Flink集群部署
Flink的安裝和部署主要分為本地(單機)模式和集群模式,其中本地模式只需直接解壓就可以使用,不用修改任何參數,一般在做一些簡單測試的時候使用。本地模式在這裏不再贅述。集群部署模式主要包含Standalone、Hadoop Yarn 、Kubernetes等,Flink可以借助以上檔案總管來實作分布式計算,目前企業使用最多的是Flink 基於Hadoop Yarn檔案總管模式,下面我們重點講解Flink 基於Standalone集群、Yarn檔案總管以及Kubernetes集群部署方式。
一、Standalone集群部署
1、節點劃分
透過Flink執行時架構小結,我們知道Flink集群是由一個JobManager(Master)節點和多個TaskManager(Worker)節點構成,並且有對應送出任務的客戶端。這裏部署Standalone集群基於Linux Centos7.6版本,選擇4台節點進行部署Flink,其中3台節點Standalone集群節點、一台節點是送出Flink任務的客戶端,各個節點需要滿足以下特點:
各節點安裝java8版本及以上jdk(這裏選擇jdk8)。
各個節點之間需要兩兩免密。
4台節點角色劃分如下:
節點IP | 節點名稱 | Flink服務 |
|---|---|---|
192.168.179.4 | node1 | JobManager,TaskManager |
192.168.179.5 | node2 | TaskManager |
192.168.179.6 | node3 | TaskManager |
192.168.179.7 | node4 | client |
2、standalone集群部署
我們可以從Flink的官網下載Flink最新的安裝包,這裏選擇Flink1.16.0版本,Flink安裝包下載地址:https://flink.apache.org/downloads.html#apache-flink-1160。Standalone集群部署步驟如下:
上傳壓縮包解壓
將Flink的安裝包上傳到node1節點/software下並解壓:
[root@node1 software]# tar -zxvf ./flink-1.16.0-bin-scala_2.12.tgz
配置 Master 節點
配置Master節點就是配置JobManager節點,在$FLINK_HOME/conf/masters檔中配置jobManager節點如下:
#vim $FLINK_HOME/conf/masters
node1:8081
配置 Worker 節點
配置Worker節點就是配置TaskManager節點,在$FLINK_HOME/conf/workers檔中配置taskManager節點如下:
#vim $FLINK_HOME/conf/workers
node1
node2
node3
配置 flink-conf.yaml 檔
在node1節點上進入到FLINK_HOME/conf目錄下,配置flink−conf.yaml檔(vimFLINK_HOME/conf/flink-conf.yaml配置如下內容),內容如下:
# JobManager地址
jobmanager.rpc.address: node1
# JobManager地址繫結設定
jobmanager.bind-host:0.0.0.0
# TaskManager地址繫結設定
taskmanager.bind-host:0.0.0.0
# TaskManager地址(不同TaskManager節點host配置對應的host)
taskmanager.host: node1
# 設定每個TaskManager 的slot個數
taskmanager.numberOfTaskSlots:3
# WEBUI 節點(只需JobManager節點設定,TaskManager節點設定了也無所謂)
rest.address: node1
# WEBUI節點繫結設定(只需JobManster節點設定)
rest.bind-address:0.0.0.0
註意:以上設定的0.0.0.0代表監聽當前節點每一個可用的網路介面,0.0.0.0不再是一個真正意義上的ip地址,而表示一個集合,監聽0.0.0.0的埠相當於是可以監聽本機中的所有ip埠。以上配置的0.0.0.0 表示想要讓外部存取需要設定具體ip,或者直接設定為"0.0.0.0"。
分發安裝包並配置 node2 、 node3 節點 flink-conf.yaml 檔
#分發到node2、node3節點上
[root@node1 ~]# scp -r /software/flink-1.16.0 node2:/software/
[root@node1 ~]# scp -r /software/flink-1.16.0 node3:/software/
#修改node2、node3 節點flink-conf.yaml檔中的TaskManager
【node2節點】 taskmanager.host: node2
【node3節點】 taskmanager.host: node3
#註意,這裏發送到node4,node4只是客戶端
[root@node1 ~]# scp -r /software/flink-1.16.0 node4:/software/
啟動 Flink 集群
#在node1節點中,啟動Flink集群
