最近,OpenAI 把自己的語音辨識計畫 Whisper 開源了,聲稱能把視訊和語音檔轉換成文字。
聽說效果能和科大訊飛那些收費產品一較高下,而且最妙的是,這玩意兒不需要 GPU,家用電腦就能跑!
我是個折騰愛好者,尤其對這種開源計畫興趣滿滿。官方文件固然詳細,但我這次打算走個捷徑,找到了一個基於 Whisper 的 web 服務計畫,直接用 Docker 部署,聽起來是不是很酷?
下載映像
在 Docker 裏搜尋 openai-whisper-asr-webservice,拉下第一個映像。
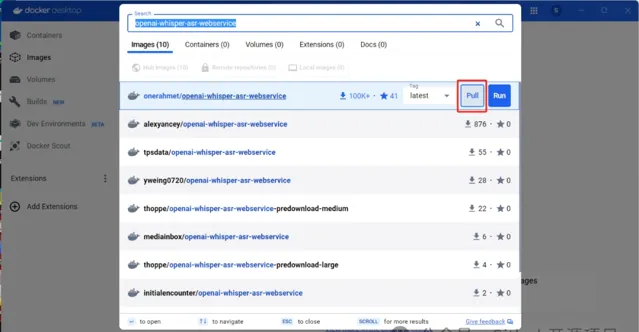
啟動服務
docker run -d -p 9000:9000 -e ASR_MODEL=base onerahmet/openai-whisper-asr-webservice:latest
執行完畢後,開啟瀏覽器存取 http://localhost:9000/,初次存取會下載模型,稍等片刻後,就能看到部署成功的頁面,簡單至極!
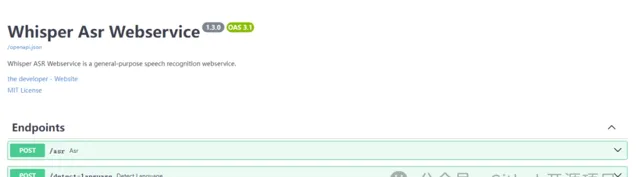
開始使用
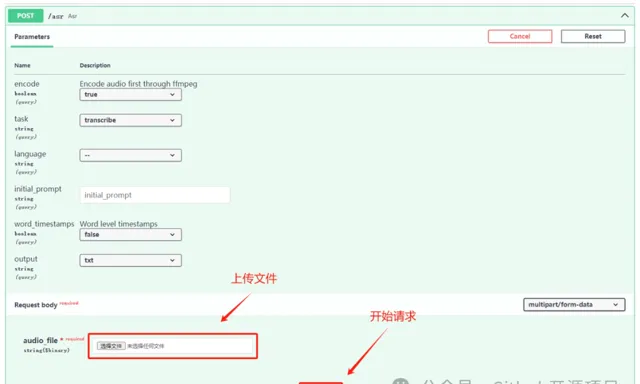
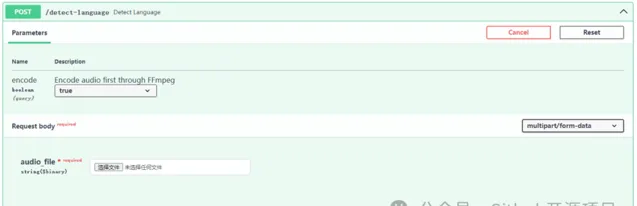
提供了兩個 HTTP 介面:語音辨識和語言檢測。語音辨識介面,上傳檔後轉換成文字;語言檢測介面,則是辨識上傳檔的語言型別。
音/視訊轉文字
試了下英文音訊,上傳後點選執行,一會兒工夫就看到了轉換結果。
語言檢測
還能檢測視訊或音訊檔裏的語言型別,這對於多語言檔也是非常友好的。
最後
用 Whisper,我在家裏就能把各種語音視訊檔變成文字,無論是制作字幕還是整理訪談記錄,都變得輕而易舉。最關鍵的是,這一切都是開源免費的,簡直太棒了!
而且,透過 Docker 部署這個 web 服務計畫,整個過程簡單到讓人驚訝。只要幾步操作,就能搭建起一個功能強大的語音辨識服務,這在我看來,無疑是開源世界的又一次偉大勝利。
由於有些小夥伴網路問題,導致下載不了,這裏我已經整理到網盤了。
連結地址: https://www.j301.cn/blog/github_ai_tool_whisper.html
點選下方公眾號,回復關鍵字: github , 獲取 Github開源計畫合集 !

點分享
點收藏
點點贊
點在看











