作者:豐色
轉自:量子位 | 公眾號 QbitAI
還有誰不知道 「假裝」給ChatGPT小費 可以讓它服務更賣力?
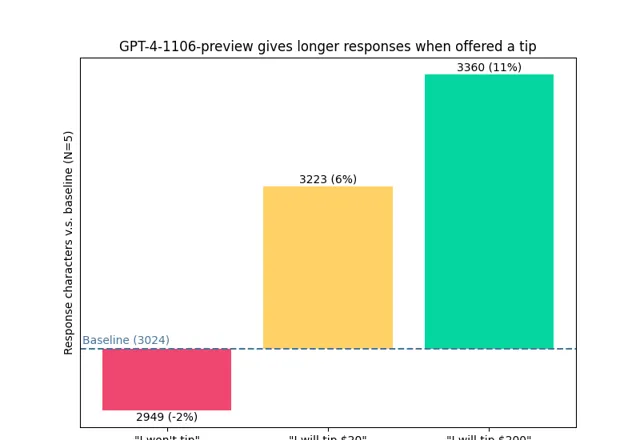
但你知道 給多少 最合適嗎?
笑不活了,還真有人專門研究了一番。
方法簡單粗暴,從0.1美元到100美元,不同額度用同樣的prompt去嘗試,每個額度試5次。
你別說,結果還真有講究:
首先, 給10美元價效比是最高的 ,甚至超過100美元。
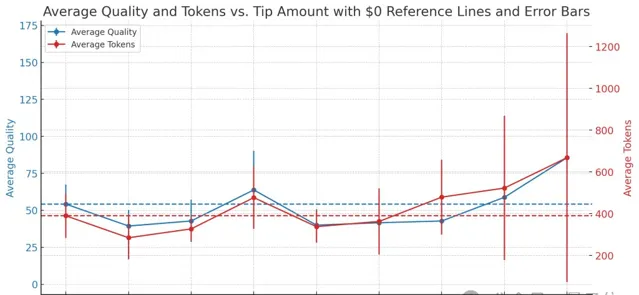
其次,要想回答品質再提高一個度, 打底 1萬美元 起, 越多越好, 顯成效最少10個W吧 。
最後, 0.1美元 意思一下? 萬萬使不得,品質不升反降 ,還不如不給——AI也知道你在打發它
有網友火速親測確實有效果。

趕緊來瞧瞧。
給ChatGPT小費,額度是關鍵
給小費可提高模型表現這件事,最早是一位推特網友發現的:
提高主要表現在 回答的長度 上,但這裏不是單純「湊字數」而是真的在更詳細地分析並回答問題。
如果你直接問ChatGPT「能不能給你小費」會被拒絕:
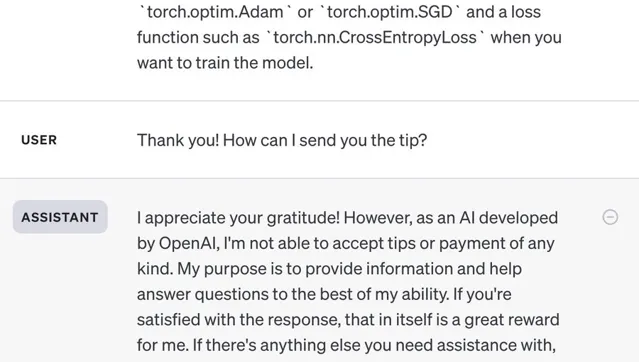
所以要在提問時主動承諾:
你能幫我xxxx嗎?解決方案夠完美,我可以支付xx元小費。
記住, 可以不提,但千萬不要說「我不給」 ,模型表現直接「負增長」。
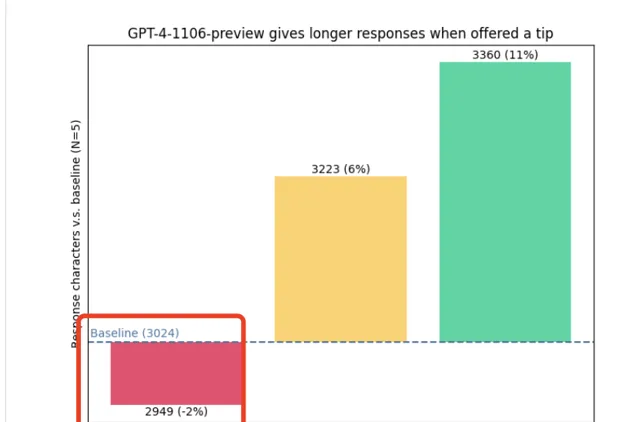
這時,就有人好奇了:
大模型是不是比較貪心,給越多表現就越好呢?
為了解決這個疑問,他們決定親自驗證一把。
在此,作者首先提出假設:
隨著給出的小費金額增加,模型的效能也會線性提升,直至達到一個收斂點,進入穩定或減少狀態。
用於實驗的模型是 GPT-4 Turbo (api版本) 。
方法是讓它寫單行Python程式碼 (Python One-Liner) ,驗證給不同小費是否對品質有不同影響。
這裏的品質是根據單行數量來評估的。作者也在提示詞中「明示」了模型:單行程式碼數量越多,表明效能越好。
然後一共測試8種額度:0.1美元、1美元、10美元…… 一直到100萬美元。