[root@node1 ~]# cd /software/flink-1.16.0/bin/
[root@node1 bin]# ./start-cluster.sh
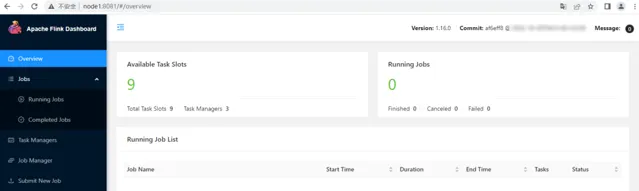
存取 Flink WebUI
https://node1:8081,進入頁面如下:
3、任務送出測試
Standalone集群搭建完成後,可以將Flink任務送出到Flink Standalone集群中執行。有兩種方式送出Flink任務,一種是在WebUI界面上送出Flink任務,一種方式是透過命令列方式。
這裏編寫讀取Socket數據進行即時WordCount統計Flink任務送出到Flink集群中執行,這裏以Flink Java程式碼為例來實作,程式碼如下:
/**
* 讀取Socket數據進行即時WordCount統計
*/
public classSocketWordCount {
publicstaticvoidmain(String[] args) throws Exception {
//1.準備環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.讀取Socket數據
DataStreamSource<String> ds = env.socketTextStream("node5", 9999);
//3.準備K,V格式數據
SingleOutputStreamOperator<Tuple2<String, Integer>> tupleDS = ds.flatMap((String line, Collector<Tuple2<String, Integer>> out) -> {
String[] words = line.split(",");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
//4.聚合打印結果
tupleDS.keyBy(tp -> tp.f0).sum(1).print();
//5.execute觸發執行
env.execute();
}
}
以上程式碼編寫完成後,在對應的計畫Maven pom 檔中加入以下plugin:
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.6</version>
<configuration>
<!-- 設定false後是去掉 xxx-1.0-SNAPSHOT-jar-with-dependencies.jar 後的 「-jar-with-dependencies」 -->
<!--<appendAssemblyId>false</appendAssemblyId>-->
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<main class>xx.xx.xx</main class>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
然後使用Maven assembly 外掛程式對計畫進行打包,得到"FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar"完整jar包。
此外,程式碼中讀取的是node5節點scoket 9999埠數據,需要在node5節點上安裝nc元件:
[root@node5 ~]# yum -y install nc
命令列送出 Flink 任務
在 node1 上啟動 Flink Standalone 集群
[root@node1 bin]# cd /software/flink-1.16.0/bin/
[root@node1 bin]# ./start-cluster.sh
在 node5 節點上啟動 nc socket 服務
[root@node5 ~]# nc -lk 9999
將打好的包送出到 Flink 客戶端 node4 節點 /root 目錄下並送出任務
[root@node4 ~]# cd /software/flink-1.16.0/bin/
#向Flink集群中送出任務
[root@node4 bin]# ./flink run -m node1:8081-c com.mashibing.flinkjava.code.lesson03.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
進入Flink WebUI 界面檢視任務和結果
#向node5 socket 9999 埠寫入以下數據
hello,a
hello,b
hello,c
hello,a
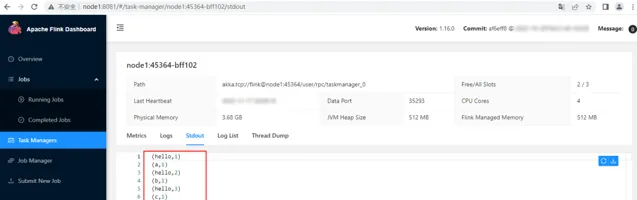
WebUI 檢視對應任務和結果
登入Flink WebUI http://node1:8081檢視對應任務執行情況。

WebUI檢視執行結果:
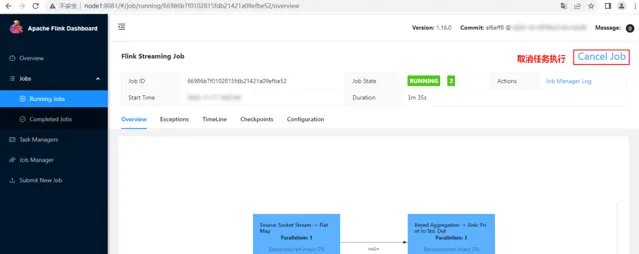
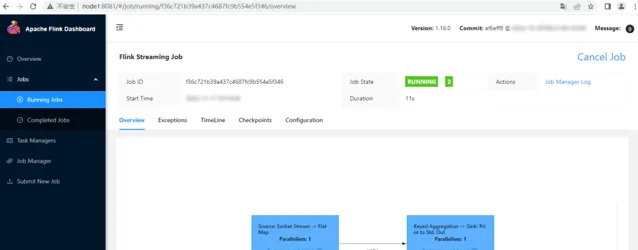
在WebUI中點選對應的任務Job,進入如下頁面點選"Cancel Job"取消任務執行:
Web 界面送出 Flink 任務
向Flink集群送出任務還可以透過WebUI方式送出。點選上傳jar包,進行參數配置,並送出任務。
