
早在我加入 Urb-it 這家公司前,他們就決定使用 Kubernetes 作為雲原生戰略的基石。這一選擇背後有兩方面考慮:一是使用 Kubernetes 應對快速擴充套件的預期,二是利用它的容器編排功能為應用程式提供更動態、彈性和高效的環境。同時,Kubernetes 與我們的微服務架構非常契合。
早期決策
公司很早就決定選擇 Kubernetes,這一選擇受到質疑是合理的,因為初創公司(或任何公司)就要(對這一工具)產生深層依賴,同時需要學習大量相關的技術知識。除此之外,我們當時遇到過 Kubernetes 才能解決的問題嗎?
也許有人會說,我們可以在最初使用一個相當大的單體,直到擴充套件及其他問題越發凸顯,才轉向 Kubernetes(或其他工具)。並且,Kubernetes 當時仍處於早期開發階段。不過,我們下次再深入討論這個問題吧。
8 年生產經驗
我們在生產環境中執行 Kubernetes 已超過 8 年(每個環境都有單獨的集群),在此期間做過的決策有好有壞。有些錯誤僅是因為「運氣不好」,而有些錯誤則是因為我們部份(甚至可以說完全)沒能理解底層技術。Kubernetes 功能強大,但也具有復雜性。
在沒有任何大規模執行 Kubernetes 經驗的情況下,我們只能迎難而上。
從 AWS 上的自托管遷移到 Azure 上的托管(AKS)
最初幾年,我們在 AWS 上執行一個自管理集群。如果我沒記錯的話,我們最初沒有選擇使用 Azure Kubernetes Service(AKS)、Google Kubernetes Engine (GKE)、Amazon Elastic Kubernetes Service(EKS),是因為當時他們尚未提供官方的托管解決方案。正是在Amazon Web Services (AWS)自托管平台上,我們遭遇了 Urb-it 歷史上第一次也是最可怕的一次集群崩潰,稍後再詳述。
由於我們是小規模團隊,所以完全掌握所需的所有新功能極具挑戰性。同時,管理自托管集群需要持續關註及維護,這增加了我們的工作量。
當托管解決方案普遍可用時,我們花了些時間對比評估 AKS、GKE 和 EKS 。在我們看來,以上所有解決方案都比自己管理要好上數倍,而且我們能輕易預見遷移帶來的快速投資報酬。
當時,我們的平台 50% 是 .Net , 50% 是 Python,並且已經在使用 Azure Service Bus、Azure SQL Server 及其他 Azure 服務。因此,將集群遷移到 Azure 的好處不言而喻,我們不僅能更方便地整合使用這些服務,還可以利用 Azure 主幹網路基礎設施,節省因離開/進入外部網路和 VNET 相關的成本(在 AWS 和 Azure 混合設定的情況下,就無法避免這些成本)。此外,我們的許多工程師都熟悉 Azure 及其生態系,學習成本較低。
意外之喜是,在 AKS 上進行初始設定時,我們無需為控制平面節點(主節點)付費,節省了節點費用。
2018 年冬天,我們進行了遷移,盡管這些年在 AKS 上也遇到過問題,但我們並未後悔過這次遷移。
集群崩潰 #1
使用 AWS 進行自托管期間,我們經歷了一次大規模的集群崩潰,導致大部份系統和產品出現故障。根 CA 證書、etcd 證書和 API 伺服器證書全部過期,導致集群停止工作、無法管理。當時,kube-aws 提供的解決支持非常有限。雖然我們請來一位專家指導,但最終還是不得不從零開始重建整個集群。
我們以為每個 git 倉庫中都有所有制和 Helm 圖表,但出乎意料的是,並非所有服務都是如此。最重要的是,庫中沒有儲存建立集群的任何配置。我們與時間賽跑,重新建立集群並將我們所有服務及產品填充進去。其中有些服務需要重新制作 Helm 圖表,以建立缺失的配置。有時會出現Dev1 問 Dev2 的情況:「你還還記得這個服務應該有多少 CPU 或RAM,或者有哪些網路和埠存取許可權嗎?」更不用說記得什麽金鑰,它們已隨風而逝。