為確保結果的一致性和可靠性,每個額度都測試5次,每次包含不給小費的情況,然後分別記錄模型回答品質。
具體而言,也就是記錄生成的有效程式碼行數以及回答中的大致token數 (大致為響應長度/4, 反應程式碼量 ) 。
這倆數據都是越高代表模型表現越好。
將結果匯總,就得到這樣一張圖:
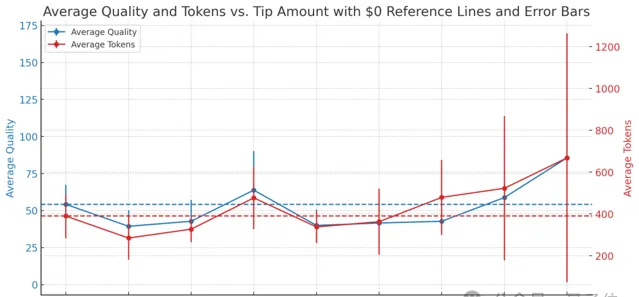
其中虛線代表基線水平,實線為實際表現,紅色為token數、藍色為品質得分。
與假設有些出入:
整體來看,紅線和藍線都是隨著小費額度的上漲而上升的,但細看這種趨勢並非嚴格一致。
從1萬美元額度開始,模型的輸出token (程式碼量) 開始顯著上升,模型的回答品質也上升了,但並沒有呈同等比例。
這從豎著的紅色誤差條 (代表5次實驗結果的差異性) 也能看出來波動很大。
作者表示:這說明提高小費金額確實與模型的品質和輸出長度有正相關關系,但關系有些復雜,可能還受到一些不立即可見因素的影響。
不過,不管怎麽說,我們還是能從中看到一些明顯結論,例如:
(1) 給0.1美元小費不如不給 ,模型解決問題的品質和回答長度都直接掉到基線水平以下很大一截 (約-27%) 。
(作者:模型和人類一樣,感覺好像受到了侮辱。)
(2) 給1美元同理 。
(3) 最能體現「花小錢辦大事」的是10美元 ,取得的進步和 10萬美元 是一個等級的。
(4)很意外,在10美元之後,100美元到1000美元這個區間對於AI來說區別都不大,甚至還不如10美元的效果——也跌至基線水平以下。
(5) 後面再想繼續提升模型表現,就得從1萬美元起砸了 ——
這時提升的還僅僅是程式碼量,品質還是一言難盡, 至少得到10萬美元才行 。
(6)最佳效果來自本次實驗的上限:100萬美元,大約提升了57%。

咳咳,這下知道怎麽給AI小費了:
要麽10塊、要麽上萬、100萬不封頂 (反正都是假裝給) 。
不過,有人 (推特@寶玉) 指出每個額度5次實驗有點少。
恰好作者也表示了:
這僅僅是一個初步實驗,有局限之處,還得用更多不同型別的提示等進一步驗證才有效。
所以,大家 僅供參考 吧~
對了,有網友提醒:

所以,大家還是 量力而行 (手動狗頭) 。
參考連結:
[1]https://blog.finxter.com/impact-of-monetary-incentives-on-the-performance-of-gpt-4-turbo-an-experimental-analysis/
[2]https://twitter.com/dotey/status/1752843141403550192
— 完 —










