簡介
第一名方案主要由4個XGBoost模型(2個不同的標簽)以及2個GRU模型(2個不同模型)組成。
驗證策略
使用前500天數據進行訓練並且將剩余的時間用做驗證。
特征
county+datetime+data_block_id的組合特征。
fw_new_feature可以提升大致 0.1~0.2
# client_df
client_df = client_df.drop(["date"]).sort(["data_block_id"], descending=False)
df = df.join(client_df.select(["county", "is_business", "product_type", "data_block_id","eic_count","installed_capacity"]), how="left", on=["county", "is_business", "product_type", "data_block_id"])
# electricity
electricity_df = electricity_df.drop(["origin_date"]).rename({"forecast_date":"datetime"}).with_columns([(pl.col("datetime").str.to_datetime()+pl.duration(days=1)).alias("datetime"), (pl.col("euros_per_mwh").abs()+0.1).alias("euros_per_mwh"),])
df = df.join(electricity_df[["data_block_id","datetime","euros_per_mwh"]], how="left", on=["data_block_id","datetime"])
# fw_df
fw_df = fw_df.with_columns(
(pl.col("origin_datetime").str.to_datetime()+pl.duration(hours="hours_ahead")).alias("datetime"),
pl.col("latitude").cast(pl.datatypes.Float32).round(1),
pl.col("longitude").cast(pl.datatypes.Float32).round(1),
pl.col("data_block_id").cast(pl.datatypes.Int64),
).join(weather_station_to_county_mapping.drop(["county_name"]).with_columns(
pl.col("latitude").cast(pl.datatypes.Float32).round(1),
pl.col("longitude").cast(pl.datatypes.Float32).round(1),
), how="left",on=["longitude","latitude"]).drop(["longitude","latitude","origin_datetime"])
fw_df = fw_df.group_by(["county","datetime","data_block_id"]).agg([pl.mean(col).alias("fw_{}".format(col)) for col in forecast_weather_cols]).with_columns([pl.col("county").cast(pl.datatypes.Int64),
pl.col("data_block_id").cast(pl.datatypes.Int64),])
df = df.join(fw_df, how="left", on=["county","datetime","data_block_id"]).with_columns([(pl.col("installed_capacity")*pl.col("fw_surface_solar_radiation_downwards") / (pl.col("fw_temperature") + 273.15)).alias("fw_new_feature"),])
# hw_df
hw_df = hw_df.with_columns(
(pl.col("datetime").str.to_datetime()+pl.duration(days=1)).alias("datetime"),
pl.col("latitude").cast(pl.datatypes.Float32).round(1),
pl.col("longitude").cast(pl.datatypes.Float32).round(1),
pl.col("data_block_id").cast(pl.datatypes.Int64),
).join(weather_station_to_county_mapping.drop(["county_name"]).with_columns(
pl.col("latitude").cast(pl.datatypes.Float32).round(1),
pl.col("longitude").cast(pl.datatypes.Float32).round(1),
), how="left",on=["longitude","latitude"]).drop(["longitude","latitude"])
hw_df = hw_df.group_by(["county","datetime","data_block_id"]).agg([pl.mean(col).alias("hw_{}".format(col)) for col in historical_weather_cols]).with_columns([ pl.when(pl.col("datetime").dt.hour()>10).then(pl.col("datetime")+pl.duration(days=1)).otherwise(pl.col("datetime")).alias("datetime"),
pl.col("county").cast(pl.datatypes.Int64),
pl.col("data_block_id").cast(pl.datatypes.Int64),])
df = df.join(hw_df, how="left", on=["county","datetime","data_block_id"])
Target
(target-target_shift2)/installed_capacity.
target/installed_capacity.
df = df.with_columns([
pl.when(pl.col('target').shift(2).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('target').shift(2).over(['prediction_unit_id','hour'])).when(pl.col('target').shift(3).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('target').shift(3).over(['prediction_unit_id','hour'])).when(pl.col('target').shift(4).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('target').shift(4).over(['prediction_unit_id','hour'])).when(pl.col('target').shift(2).mean().over(['datetime']).is_null()).then(pl.col('target').mean()).otherwise(pl.col('target').shift(2).mean().over(['datetime'])).fill_null(0.0).cast(pl.Float32).alias('target_shift_tmp'),
pl.when(pl.col('data_block_id')<=1).then(pl.col('installed_capacity').shift(-2).over(['prediction_unit_id','hour'])).when(pl.col('installed_capacity').shift(1).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('installed_capacity').shift(1).over(['prediction_unit_id','hour'])).when(pl.col('installed_capacity').shift(2).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('installed_capacity').shift(2).over(['prediction_unit_id','hour'])).when(pl.col('installed_capacity').shift(3).over(['prediction_unit_id','hour']).is_not_null()).then(pl.col('installed_capacity').shift(3).over(['prediction_unit_id','hour'])).when(pl.col('installed_capacity').mean().over(['datetime']).is_null()).then(pl.col('installed_capacity').mean()).otherwise(pl.col('installed_capacity').mean().over(['datetime'])).cast(pl.Float32).alias('installed_capacity_tmp'),
])
df = df.with_columns([ pl.when(pl.col('installed_capacity').is_null()).then(pl.col('installed_capacity_tmp')).otherwise(pl.col('installed_capacity')).clip(10,None).cast(pl.Float32).alias('installed_capacity_tmp'), #clip(10,None)
]).with_columns([
pl.when(pl.col('installed_capacity_tmp')<2*pl.col('target_shift_tmp').abs()).then(2*pl.col('target_shift_tmp').abs()).otherwise(pl.col('installed_capacity_tmp')).cast(pl.Float32).alias('installed_capacity_tmp'),
])
df = df.with_columns([
((pl.col('target')-pl.col('target_shift_tmp')) / pl.col('installed_capacity_tmp')).alias('target2'),
(pl.col('target') / pl.col('installed_capacity_tmp')).alias('target3'),
])
模型
XGBoost
GRU模型,輸入的tensor大小為:(batch_size, 24 hours, 600 dense_feature_dim + 6*16 cat_feature_dim),輸出的tensor的shape為(batch_size, 24 hours),此處類別特征為:['county', 'product_type', 'hour', 'month', 'weekday', 'day'],NN模型可以將最終分數提升0.9。
線上學習策略
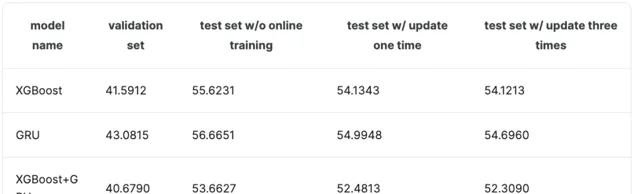
線上學習策略可以使用更多數據,這對public learderboard幫助較小,但private leaderboard可能會帶來更多的幫助。
參考文獻
https://www.kaggle.com/competitions/predict-energy-behavior-of-prosumers/discussion/472793
https://www.kaggle.com/competitions/predict-energy-behavior-of-prosumers/overview
作者:hyd