我們花了好幾天才重新啟動集群並將其執行起來。退一步說,這不是我們最驕傲的時刻。
得益於積極主動的溝通工作,我們使用了保持透明度、誠實的處理態度和客戶關系維系等對策,沒有失去任何業務或客戶。
集群崩潰 #2
你可能會猜:第二次崩潰原因不可能是證書造成的,你們一定會從第一次崩潰中吸取教訓,對嗎?沒錯,但也不完全對。
不幸的是,在重新建立崩潰 #1 的集群時,我們使用的 kube-aws 的特定版本出現了問題。在建立新群集時,它沒有將 etcd 證書的有效期設定為我們提供的有效期,而使用了一年的預設期限。因此,在第一次群集崩潰整整一年後,證書過期了,我們又經歷了一次集群崩潰。不過這一次恢復就容易多了,我們不必重建一切,但這依舊是一個地獄般的周末。
附註 1:其他公司也和我們一樣受到了這個漏洞的影響,但這對我們的客戶並沒有什麽幫助……
附註 2:我們原計劃在一年後更新所有證書,為了給自己留有余地,我們將過期時間設為兩年(如果我沒記錯的話)。因此,雖然我們計劃更新證書,但 bug 比我們早了一步。
自 2018 年以來,我們再也沒有遇到過集群崩潰的情況……希望我沒有烏鴉嘴。
經驗教訓
1.Kubernetes 很復雜
您需要任用對 Kubernetes 的基礎設施和營運方面感興趣並願意參與其中的工程師。
就我們而言,我們需要幾名工程師在日常工作之外研究 Kubernetes ,在必要時作為「首選專家」解決問題。如你所想,Kubernetes 特定任務的工作量各不相同,有時連著好幾周差不多無事可做,有時幾周需要保持高度註意力,比如集群升級期間。
將工作輪流分配給整個團隊是不可能的,這項技術太過復雜,無法隔一周在不同工作之間「反復橫跳」。當然,每個人都需要知道如何使用它(包括部署、偵錯等),但要在更具挑戰性的方面表現出色,專門的學習時間必不可少。此外,擁有一個有遠見、有集群發展戰略的領導者也很重要。
2.Kubernetes 證書
經歷過兩次證書過期導致的集群崩潰,因此(我們意識到)精通 Kubernetes 內部證書及其過期日期的詳細資訊至關重要。
3.讓 Kubernetes 和 Helm 保持更新
一旦落後,使用這兩項工具成本就會增加,也出現問題。我們總是等待幾個月才會升級到最新版本,以了解其他使用者會面臨什麽新版本問題。但即使保持更新版本,我們也會因為 Kubernetes 和 Helm 多樣的新版本(Kubernetes API 從 alfa 到 beta,beta 到 1.0 等)而面臨許多耗時的配置檔和圖表重寫工作。我知道Simon和Martin喜歡 Ingress 的所有變化。
4.集中式 Helm 圖表
說到 Helm 圖表,我們已經厭倦了每次版本變更都要更新全數超過七十個圖表,因此我們采用了一種更通用的「一圖統一所有」的方法。使用集中式 Helm 圖表有利有弊,但最終這種方法更符合我們的需求。
5.災難恢復計劃
我再三強調:確保在需要時有辦法重新建立集群。是的,你可以在使用者介面中點選來建立新的群集,但這種方法在大規模或時間緊急的情況下是行不通的。
有不同的方法來處理這個問題,從簡單的 shell 指令碼到更高級的方法,如使用 Terraform(或類似方法)。Crossplane 還可用於管理基礎設施即程式碼(IaC)等。對我們來說,由於團隊頻寬有限,我們選擇了儲存和使用 shell 指令碼。無論選擇哪種方法,都要確保不時測試流程,以確保在需要時可以重新建立集群。
6.備份金鑰
制定金鑰備份和儲存策略。如果你的集群消失了,所有金鑰都將遺失。相信我,我們親身經歷過這種情況,當你擁有多個不同的微服務和外部依賴關系時,需要花費大量時間才能重新恢復正常。
