雲音樂服務監控系統(代號:Pylon APM)為業務提供服務監控、鏈路追蹤、治理分析、問題診斷等能力,本文介紹了平台建設中的一些實踐經驗。
一、背景介紹
雲音樂伺服端原有的伺服端套用監控體系,存在很多痛點和問題,導致出現線上問題時,定位的效率不太理想。伺服端套用監控體系主要存在以下幾個問題:
Trace鏈路完整性問題: 老的trace是透過元件sdk埋點的形式,進行trace的記錄與輸出,導致了trace的完整性依賴埋點邏輯,如果鏈路埋點處理不正確,會出現上下文異步透傳遺失,trace數據沖突混亂的問題。同時,對於異常的非采樣鏈路,在采集時,無法回溯上遊來源,經常出現定位資訊不足的問題。
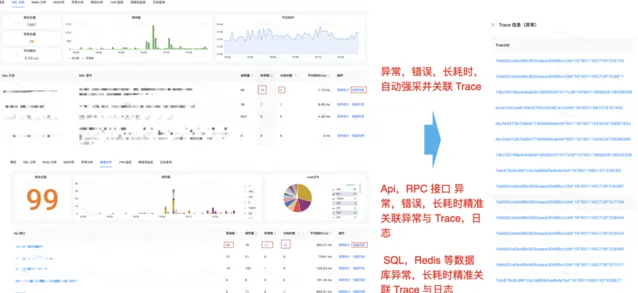
Trace與Metric割裂問題: trace與metric之間缺少數據關聯,metric服務監控數據依賴其他平台,導致慢請求,慢sql之類的問題場景定位時,找不到具體發生問題的trace。線上發生異常錯誤指標報警時,很難找到對應的錯誤鏈路,定位問題效率低下。
Trace與日誌聯動問題: 業務服務產生ERROR日誌時,有追溯異常呼叫的來源的需求。低取樣率的線上場景,只能找到日誌,而找不到請求的具體鏈路,對問題排查幫助很小。
版本升級叠代困難: 版本升級依賴業務服務升級sdk,推進困難,功能叠代效率低。
開源計畫中Pinpoint和SkyWalking都是目前比較成熟的鏈路追蹤方案,兩者各有優劣,在對比中,我們發現Pinpoint與雲音樂的鏈路模型更加接近,外掛程式開發也更加友好,並且國內有多個基於Pinpoint的商業化落地計畫,穩定性有保障。
最終我們選擇基於Pinpoint開源方案,進行了深度的自研改造和最佳化,希望達成以下目標:
業務服務解耦: Java Agent形式實作套用監控功能,與服務程式碼完全解耦,業務無感知接入,無感知升級。外掛程式化實作,能夠在管控平台透過開關動態控制細粒度功能的開關。
保證鏈路完整性: 透過異步上下文管理無感知解決了鏈路異步透傳的問題,保證trace透傳的完整性。同時透過TailBased方案,實作了異常錯誤鏈路完整采樣的能力,最大限度的保證鏈路問題定位有效性。
整合Metric能力: 透過整合prometheus元件,實作了套用服務監控的能力,開發相比哨兵監控項更加簡單。同時實作了Metric監控聯通Trace的能力,對於指定監控指標,能夠根據監控值檢索對應Trace。