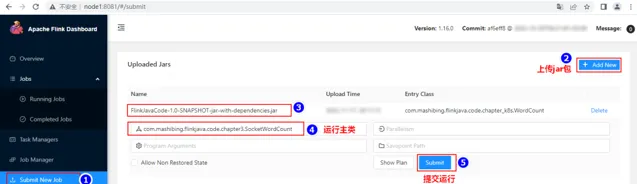
送出任務之後,可以透過WebUI頁面檢視送出任務,輸入數據之後可以在對應的TaskManager節點上看到相應結果。
二、Flink On Yarn
Flink可以基於Yarn來執行任務,Yarn作為資源提供方,可以根據Flink任務資源需求動態的啟動TaskManager來提供資源。Flink基於Yarn送出任務通常叫做Flink On Yarn,Yarn資源排程框架執行需要有Hadoop集群,Hadoop版本最低是2.8.5。
1、Flink不同版本與Hadoop整合
Flink基於Yarn送出任務時,需要Flink與Hadoop進行整合。Flink1.8版本之前,Flink與Hadoop整合是透過Flink官方提供的基於對應hadoop版本編譯的安裝包來實作,例如:flink-1.7.2-bin-hadoop24-scala_2.11.tgz,在Flink1.8版本後不再支持基於不同Hadoop版本的編譯安裝包,Flink與Hadoop進行整合時,需要在官網中下載對應的Hadoop版本的"flink-shaded-hadoop-2-uber-x.x.x-x.x.jar"jar包,然後後上傳到送出Flink任務的客戶端對應的$FLINK_HOME/lib中完成Flink與Hadoop的整合。
在Flink1.11版本之後不再提供任何更新的flink-shaded-hadoop-x jars,Flink與Hadoop整合統一使用基於Hadoop2.8.5編譯的Flink安裝包,支持與Hadoop2.8.5及以上Hadoop版本(包括Hadoop3.x)整合。在Flink1.11版本後與Hadoop整合時還需要配置HADOOP_ classPATH環境變量來完成對Hadoop的支持。
2、Flink on Yarn 配置及環境準備
Flink 基於Yarn送出任務,向Yarn集群中送出Flink任務的客戶端需要滿足以下兩點
客戶端安裝了Hadoop2.8.5+版本的hadoop。
客戶端配置了HADOOP_ classPATH環境變量。
這裏選擇node5節點作為送出Flink的客戶端,該節點已經安裝了Hadoop3.3.4版本,然後在該節點中配置profile檔,加入以下環境變量:
# vim /etc/profile,加入以下配置
exportHADOOP_ classPATH=`hadoop classpath`
#source /etc/profile 使環境變量生效
[root@node5 ~]# source /etc/profile
然後將Flink的安裝包上傳到node5節點/software下並解壓:
[root@node5 software]# tar -zxvf ./flink-1.16.0-bin-scala_2.12.tgz
3、任務送出測試
基於Yarn執行Flink任務只能透過命令列方式進行任務送出,Flink任務基於Yarn執行時有幾種任務送出部署模式(後續章節會進行介紹),下面以Application模式來送出任務。步驟如下:
啟動 HDFS 集群
#在 node3、node4、node5節點啟動zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
#在node1啟動HDFS集群
[root@node1 ~]# start-all.sh
將 Flink 任務對應的 jar 包上傳到 node5 節點
這裏的Flink任務還是以讀取Socket數據做即時WordCount任務為例,將打好的"FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar"jar包上傳到node5節點的/root/目錄下。
在 node5 節點執行如下命令執行 Flink 作業
[root@node5 ~]# cd /software/flink-1.16.0/bin/
# 送出Flink任務
[root@node5 bin]#./flink run-application -t yarn-application -c com.mashibing.flinkjava.code.chapter3.SocketWordCount /root/FlinkJavaCode-1.0-SNAPSHOT-jar-with-dependencies.jar
檢視 WebUI 及執行結果
Flink任務Application模式送出後,瀏覽器輸入https://node1:8088登入Yarn WebUI,找到送出的任務,點選對應的Tracking UI"ApplicationMaster"進入到Flink WEBUI任務頁面。
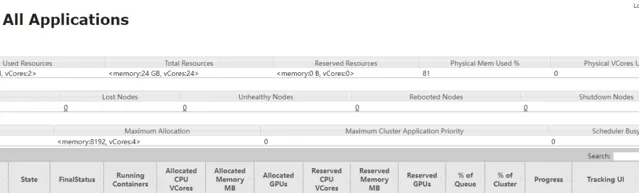
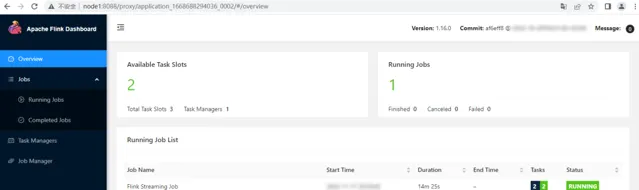
向node5 scoket 9999埠輸入以下數據並在對應的WebUI中檢視結果:
#向node5 socket 9999 埠寫入以下數據
hello,a
hello,b
hello,c
hello,a
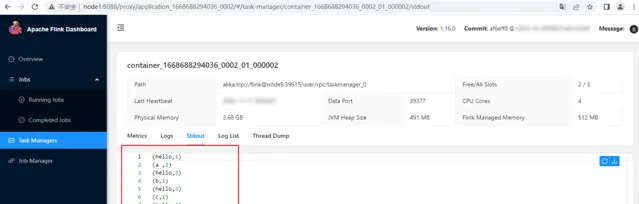
在WebUI中找到對應的Flink TaskManager節點 Stdout輸出,結果如下:
連結:https://bbs.huaweicloud.com/blogs/396356
( 版權歸華為雲社群 原作者所有,侵刪)