7.與供應商無關 VS「全部押進」
一開始,在遷移到 AKS 之後,我們試圖不讓集群與供應商繫結,這意味著我們將繼續使用其他服務進行容器登錄檔、身份驗證、金鑰庫等。我們的想法是,有朝一日我們可以輕松地遷移到另一個托管解決方案。雖然與供應商無關是個好主意,但對我們來說,機會成本很高。過了一段時間,我們決定全力開發與 AKS 相關的 Azure 產品,如容器登錄檔、安全掃描、身份驗證等。對我們來說,這改善了開發人員的體驗,簡化了安全性(使用 Azure Entra Id 進行集中式存取管理)等,從而加快了產品上市速度並降低了成本(產生了效益)。
8.客戶資源定義
是的,我們全面使用了 Azure 產品,但我們的指導原則是盡可能減少自訂資源定義,而是使用內建的 Kubernetes 資源。不過,我們也有一些例外,比如 Traefik,因為 Ingress API 並不能滿足我們的所有需求。
9.安全性
見下文。
10.可觀測性
見下文。
11.已知峰值期間的預縮放
即使用了自動縮放器,我們有時也會縮放得太慢。透過使用流量數據和常識(我們是一家物流公司,節假日會出現高峰),我們在高峰來臨前一天手動擴大了集群(ReplicaSet),然後在高峰來臨後一天縮容(慢慢縮小以應對可能出現的第二波高峰)。
12.集群內的無人機
我們在stage集群中保留了 Drone 構建系統,這樣做有好有壞。因為在同一集群中,易於擴充套件和使用;但如果同時構建太多,會消耗幾乎所有資源,導致 Kubernetes 急於啟動新節點。最好的解決方案可能是將其作為純 SaaS 解決方案,而不必擔心產品本身的托管和維護工作。
13.選擇正確的節點型別
選擇節點型別與具體情況密切相關,但根據節點型別,AKS 會保留約 10-30% 的可用記憶體(用於 AKS 內部服務)。因此,我們發現使用較少但較大的節點型別是有益的。此外,由於我們要在許多服務上執行 .Net,因此需要選擇具有高效、大容量 IO 的節點型別。(.Net經常向磁盤寫入JIT和日誌,如果這需要網路存取,速度就會變慢。我們還確保節點磁盤/緩存的大小至少與配置的節點磁盤總大小相同,以再次避免網路跳轉)。
14.預留例項
你可能會認為這種方法有點違背雲的靈活性,但對我們來說,將關鍵例項保留一兩年可以節省大量成本。在許多情況下,與「即用即付」方法相比,我們可以節省 50%-60%的成本,相當可觀。
15.k9s
對於想要比純粹的 kubectl 更高一層抽象的使用者來說, https://k9scli.io/ 是一個很好的工具。
可觀測性
1.監控
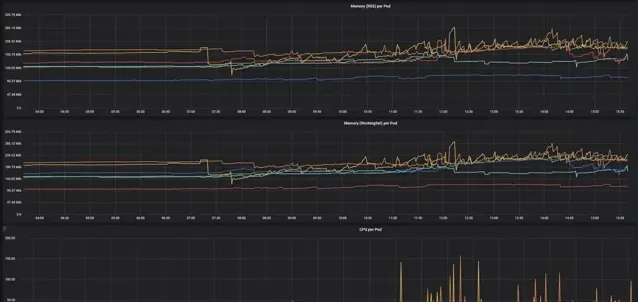
確保長期跟蹤記憶體、CPU 等的使用情況,以便觀察集群的執行情況,確定新功能是提高還是降低了集群效能。這樣能更容易地為不同的 pod 找到並設定「正確的」限制(找到正確的平衡點非常重要,因為如果記憶體耗盡,pod 就會被殺死)。
2.告警
完善告警系統需要一個過程,但最終我們將所有告警定向到 Slack 頻道。當集群未按預期執行或出現意外問題時,我們能便捷地收到資訊。

3.日誌記錄
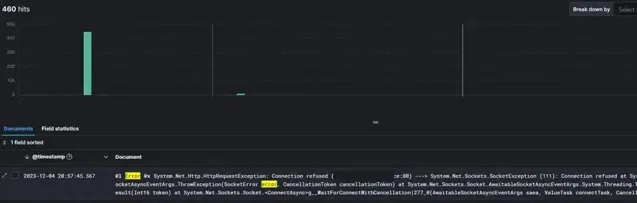
將所有日誌整合到一個地方,同時采用強大的跟蹤 ID 策略(例如 OpenTelemetry 或類似軟體),對於任何微服務架構都至關重要。我們花了兩三年時間才做到這一點。如果我們早點實施,就能節省大量時間。
安全性
Kubernetes 中的安全問題是一個龐大的話題,我強烈建議對其進行深入研究,以了解所有細微差別(例如,請參閱 NSA、CISA 釋出的【Kubernetes 加固指南】)。以下是我們的一些經驗要點,但請註意,這些內容並不完備。