問題快速診斷: 不論是異常日誌,還是錯誤、長耗時呼叫,都能透過後設資料或監控數據關聯到完整的鏈路,在平台快速下鉆,提升問題定位效率。
問題診斷工具: 提供自動異常現場采集能力,整合白屏化診斷工具,完善問題分析能力。
二、計畫思路與方案
1.計畫整體架構
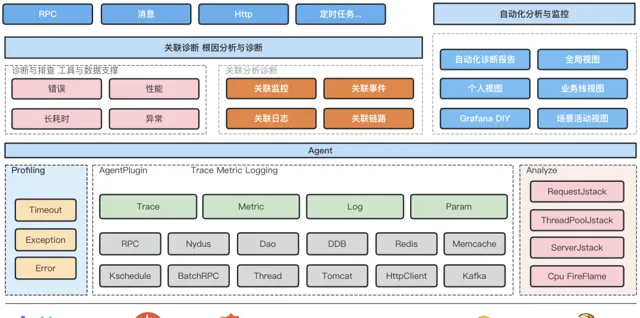
主要分為Agent和Console兩個部份,Agent主要負責Trace生成與傳遞,Metric記錄與上報,實作了一套字節碼註入工具,以及數據處理框架,再透過外掛程式化的形式,實作不同元件的trace與metric能力。Console主要負責數據的收集與儲存,分析與展示,將Trace,metric,log聯動的數據模型,透過鏈路問題定位能力串聯起來,實作快速的問題診斷。
2.基於Pinpoint開發的Java Agent
開源的Pinpoint實作了外掛程式化的Trace能力,並且實作了很多常用的中介軟體的外掛程式,但是開源Pinpoint Agent依舊存在以下問題:
Trace模型過於簡單,對於部份Trace使用場景無法很好支持(比如訊息佇列多個消費者的場景,消費者之間無法區分),支持的鏈路型別有限,後設資料管理不方便。
上下文透傳能力支持不足,Trace上下文因為支持透傳,很多時候業務上下文,可以復用這部份能力,不需要重復開發,Pinpoint這塊支持不足。
異常鏈路回溯采樣不完整,對於非采樣鏈路,出現異常時,無法回溯采集上遊,定位效率會大打折扣。
不支持Metric能力,無法關聯監控數據,浪費了切面中的數據與狀態結果。
1)擴充套件Trace數據模型
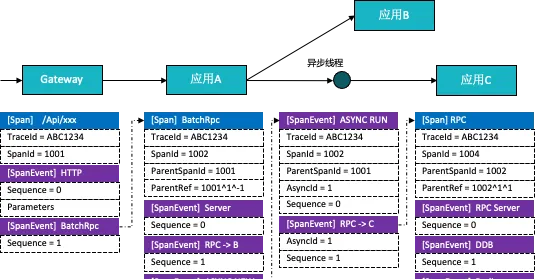
基於Pinpoint Trace-Span-SpanEvent的模型,擴充套件了部份關聯欄位和透傳欄位,使得Trace能夠支持多下遊關聯,異步下遊關聯,異步回呼關聯等能力。在上下文透傳上,支持行程內欄位透傳,跨行程欄位透傳,跨行程欄位反向透傳,並提供專門的透傳sdk供接入方使用。
2)異常鏈路後置采樣
鏈路上發生單點異常時,如果只是把異常點及其下遊鏈路采集上來是比較容易的,但是這樣帶來的問題定位收益並不高,很多時候不知道上遊來源的話,問題定位無法繼續下去。為了解決異常鏈路完整采樣的問題,我們實作了一套TailBased的異常鏈路采集能力。具體方案示意如下圖:
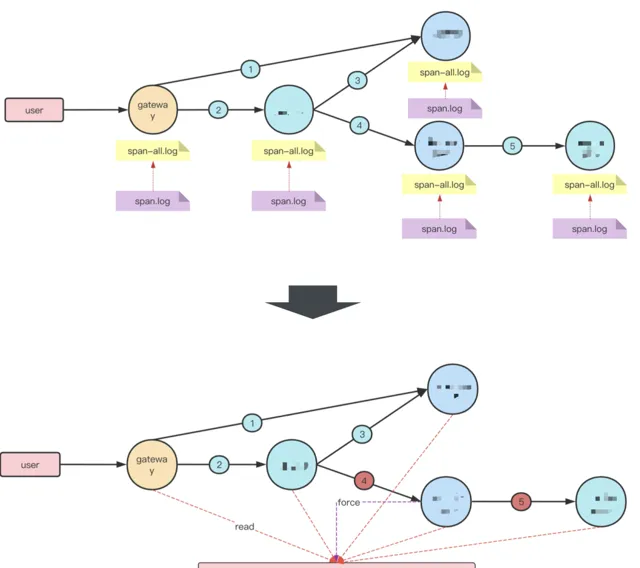
