base_model相同。
--template_name:設定樣版名稱,例如vicuna、alpaca等。如果未指定,其預設值為vicuna。
--only_cpu:設定僅使用CPU進行模型推理。
--resize_emb:設定是否調整embedding的大小。如果不進行調整,則使用預訓練模型中的embedding大小,預設為不調整。
安裝
要適配最新功能,requirements.txt 檔可能需要不時進行更新。更新依賴時,使用以下命令:
git clone https://github.com/shibing624/MedicalGPTcd MedicalGPTpip install -r requirements.txt --upgrade
此外,對於硬體需求,特別是視訊記憶體(VRAM),請確保你的裝置符合最新功能的需求。更新硬體規格可以幫助確保應用程式執行流暢並充分利用新功能。
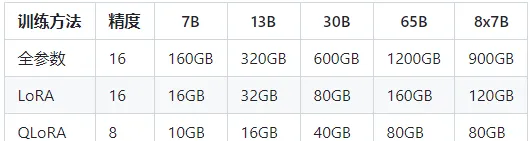
訓練

1.提供完整PT+SFT+DPO全階段串起來訓練的pipeline:run_training_dpo_pipeline.ipynb ,其對應的colab:
https://colab.research.google.com/github/shibing624/MedicalGPT/blob/main/run_training_dpo_pipeline.ipynb
執行完大概需要15分鐘,執行成功後的副本colab:
https://colab.research.google.com/drive/1kMIe3pTec2snQvLBA00Br8ND1_zwy3Gr?usp=sharing
2.提供完整PT+SFT+RLHF全階段串起來訓練的pipeline:run_training_ppo_pipeline.ipynb ,其對應的colab:
https://colab.research.google.com/github/shibing624/MedicalGPT/blob/main/run_training_ppo_pipeline.ipynb
執行完大概需要20分鐘,執行成功後的副本colab:
https://colab.research.google.com/drive/1RGkbev8D85gR33HJYxqNdnEThODvGUsS?usp=sharing
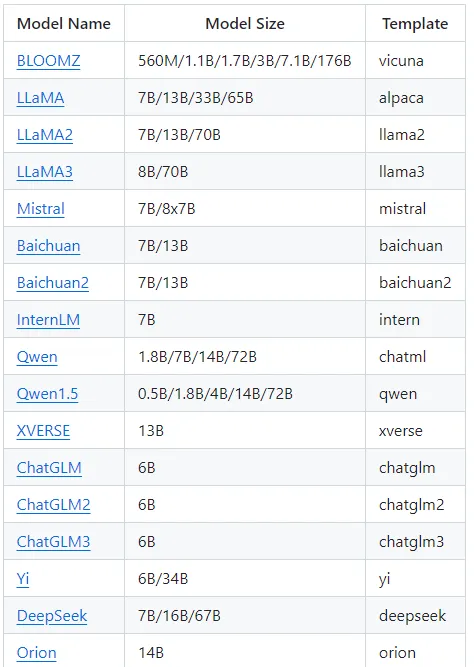
支持的模型
推理
訓練完成後,載入訓練好的模型,驗證模型生成文本的效果
CUDA_VISIBLE_DEVICES=0 python inference.py \ --model_type base_model_type \ --base_model path_to_model_hf_dir \ --tokenizer_path path_to_model_hf_dir \ --lora_model path_to_lora \ --interactive
多卡推理
CUDA_VISIBLE_DEVICES=0,1 torchrun --nproc_per_node 2 inference_multigpu_demo.py --model_type baichuan --base_model shibing624/vicuna-baichuan-13b-chat
計畫連結
https://github.com/shibing624/MedicalGPT
關註「 開源AI計畫落地 」公眾號
與AI時代更靠近一點