1.存取控制
簡而言之,Kubernetes 預設限制並不過分。因此,我們投入了大量時間來收緊存取許可權,對 pod 和容器實施最小許可權原則。此外,由於存在特定漏洞,無許可權攻擊者有可能將其許可權升級為 root 許可權,從而規避 Linux 名稱空間限制,在某些情況下,甚至可以逃離容器,獲得主機節點上的 root 存取許可權。這絕非好事。
您應該設定唯讀根檔案系統、禁用服務帳戶令牌自動掛載、禁用許可權升級、放棄所有不必要的功能等等。在我們的具體設定中,我們使用 Azure Policy 和 Gatekeeper 來確保不會部署不安全的容器。
在 AKS 中的 Kubernetes 設定中,我們利用基於角色的存取控制(RBAC)的強大功能來進一步加強安全性和存取管理。
2.容器漏洞
有很多優質工具可以掃描和驗證容器以及 Kubernetes 的其他部份。我們使用 Azure Defender 和 Azure Defender for Containers 來滿足一些需求。
註:與其陷入「分析癱瘓」,即試圖找到一個完美的、擁有各種花哨功能的工具,不如先選擇工具,然後直接開始學習。
多年實踐的長期設定
1.部署
與其他許多人一樣,我們使用 Helm 來管理和簡化 Kubernetes 上部署和打包應用程式。由於我們很久以前就開始使用 Helm,而且最初是 .Net/Go/Java/Python/PHP 混合使用,所以重寫 Helm 圖表的次數多得我都記不清了。
2.可觀測性
我們開始使用 Loggly 和 FluentD 進行集中式日誌記錄,但幾年後,我們轉而使用 Elastic 和 Kibana(ELK 堆疊)。對我們來說,使用 Elastic 和 Kibana 更方便,因為它們的使用範圍更廣,而且在我們的設定中,它們的價格也更便宜。
3.容器登錄檔
我們最初使用的是 Quay,這是一款不錯的產品。但隨著向 Azure 遷移,使用 Azure 容器登錄檔變得很自然,因為它是整合的,因此對我們來說是更「原生」的解決方案。(隨後,我們還將容器置於 Azure Security Advisor 下)。
4.管道
從一開始,我們就使用 Drone 構建容器。剛開始時,支持容器和 Docker 的 CI 系統並不多,也不提供程式碼配置。多年來,Drone 為我們提供了良好的服務。Harness 收購 Drone 後,它變得有點混亂,但在我們屈服並遷移到高級版本後,我們擁有了所需的所有功能。
改變遊戲規則
過去幾年,Kubernetes 改變了我們的遊戲規則。它釋放出的功能讓我們能夠更高效地擴充套件(應對流量波動)、最佳化基礎設施成本、改善開發人員體驗、更輕松地測試新創意,從而大大縮短了新產品和服務的上市時間/盈利時間。
我們開始使用 Kubernetes 有點太早了,在我們尚未真正遇到它能解決的問題之前。但從長遠來看,尤其是最近幾年,它已被證明能為我們帶來巨大價值。
結語
回顧八年來的經歷,我們有很多故事可以分享,其中很多已經淡出記憶。我希望我們的組建過程、所犯的錯誤以及一路走來所汲取的經驗教訓對您有所幫助。
感謝閱讀。
特別感謝Matin、Simon和Niklas對本文提出的寶貴意見。
作者丨
Anders Jönsson
編譯丨onehunnit
來源丨 medium.com/@.anders/learnings-from-our-8-years-of-kubernetes-in-production-two-major-cluster-crashes-ditching-self-0257c09d36cd
*本文為dbaplus社群編譯整理,如需轉載請取得授權並標明出處! 歡迎廣大技術人員投稿,投稿信箱:[email protected]