每個服務節點上,對於短時間內的Trace,會先全量輸出到一個全量日誌中,當鏈路上發生異常時,對應服務的Agent會將異常TraceId寫入到中心化緩存中,並在Trace上下文資訊中帶上標記。獨立的Tail執行緒會以一個穩定的延遲(30s~1min),掃描全量日誌中的trace數據,發現存在於緩存中的異常TraceId後,將該TraceId關聯的鏈路數據寫入到最終的采集日誌中,實作完整的鏈路采集。
3)Prometheus監控整合
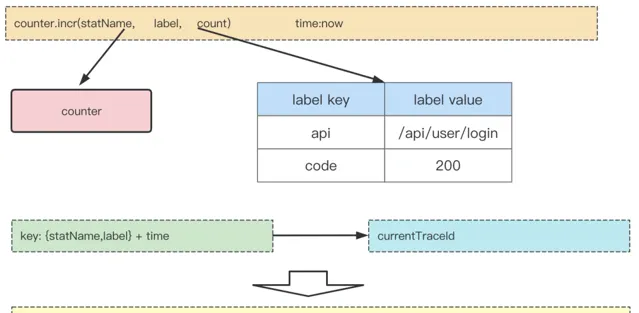
我們在Agent端整合Prometheus sdk,用以記錄和輸出監控數據,伺服端透過Pull請求定時拉取每台服務上的監控數據,進行數據的預聚合,最終寫入到vm storage儲存中。監控數據在記錄過程中,還會與當前TraceId進行關聯,輸出到關聯日誌中,保證每項監控數據,都有一定的Trace鏈路數據進行關聯定位與分析。關聯示意圖如下所示:
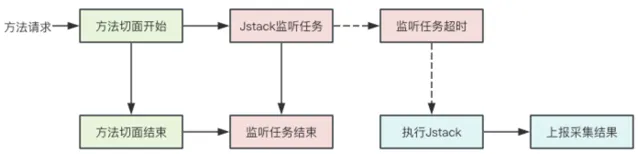
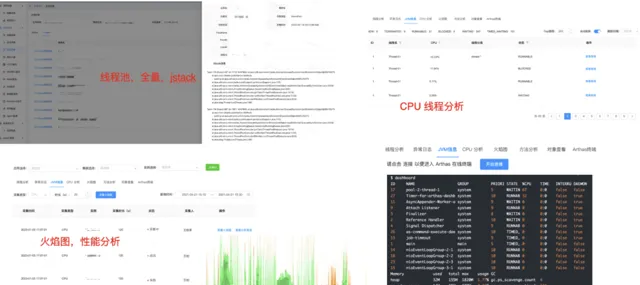
4)自動Jstack采集
線上服務在發生問題時,經常要面對抓不到現場的情況。我們對於有可能出現服務阻塞的場景,啟動了異步監聽任務。當呼叫方法執行時間超出設定閾值時,對當前執行緒執行一次Jstack堆疊采集,將當前的執行現場保存下來,同時關聯TraceId和方法監控指標,便於追溯。流程示意圖如下:
3.APM產品設計
開源的Pinpoint內建了pinpoint-web管控界面並不能滿足我們的需求,我們重新開發了一套APM平台,以套用為中心視角,劃分不同維度的監控指標,再到不同監控視角下,透過Trace,Metric,Log聯動,來幫助快速定位線上問題,APM平台主要具備以下幾個能力。
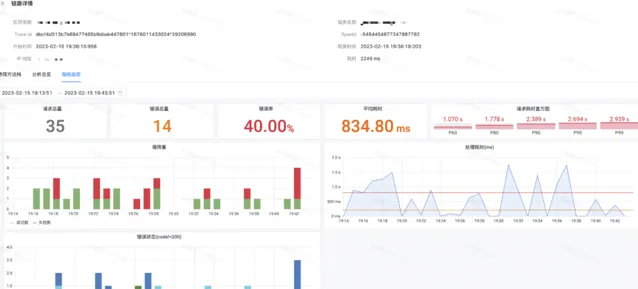
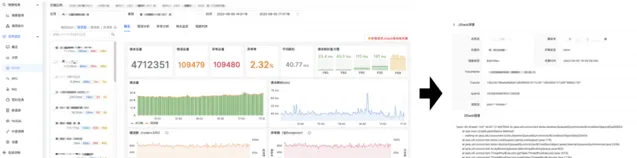
1)鏈路詳情診斷
完整的展示從請求入口到下遊所有節點的呼叫拓撲關系,以及請求耗分時布資訊,是鏈路詳情的基本功能。為了定位關鍵透傳欄位遺失的情況,驗證鏈路上下文正確與否,平台鏈路詳情中還包含透傳欄位以及部份請求參數,使用者可以選擇全域視角或行程視角檢視呼叫棧,狀態參數幫助快速定位到異常節點。

在鏈路詳情頁可以檢視關聯的日誌資訊,實作與日誌聯動定位問題。

單個呼叫介面的詳情頁中,除了行程內呼叫棧,還有監控資訊聯動。
