計畫簡介
Umi-OCR是一款免費、開源的離線OCR軟體,旨在為使用者提供快速、高效的文本辨識服務。它支持多種語言,能夠處理圖片、PDF文件,並具備批次辨識功能。此外,軟體還包括二維碼的掃描和生成,以及對浮水印和頁首頁尾的智慧排除,適用於個人和企業使用者。
掃碼加入交流群
獲得更多技術支持和交流

特點
· 免費:計畫程式碼完全開源且免費使用。
· 易用:解壓後直接使用,無需聯網,支持離線操作。
· 效率:配備高效的離線OCR引擎,支持多語言文本辨識。
· 靈活:提供多種使用方式,包括命令列和HTTP介面。
· 功能:整合了截圖文本辨識、批次處理、PDF檔辨識、二維碼處理及公式辨識等功能。
開始使用
下載連結在文章最後
軟體釋出包下載為 .7z 壓縮包或 .7z.exe 自解壓包。自解壓包可在沒有安裝壓縮軟體的電腦上,解壓檔。
本軟體無需安裝。解壓後,點選 Umi-OCR.exe 即可啟動程式。
界面語言
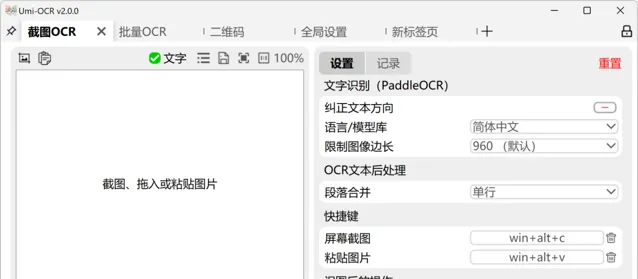
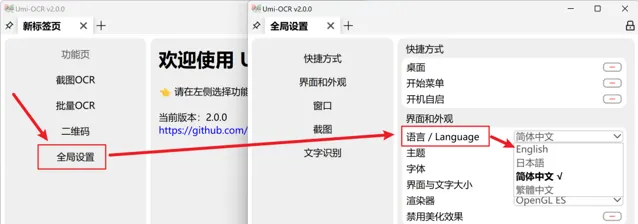
Umi-OCR支持多種界面語言,首次使用時會根據電腦系統設定自動選擇語言。如需手動更改語言,可在軟體的「全域設定」中找到「語言/Language」選項進行調整。
截圖OCR
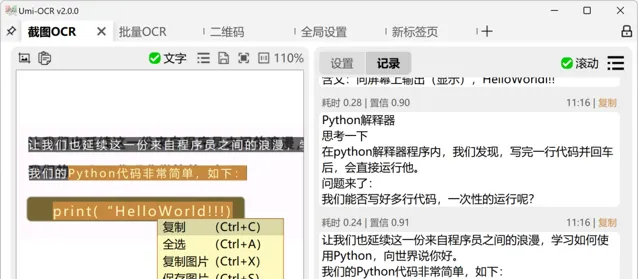
在Umi-OCR中,啟用軟體後可透過快捷鍵進行截圖並辨識圖中文字。軟體界面左側為圖片預覽區,支持滑鼠劃選文本復制。右側則為辨識記錄區,允許編輯和復制多個記錄。此外,Umi-OCR還支持從其他套用復制圖片後,直接貼上到軟體中進行文本辨識。
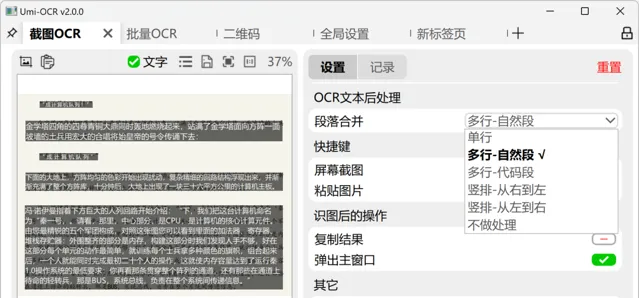
在Umi-OCR的文本後處理中,使用者可以選擇不同的排版解析方案以最佳化OCR結果,使文本更易於閱讀和套用。包括適應多欄或單欄布局的不同換行規則,如按自然段換行、總是換行、或無換行。特別的,還有針對程式碼截圖的排版保留選項,以及保持OCR引擎原始輸出的選擇。這些設定旨在滿足不同文本排版需求,同時支持橫排和豎排文本的自動處理。
批次OCR
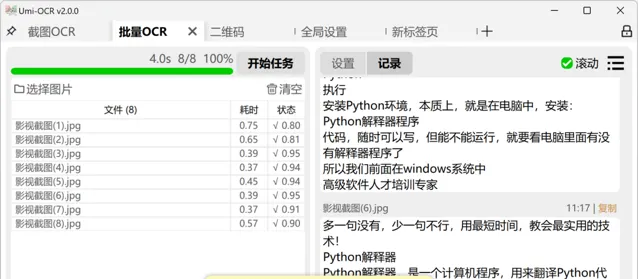
這個頁面允許使用者批次匯入本地圖片以進行辨識,並支持將辨識結果保存為多種檔格式,如txt、jsonl、md、csv等。它也提供文本後處理功能,用以整理OCR辨識後的文本排版和順序,同時支持設定忽略特定區域。此功能無匯入數量限制,支持一次性處理大量圖片,並且可設定在任務完成後自動關機或待機。
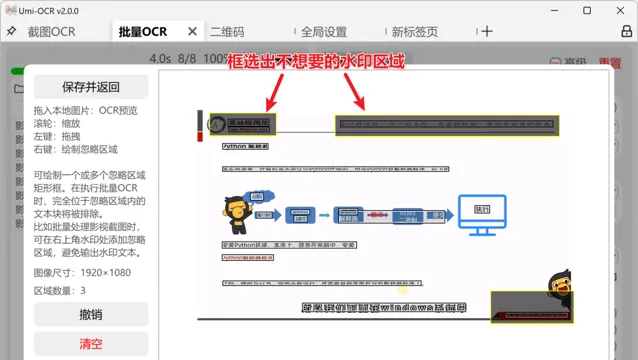
OCR文本後處理中的「忽略區域」是批次OCR功能的一部份,旨在排除不需要的文本,如浮水印或LOGO。使用者可以透過繪制矩形框來指定圖片中的忽略區域,以避免這些部份的文字幹擾辨識結果。設定時,確保矩形框覆蓋所有潛在的幹擾元素。
文件辨識
· 支持匯入 pdf, xps, epub, mobi, fb2, cbz 格式的檔。
· 對掃描件進行OCR,或提取原有文本。可輸出為 雙層可搜尋PDF 。
· 支持設定 忽略區域 ,可用於排除頁首頁尾的文字。
· 可設定任務完成後 自動關機/休眠 。
計畫連結
https://github.com/hiroi-sora/Umi-OCR
關註「 開源AI計畫落地 」公眾號











