unset unset 簡介 unset unset
提高 RAG 推理能力的一個好方法是添加查詢理解層 ——在實際查詢向量儲存之前添加查詢轉換。以下是四種不同的查詢轉換:
路由:保留初始查詢,同時查明其所屬的適當工具子集。然後,將這些工具指定為合適的選項。
查詢重寫:維護選定的工具,但以多種方式重新編寫查詢,以將其套用於同一組工具。
子問題:將查詢分解為幾個較小的問題,每個問題針對由其後設資料確定的不同工具。
ReAct Agent 工具選擇:根據原始查詢,確定要使用的工具並制定要在該工具上執行的特定查詢。
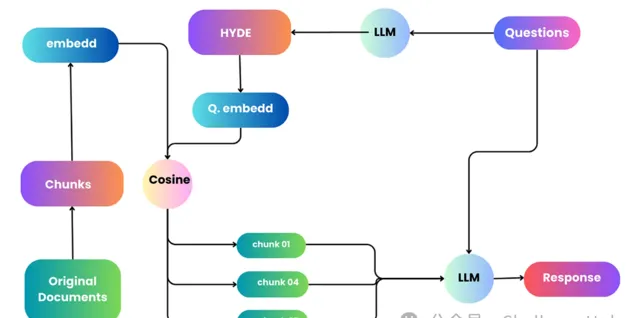
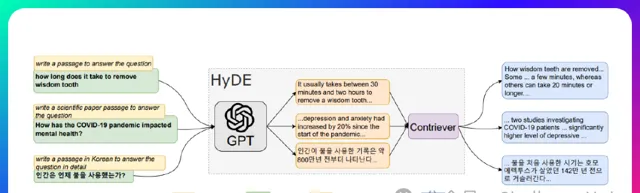
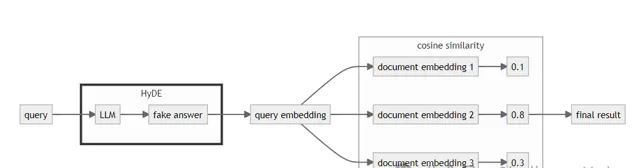
HyDE來自於Precise Zero-Shot Dense Retrieval without Relevance Labels,這篇文章主要做zero-shot場景下的稠密檢索,透過借助LLM的力量不需要Relevance Labels,開箱即用。作者提出Hypothetical Document Embeddings (HyDE)方法,即「假設」文件嵌入。具體的做法是透過GPT生成虛構的文件,並使用無監督檢索器對其進行編碼,並在其嵌入空間中進行搜尋,從而不需要任何人工標註數據 模型結構如下圖所示,HyDE將密集檢索分解為兩個任務,即 instruction-following的LM生成任務和對比編碼器執行的文件相似性任務。
paper:https://arxiv.org/pdf/2212.10496
code:https://github.com/texttron/hyde
unset unset 原理以及實作 unset unset
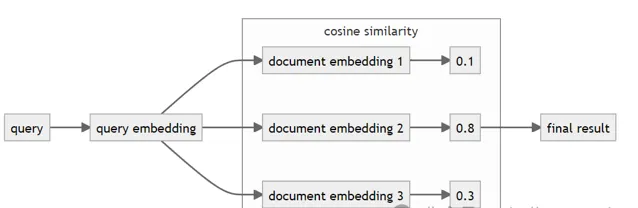
典型的密集資訊檢索過程包括以下步驟:
將查詢和文件轉換為嵌入(向量)
計算查詢和文件之間的余弦相似度
返回余弦相似度最高的文件
from langchain.embeddings import OpenAIEmbeddings
from langchain.chains import LLMChain, HypotheticalDocumentEmbedder
from langchain.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from dotenv import load_dotenv
# set the environment variables
load_dotenv()
# prepare the prompt template for document generation
Prompt_template = """回答問題。
問題:{question}
回答:」」」
llm = ChatOpenAI()
# multi_llm = ChatOpenAI(n=4)
prompt = PromptTemplate(input_variables=["question"], template=prompt_template)
llm_chain = LLMChain(llm=llm, prompt=prompt, verbose=True)
# initialize the hypothetical document embedder
base_embeddings = OpenAIEmbeddings()
embeddings = HypotheticalDocumentEmbedder(llm_chain=llm_chain, base_embeddings=base_embeddings)
result = embeddings.embed_query("塞爾達傳說的主角是誰?")
len(result)