2)套用監控圖表
平台以套用視角為中心,利用Agent整合的監控數據采集,構建了監控圖表大盤,透過不同的後設資料分類,平台支持HTTP,RPC,訊息,資料庫,緩存等各個獨立視角的監控數據,以大盤曲線結合表格下鉆的形式展現。
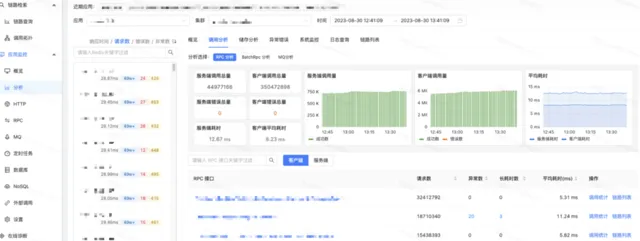
大盤圖表在Grafana基礎上,做了二次開發,支持同環比分析,多例項比較等實用的數據分析功能。
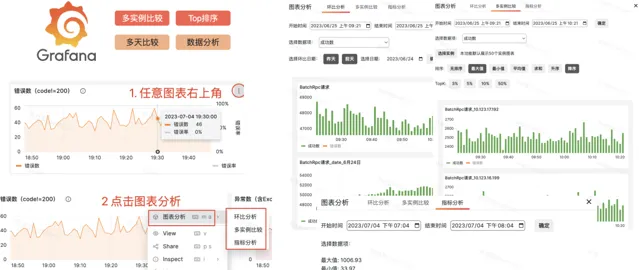
3)異常錯誤長耗時關聯分析
為了解決目前尋找異常監控點相關鏈路時,找不到可用鏈路,導致問題定位進展困難的問題。我們平台打通了監控數據與關聯的TraceId,讓使用方能夠快速的找到關聯鏈路,推進問題定位。平台提供了監控大盤圖表,以及相關的下鉆鏈路檢索,使用者可以在界面上定向檢索關聯的異常鏈路TraceId,每個TraceId下鉆後,會到達詳細的Trace詳情頁。
4)耗時請求Jstack追蹤
觸發了自動Jstack采集的方法,在平台上會給出提示文案。每個具體的Jstack采集結果,有詳細的堆疊資訊,關聯的Trace上下文資訊以及執行緒池資訊。除開自動Jstack采集,平台還支持主動下發Jstack請求,主動抓取現場。
5)Arthas線上診斷
平台還整合了Jstack,Arthas等使用頻率較高的定位工具。透過Agent連線,使用者可以在平台上使用工具直接對服務進行資訊采集。采集結果被收集後,平台提供更友好的展示和進一步分析的能力。
三、計畫總結
在計畫的開發學習過程中,我們積累沈澱了一些線上問題定位的方法論,總結了很多針對伺服端問題定位的流程與工具。我們希望能夠將這部份經驗透過產品的形式呈現出來,來幫助面對問題無從下手的同學,透過路徑引導快速得到問題資訊。對於有一定問題定位經驗同學,提供更加易用,更加高效定位工具,打通定位流程上的各個環節。最終達到快速定位發現線上問題,快速止血的目標。
當然,線上服務治理不是光靠單一平台就能完全覆蓋的,Pylon大平台下還提供了業務日誌、監控分析、告警治理、場景事件等多個子平台,來幫助我們更好地進行線上服務治理。我們會在後續的文章中,逐一介紹這些平台的建設實踐。
作者丨 碧海(蔣星韜)
來源丨公眾號: 網易雲音樂技術團隊 (ID: gh_e0a72742f973 )
dbaplus社群歡迎廣大技術人員投稿,投稿信箱: [email protected]












